
Différence entre l'apprentissage automatique et l'analyse prédictive
L'apprentissage automatique est un domaine de l'informatique, qui grandit et bondit de nos jours. Les progrès récents dans les technologies matérielles qui ont entraîné une augmentation massive de la puissance de calcul tels que les GPU (unités de traitement graphique) et les progrès dans les réseaux de neurones, l'apprentissage automatique est devenu un mot à la mode. Essentiellement, en utilisant des techniques d'apprentissage automatique, nous pouvons construire des algorithmes pour extraire des données et en voir des informations cachées importantes. L'analyse prédictive fait également partie du domaine de l'apprentissage automatique qui est limité pour prédire les résultats futurs à partir de données basées sur des modèles précédents. Alors que l'analyse prédictive est utilisée depuis plus de deux décennies principalement dans le secteur bancaire et financier, l'application du machine learning a pris de l'importance ces derniers temps avec des algorithmes tels que la détection d'objets à partir d'images, la classification de texte et les systèmes de recommandation.
Apprentissage automatique
L'apprentissage automatique utilise en interne les statistiques, les mathématiques et les principes fondamentaux de l'informatique pour créer une logique pour les algorithmes qui peuvent effectuer la classification, la prédiction et l'optimisation en temps réel ainsi qu'en mode batch. La classification et la régression sont deux classes principales d'un problème sous apprentissage automatique. Comprenons à la fois le Machine Learning et Predictive Analytics.
Classification
Sous ces compartiments d'un problème, nous avons tendance à classer un objet en fonction de ses diverses propriétés en une ou plusieurs classes. Par exemple, classer un client d'une banque pour être éligible à un prêt immobilier ou non en fonction de son historique de crédit. Habituellement, nous aurions des données transactionnelles disponibles pour le client, telles que son âge, son revenu, sa formation, son expérience de travail, l'industrie dans laquelle il travaille, le nombre de personnes à charge, les dépenses mensuelles, les prêts antérieurs le cas échéant, ses habitudes de dépenses, ses antécédents de crédit, etc. . et sur la base de ces informations, nous aurions tendance à calculer s'il devrait recevoir un prêt ou non.
Il existe de nombreux algorithmes d'apprentissage automatique standard qui sont utilisés pour résoudre le problème de classification. La régression logistique est l'une de ces méthodes, probablement la plus utilisée et la plus connue, également la plus ancienne. En dehors de cela, nous avons également certains des modèles les plus avancés et les plus compliqués, allant de l'arbre de décision à la forêt aléatoire, AdaBoost, XP boost, les machines à vecteurs de support, le naïf baize et le réseau de neurones. Depuis les deux dernières années, le deep learning est au premier plan. Généralement, le réseau neuronal et l'apprentissage en profondeur sont utilisés pour classer les images. S'il existe des centaines de milliers d'images de chats et de chiens et que vous souhaitez écrire un code qui peut séparer automatiquement les images de chats et de chiens, vous pouvez opter pour des méthodes d'apprentissage en profondeur comme un réseau de neurones convolutionnels. Torch, cafe, sensor flow, etc. sont quelques-unes des bibliothèques populaires en python pour faire du deep learning.
Pour mesurer la précision des modèles de régression, des paramètres comme le taux de faux positifs, le taux de faux négatifs, la sensibilité, etc. sont utilisés.
Régression
La régression est une autre classe de problèmes en apprentissage automatique où nous essayons de prédire la valeur continue d'une variable au lieu d'une classe contrairement aux problèmes de classification. Les techniques de régression sont généralement utilisées pour prédire le cours d'une action, le prix de vente d'une maison ou d'une voiture, la demande d'un certain article, etc. Lorsque des propriétés de séries chronologiques entrent également en jeu, les problèmes de régression deviennent très intéressants à résoudre. La régression linéaire avec le moindre carré ordinaire est l'un des algorithmes classiques d'apprentissage automatique dans ce domaine. Pour le modèle basé sur des séries chronologiques, ARIMA, la moyenne mobile exponentielle, la moyenne mobile pondérée et la moyenne mobile simple sont utilisées.
Pour mesurer la précision des modèles de régression, des mesures telles que l'erreur quadratique moyenne, l'erreur quadratique moyenne absolue, l'erreur quadratique de mesure racine, etc. sont utilisées.
Analyses prédictives
Il existe certains domaines de chevauchement entre l'apprentissage automatique et l'analyse prédictive. Alors que les techniques courantes comme la logistique et la régression linéaire relèvent à la fois de l'apprentissage automatique et de l'analyse prédictive, les algorithmes avancés comme un arbre de décision, une forêt aléatoire, etc. sont essentiellement des apprentissages automatiques. Dans l'analyse prédictive, le but des problèmes reste très étroit lorsque l'intention est de calculer la valeur d'une variable particulière à un moment futur. L'analyse prédictive est fortement chargée de statistiques tandis que l'apprentissage automatique est davantage un mélange de statistiques, de programmation et de mathématiques. Un analyste prédictif typique passe son temps à calculer le carré t, les statistiques f, Innova, le chi carré ou le moindre carré ordinaire. Des questions comme si les données sont normalement distribuées ou biaisées, si la distribution t de l'élève doit être utilisée ou si la courbe des cloches est utilisée, si l'alpha doit être pris à 5% ou 10%, les bug tout le temps. Ils recherchent le diable dans les détails. Un ingénieur en apprentissage automatique ne se soucie pas de bon nombre de ces problèmes. Leur mal de tête est complètement différent, ils se retrouvent coincés sur l'amélioration de la précision, la minimisation des taux de faux positifs, la gestion des valeurs aberrantes, la normalisation de la plage ou la validation du pli k.
