

Introduction au tri par insertion en JavaScript
Le tri est l'un des concepts importants que les programmeurs apprennent pour commencer leur voyage en informatique quel que soit le langage de programmation choisi pour apprendre. Le tri nous aide à localiser les données cibles que nous voulons rechercher d'une manière plus rapide et pratique, en les triant dans l'ordre croissant ou décroissant.
Les algorithmes de tri sont utilisés pour réorganiser les éléments, où un élément peut être un nombre ou une chaîne. Il existe de nombreux types d'algorithmes de tri en fonction de leur méthode de tri et de l'approche qu'ils suivent pour trier les éléments, et chaque type a ses avantages et ses inconvénients.
Dans ce blog, nous nous concentrerons sur le tri par insertion, un tri commun facile à comprendre et à mettre en œuvre.
Qu'est-ce que le tri par insertion en JavaScript?
Le tri par insertion est un algorithme simple et facile à comprendre qui fonctionne mieux avec une petite liste de données en triant chaque élément de la liste de données un par un de gauche à droite. Il est également connu sous le nom de tri de comparaison où il compare la valeur actuelle avec les autres valeurs de la même liste de données en cours de tri. Il suit une approche itérative pour placer chaque élément dans le bon ordre dans la liste de données.
Plus un algorithme met de temps à trier, ses performances sont jugées mauvaises et doivent envisager un autre algorithme pour trier les données. Le tri par insertion a une complexité temporelle de O (n²) ou exécute un temps quadratique pour trier la liste de données dans le pire des cas. Ce n'est généralement pas très efficace et ne doit pas être utilisé pour les grandes listes. Cependant, il surpasse généralement les algorithmes avancés tels que le tri rapide ou le fusionnement sur des listes plus petites.
Le tri par insertion est la plupart du temps plus efficace que les autres algorithmes de tri quadratique tels que le tri à bulles ou le tri par sélection. Son meilleur scénario, le temps est O (n), ou linéaire, ce qui se produit si le tableau d'entrée est déjà trié. En moyenne, le temps d'exécution du tri par insertion est toujours quadratique.
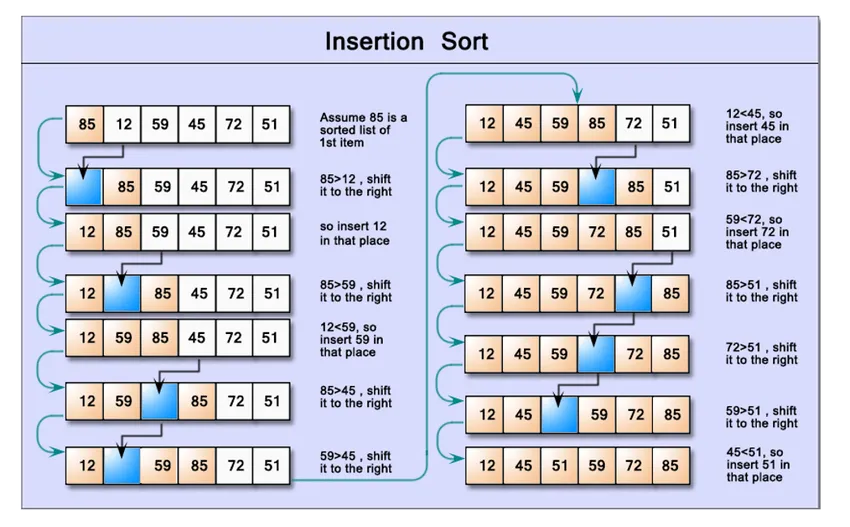
Dans l'exemple ci-dessous, nous aurons une approche de haut niveau facile pour trier les données stockées dans une structure de données de tableau et utiliser sa méthode de tri pour trier les données sans implémenter d'algorithmes.
