

Qu'est-ce que l'algorithme MapReduce?
L'algorithme MapReduce est principalement inspiré du modèle de programmation fonctionnelle. Il est utilisé pour le traitement et la génération de mégadonnées. Ces ensembles de données peuvent être exécutés simultanément et distribués dans un cluster. Un programme MapReduce se compose principalement d'une procédure de carte et d'une méthode de réduction pour effectuer l'opération récapitulative comme le comptage ou la production de certains résultats. Le système MapReduce fonctionne sur des serveurs distribués qui fonctionnent en parallèle et gèrent toutes les communications entre différents systèmes. Le modèle est une stratégie spéciale de stratégie split-appliquer-combiner qui aide à l'analyse des données. Le mappage est effectué par la classe Mapper et réduit la tâche effectuée par la classe Reducer.
Comprendre l'algorithme MapReduce
L'algorithme MapReduce fonctionne principalement en trois étapes:
- Fonction de carte
- Fonction Shuffle
- Fonction de réduction
Discutons de chaque fonction et de ses responsabilités.
1. Fonction de carte
Il s'agit de la première étape de l'algorithme MapReduce. Il prend les ensembles de données et les distribue en sous-tâches plus petites. Cela se fait en deux étapes, le fractionnement et le mappage. Le fractionnement prend l'ensemble de données d'entrée et divise l'ensemble de données tandis que le mappage prend ces sous-ensembles de données et effectue l'action requise. La sortie de cette fonction est une paire clé-valeur.
2. Fonction de lecture aléatoire
Ceci est également connu sous le nom de fonction de combinaison et comprend la fusion et le tri. La fusion combine toutes les paires clé-valeur. Tous ces éléments auront les mêmes clés. Le tri prend l'entrée de l'étape de fusion et trie toutes les paires clé-valeur en utilisant les clés. Cette étape reviendra également aux paires clé-valeur. La sortie sera triée.
3. Réduire la fonction
Ceci est la dernière étape de cet algorithme. Il prend les paires clé-valeur du shuffle et réduit l'opération.
Comment les algorithmes MapReduce facilitent-ils le travail?
Les systèmes de bases de données relationnelles disposent d'un serveur centralisé qui aide au stockage et au traitement des données. Il s'agissait généralement de systèmes centralisés. Lorsque plusieurs fichiers apparaissent dans l'image, le traitement est fastidieux et crée un goulot d'étranglement lors du traitement de plusieurs fichiers. MapReduce mappe l'ensemble de données et convertit l'ensemble de données où toutes les données sont divisées en tuples et la tâche de réduction prendra la sortie de cette étape et combinera ces tuples de données dans les ensembles plus petits. Il fonctionne en différentes phases et crée des paires clé-valeur qui peuvent être réparties sur différents systèmes.
Que pouvez-vous faire avec les algorithmes MapReduce?
MapReduce peut être utilisé avec une variété d'applications. Il peut être utilisé pour la recherche basée sur des modèles distribués, le tri distribué, l'inversion de graphique de lien Web, les statistiques de journal d'accès Web. Il peut également aider à créer et à travailler sur plusieurs clusters, grilles de bureau, environnements informatiques volontaires. On peut également créer des environnements cloud dynamiques, des environnements mobiles et également des environnements informatiques hautes performances. Google a fait usage de MapReduce qui régénère Google Index du World Wide Web. En l'utilisant, les anciens programmes ad hoc sont mis à jour et ils ont exécuté différents types d'analyses. Il a également intégré les résultats de la recherche en direct sans reconstruire l'index complet. Toutes les entrées et sorties sont stockées dans le système de fichiers distribué. Les données transitoires sont stockées sur un disque local.
Utilisation de l'algorithme MapReduce
Pour travailler avec l'algorithme MapReduce, vous devez connaître le processus complet de son fonctionnement. Les données ingérées passent par les étapes suivantes:
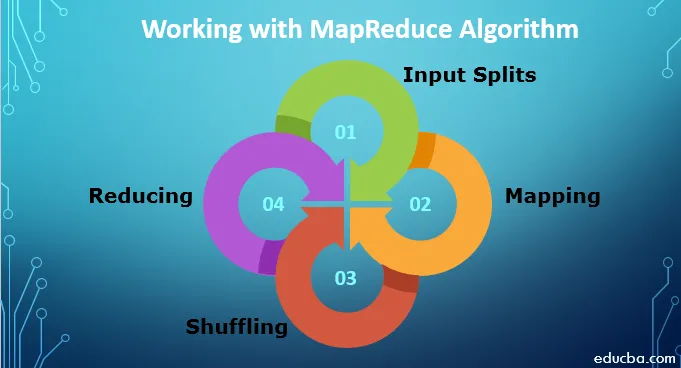
1. Séparations d'entrée: toutes les données d'entrée qui viennent au travail MapReduce sont divisées en morceaux égaux appelés divisions d'entrée. C'est un morceau d'entrée qui peut être consommé par n'importe quel mappeur.
