

Introduction à l'exploration de données
Il s'agit d'une méthode d'exploration de données utilisée pour placer des éléments de données dans leurs groupes similaires. Le cluster est la procédure de division des objets de données en sous-classes. La qualité du clustering dépend de la méthode que nous avons utilisée. Le clustering est également appelé segmentation des données, car les grands groupes de données sont divisés par leur similitude.
Qu'est-ce que le clustering dans l'exploration de données?
Le clustering est le regroupement d'objets spécifiques en fonction de leurs caractéristiques et de leurs similitudes. Quant à l'exploration de données, cette méthodologie divise les données les mieux adaptées à l'analyse souhaitée à l'aide d'un algorithme de jointure spécial. Cette analyse permet à un objet de ne pas faire partie ou strictement partie d'un cluster, ce qu'on appelle le partitionnement dur de ce type. Cependant, les partitions lisses suggèrent que chaque objet du même degré appartient à un cluster. Des divisions plus spécifiques peuvent être créées comme des objets de plusieurs clusters, un seul cluster peut être forcé de participer ou même des arbres hiérarchiques peuvent être construits dans des relations de groupe. Ce système de fichiers peut être mis en place de différentes manières en fonction de différents modèles. Ces algorithmes distincts s'appliquent à chaque modèle, en distinguant leurs propriétés ainsi que leurs résultats. Un bon algorithme de clustering est capable d'identifier le cluster indépendamment de la forme du cluster. Il existe 3 étapes de base de l'algorithme de clustering, comme indiqué ci-dessous
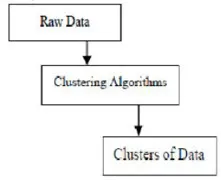
Algorithmes de clustering dans l'exploration de données
Selon les modèles de cluster récemment décrits, de nombreux clusters peuvent être utilisés pour partitionner des informations en un ensemble de données. Il faut dire que chaque méthode a ses avantages et ses inconvénients. La sélection d'un algorithme dépend des propriétés et de la nature de l'ensemble de données.
Les méthodes de clustering pour l'exploration de données peuvent être présentées comme ci-dessous
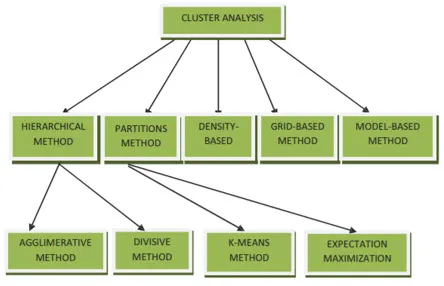
- Méthode basée sur le partitionnement
- Méthode basée sur la densité
- Méthode basée sur les centroïdes
- Méthode hiérarchique
- Méthode basée sur une grille
- Méthode basée sur un modèle
1. Méthode basée sur le partitionnement
L'algorithme de partition divise les données en plusieurs sous-ensembles.
Supposons que l'algorithme de partitionnement crée une partition de données car k et n si des objets sont présents dans la base de données. Par conséquent, chaque partition sera représentée par k ≤ n.
Cela donne une idée que la classification des données est en k groupes, ce qui peut être montré ci-dessous
La figure 1 montre les points d'origine du clustering

La figure 2 montre le clustering de partition après l'application d'un algorithme
Cela indique que chaque groupe a au moins un objet, ainsi que chaque objet, doit appartenir à exactement un groupe.
2. Méthode basée sur la densité
Ces algorithmes produisent des grappes à un emplacement déterminé en fonction de la forte densité de participants aux ensembles de données. Il agrège une certaine notion de plage pour les membres du groupe en grappes à un niveau standard de densité. De tels processus peuvent moins bien détecter les surfaces du groupe.