Exemple - Algorithme de tri par insertion
Code:
// Declaring unsorted data and storing it in array data structure
var dataArray = (96, 5, 42, 1, 6, 37, 21) // Function - Insertion Sort Algo.
function insertSort(unsortedData) (
for (let i = 1; i < unsortedData.length; i++) (
let current = unsortedData(i);
let j;
for(j=i-1; j >= 0 && unsortedData(j) > current;j--) (
unsortedData(j + 1) = unsortedData(j) )
unsortedData(j + 1) = current;
)
return unsortedData;
)
// print sorted array
console.log(insertSort(dataArray));
Production:
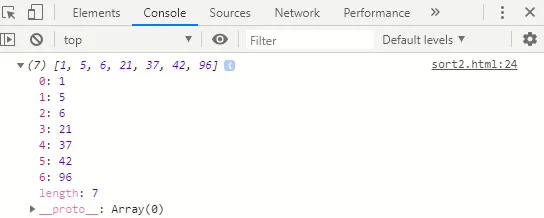
Explication: Dans l'algorithme, nous avons implémenté 2 pour les boucles, la boucle externe pour itérer sur les éléments du tableau et la boucle interne pour est utilisée pour trier les éléments du tableau dans l'ordre croissant de leur valeur. La variable actuelle contient la valeur actuelle du tableau et la variable j est définie sur une valeur inférieure à la position d'index actuelle du tableau. Nous vérifions si l'élément courant (courant) est plus petit que la valeur du tableau à la j ème position (unsortedData (j) ) et si c'est vrai, nous trions ces valeurs.
Itération 1 - actuelle (96): (96, 5, 42, 1, 6, 37, 21)
Itération 2 - courant (5): (5, 96, 42, 1, 6, 37, 21)
Itération 3 - courant (42): (5, 42, 96, 1, 6, 37, 21)
Itération 4 - courant (1): (1, 5, 42, 96, 6, 37, 21)
Itération 5 - courant (6): (1, 5, 6, 42, 96, 37, 21)
Itération 6 - actuelle (37): (1, 5, 6, 37, 42, 96, 21)
Itération 7 - actuelle (21): (1, 5, 6, 21, 37, 42, 96)
L'itération externe pour la boucle commence à la 1ère position d'index car nous voulons déplacer le plus petit élément vers la gauche, nous comparons donc si l'élément actuel est plus petit que les éléments sur son côté gauche.
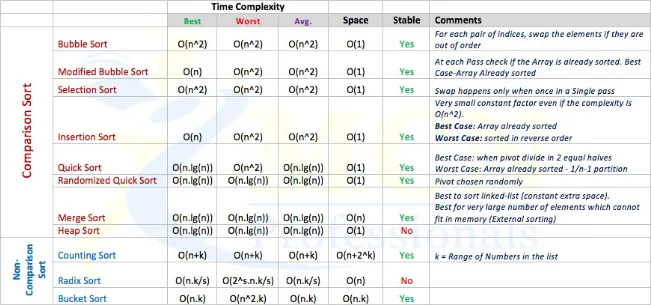
Types de tri
Les types d'algorithmes utilisés pour trier les données englobent les concepts ou idées suivants dans leur approche du tri des données:
- Comparaison versus stratégies non basées sur la comparaison,
- Implémentation itérative versus récursive,
- Paradigme diviser pour mieux régner (ceci ou cela),
- Approche aléatoire.
Prenons quelques exemples:
1. Le tri par fusion utilise une approche de division et de conquête pour trier les éléments d'un tableau.
2. Tri par insertion, le tri par bulles est un tri basé sur la comparaison.
Lorsque les données sont triées, il devient plus facile de trouver une solution optimale à des problèmes complexes. par exemple,
- Recherche d'une valeur spécifique,
- Trouver la valeur minimale ou maximale,
- Tester l'unicité et supprimer les doublons,
- Compter combien de fois une valeur spécifique est apparue, etc.
Conclusion
Dans cet article, nous avons passé en revue la définition du tri par insertion et sa complexité temporelle et divers autres types d'algorithmes de tri en fonction de leur approche. L'étude de divers algorithmes de tri nous aide à identifier celui qui convient le mieux dans certaines circonstances ou à utiliser des cas qui nous aident à trier les données plus rapidement.
Articles recommandés
Ceci est un guide pour le tri par insertion en JavaScript. Nous discutons ici de ce qu'est le tri par insertion en javascript et de ses types avec un exemple. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Modèles en JavaScript
- Déclaration de cas en JavaScript
- Instructions conditionnelles en JavaScript
- Objets JavaScript
- Différents types de boucles avec ses avantages