2. Cartographie: une fois que les données sont divisées en morceaux, elles passent par la phase de cartographie dans le programme de réduction de carte. Ces données divisées sont transmises à la fonction de mappage qui produit différentes valeurs de sortie.
3. Mélange: Une fois le mappage effectué, les données sont envoyées à cette phase. Son travail consiste à fusionner les enregistrements requis de la phase précédente.
4. Réduction: dans cette phase, la sortie de la phase de brassage est agrégée. Dans cette phase, toutes les valeurs sont mélangées et regroupées par agrégation de sorte qu'elle renvoie une seule valeur de sortie. Il crée un résumé de l'ensemble de données complet.
Avantages de l'algorithme MapReduce
Les applications qui utilisent MapReduce présentent les avantages ci-dessous:
- Ils ont été dotés d'une convergence et de bonnes performances de généralisation.
- Les données peuvent être traitées en utilisant des applications gourmandes en données.
- Il offre une évolutivité élevée.
- Compter toutes les occurrences de chaque mot est facile et dispose d'une énorme collection de documents.
- Un outil générique peut être utilisé pour rechercher un outil dans de nombreuses analyses de données.
- Il offre un temps d'équilibrage de charge dans les grands clusters.
- Il aide également dans le processus d'extraction des contextes de localisation de l'utilisateur, de situations, etc.
- Il peut accéder rapidement à de larges échantillons de répondants.
Pourquoi devrions-nous utiliser l'algorithme MapReduce?
MapReduce est une application utilisée pour le traitement d'énormes ensembles de données. Ces jeux de données peuvent être traités en parallèle. MapReduce peut potentiellement créer de grands ensembles de données et un grand nombre de nœuds. Ces grands ensembles de données sont stockés sur HDFS, ce qui facilite l'analyse des données. Il peut traiter tout type de données telles que structurées, non structurées ou semi-structurées.
Pourquoi avons-nous besoin de l'algorithme MapReduce?
MapReduce se développe rapidement et aide au calcul parallèle. Il aide à déterminer le prix des produits et à générer les profits les plus élevés. Il aide également à prévoir et à recommander l'analyse. Il permet aux programmeurs d'exécuter des modèles sur différents ensembles de données et utilise des techniques statistiques avancées et des techniques d'apprentissage automatique qui aident à prévoir les données. Il filtre et envoie les données à différents nœuds du cluster et fonctionne selon la fonction de mappage et de réduction.
Comment cette technologie vous aidera dans la croissance de carrière?
Hadoop est parmi les emplois les plus recherchés de nos jours. Il accélère le rythme et l'opportunité qui grandit très vite dans ce domaine. Il va y avoir encore un boom dans ce domaine. Les professionnels de l'informatique qui travaillent à Java ont un avantage car ce sont les personnes les plus recherchées. En outre, les développeurs, les architectes de données, les entrepôts de données et les professionnels de la BI peuvent retirer d'énormes salaires en apprenant cette technologie.
Conclusion
MapReduce est la base du framework Hadoop. En apprenant cela, vous aurez sûrement accès au marché de l'analyse de données. Vous pouvez l'apprendre à fond et savoir à quel point de grands ensembles de données sont traités et comment cette technologie modifie le traitement et le stockage des données.
Articles recommandés
Ceci est un guide des algorithmes MapReduce. Nous discutons ici du concept, de la compréhension, du travail, des besoins, des avantages et de la croissance de carrière. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Questions d'entretiens chez MapReduce
- Qu'est-ce que MapReduce dans Hadoop?
- Comment fonctionne MapReduce?
- Qu'est-ce que MapReduce?
- Différences entre Hadoop et MapReduce
- Différentes opérations liées aux tuples