3. Méthode basée sur les centroïdes
Presque chaque cluster est référencé par un vecteur de valeurs dans ce type de technique de regroupement os. Par rapport aux autres clusters, chaque objet fait partie du cluster avec une différence de valeur minimale. Le nombre de clusters doit être prédéfini, et c'est le plus gros problème d'algorithme de ce type. Cette méthodologie est la plus proche du sujet de l'identification et est largement utilisée pour les problèmes d'optimisation.
4. Méthode hiérarchique
La méthode créera une décomposition hiérarchique d'un ensemble donné d'objets de données. Sur la base de la formation de la décomposition hiérarchique, nous pouvons classer les méthodes hiérarchiques. Cette méthode est donnée comme suit
- Approche agglomérative
- Approche de division
L'approche agglomérative est également connue sous le nom d'approche par bouton. Ici, nous commençons par chaque objet qui constitue un groupe distinct. Il continue de fusionner des objets ou des groupes rapprochés
L'approche de division est également connue sous le nom d'approche descendante. Nous commençons par tous les objets du même cluster. Cette méthode est rigide, c'est-à-dire qu'elle ne peut jamais être annulée une fois la fusion ou la division terminée.
5. Méthode basée sur une grille
Les méthodes basées sur une grille fonctionnent dans l'espace objet au lieu de diviser les données en grille. La grille est divisée en fonction des caractéristiques des données. En utilisant cette méthode, les données non numériques sont faciles à gérer. L'ordre des données n'affecte pas le partitionnement de la grille. Un avantage important d'un modèle basé sur une grille, il offre une vitesse d'exécution plus rapide.
Les avantages du clustering hiérarchique sont les suivants
- Il est applicable à tout type d'attribut.
- Il offre une flexibilité liée au niveau de granularité.
6. Méthode basée sur un modèle
Cette méthode utilise un modèle hypothétique basé sur la distribution de probabilité. En regroupant la fonction de densité, cette méthode localise les clusters. Il reflète la distribution spatiale des points de données.
Application du clustering dans l'exploration de données
Le clustering peut aider dans de nombreux domaines tels que la biologie, les plantes et les animaux classés par leurs propriétés ainsi que dans le marketing.Le clustering aidera à identifier les clients d'un certain dossier client avec une conduite similaire. Dans de nombreuses applications, telles que les études de marché, la reconnaissance de formes, le traitement de données et d'images, l'analyse de clustering est utilisée en grand nombre. Le clustering peut également aider les annonceurs de leur clientèle à trouver différents groupes. Et leurs groupes de clients peuvent être définis en achetant des modèles. En biologie, il est utilisé pour la détermination des taxonomies végétales et animales, pour la catégorisation de gènes ayant une fonctionnalité similaire et pour un aperçu des structures inhérentes à la population. Dans une base de données d'observation de la Terre, le regroupement permet également de trouver plus facilement des zones d'utilisation similaire dans le sol. Il aide à identifier les groupes de maisons et d'appartements par type, valeur et destination des maisons. Le regroupement de documents sur le Web est également utile pour la découverte d'informations. L'analyse de cluster est un outil pour obtenir un aperçu de la distribution des données pour observer les caractéristiques de chaque cluster en tant que fonction d'exploration de données.
Conclusion
Le clustering est important dans l'exploration de données et son analyse. Dans cet article, nous avons vu comment le clustering peut être fait en appliquant divers algorithmes de clustering ainsi que son application dans la vie réelle.
Article recommandé
Cela a été un guide sur ce qu'est le clustering dans l'exploration de données. Ici, nous avons discuté des concepts, de la définition, des fonctionnalités et de l'application du clustering dans l'exploration de données. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Qu'est-ce que le traitement des données?
- Comment devenir analyste de données?
- Qu'est-ce que l'injection SQL?
- Définition de qu'est-ce que SQL Server?
- Présentation de l'architecture d'exploration de données
- Clustering dans l'apprentissage automatique
- Algorithme de clustering hiérarchique
- Regroupement hiérarchique | Clustering Agglomératif & Diviseur