Un analyste prédictif utilise principalement des outils comme Excel. Le scénario ou la recherche de buts sont leur favori. Ils utilisent parfois VBA ou des micros et n'écrivent pratiquement pas de code volumineux. Un ingénieur en apprentissage automatique passe tout son temps à écrire du code compliqué au-delà de la compréhension commune, il utilise des outils comme R, Python, Saas. La programmation est leur travail majeur, corriger les bugs et tester les différents paysages au quotidien.
Ces différences entraînent également une différence majeure dans leur demande et leur salaire. Alors que les analystes prédictifs le sont hier, le machine learning est l'avenir. Un ingénieur en apprentissage automatique ou un scientifique des données (comme on l'appelle généralement ces jours-ci) sont payés 60 à 80% de plus qu'un ingénieur logiciel ou un analyste prédictif typique, et ils sont le principal moteur du monde technologique d'aujourd'hui. Uber, Amazon et maintenant les voitures autonomes sont également possibles grâce à elles.
Comparaison directe entre l'apprentissage automatique et l'analyse prédictive (infographie)
Ci-dessous se trouve le top 7 de la comparaison entre l'apprentissage automatique et l'analyse prédictive
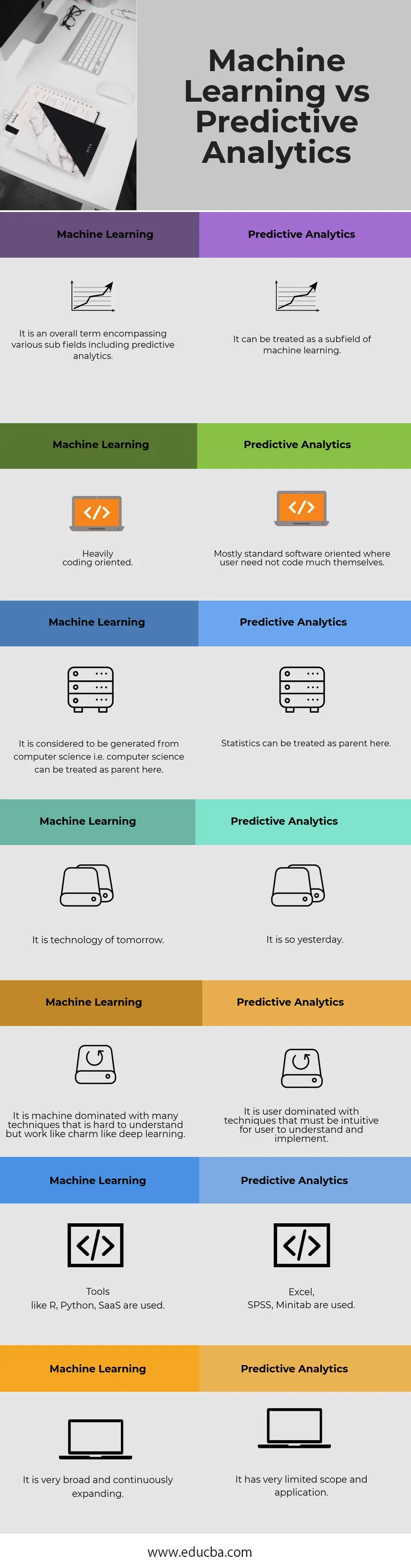
Tableau de comparaison de l'apprentissage automatique et de l'analyse prédictive
Vous trouverez ci-dessous l'explication détaillée de Machine Learning vs Predictive Analytics
| Apprentissage automatique | Analyses prédictives |
| Il s'agit d'un terme global englobant divers sous-domaines, y compris l'analyse prédictive. | Il peut être traité comme un sous-domaine de l'apprentissage automatique. |
| Très orienté codage. | Généralement orienté logiciel où un utilisateur n'a pas besoin de beaucoup coder lui-même |
| Il est considéré comme généré par l'informatique, c'est-à-dire que l'informatique peut être considérée comme le parent ici. | Les statistiques peuvent être traitées ici comme un parent. |
| C'est la technologie de demain. | Il en est ainsi hier. |
| C'est une machine dominée par de nombreuses techniques difficiles à comprendre mais qui fonctionnent comme par enchantement comme l'apprentissage en profondeur. | Il est dominé par l'utilisateur avec des techniques qui doivent être intuitives pour qu'un utilisateur les comprenne et les implémente. |
| Des outils comme R, Python, SaaS sont utilisés. | Excel, SPSS, Minitab sont utilisés. |
| Il est très large et en constante expansion. | Son champ d'application et son application sont très limités. |
Conclusion - Apprentissage automatique vs analyse prédictive
D'après la discussion ci-dessus sur l'apprentissage automatique et l'analyse prédictive, il est clair que l'analyse prédictive est essentiellement un sous-domaine de l'apprentissage automatique. L'apprentissage automatique est plus polyvalent et est capable de résoudre un large éventail de problèmes.
Article recommandé
Cela a été un guide pour l'apprentissage automatique vs l'analyse prédictive, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Apprenez le Big Data contre l'apprentissage automatique
- Différence entre la science des données et l'apprentissage automatique
- Comparaison entre l'analyse prédictive et la science des données
- Data Analytics vs Predictive Analytics - lequel est utile