

Introduction à Apache Flume
Apache Flume est Data Ingestion Framework qui écrit des données basées sur des événements dans Hadoop Distributed File System. C'est un fait connu que Hadoop traite les Big Data, la question se pose de savoir comment les données générées à partir de différents serveurs Web sont transmises à Hadoop File System? La réponse est Apache Flume. Flume est conçu pour une ingestion de données à haut volume vers Hadoop de données basées sur des événements.
Envisagez un scénario dans lequel le nombre de serveurs Web génère des fichiers journaux et ces fichiers journaux doivent être transmis au système de fichiers Hadoop. Flume collecte ces fichiers en tant qu'événements et les ingère dans Hadoop. Bien que Flume soit utilisé pour transmettre à Hadoop, il n'y a pas de règle rigide selon laquelle la destination doit être Hadoop. Flume est capable d'écrire sur d'autres Frameworks comme Hbase ou Solr.
Architecture de canal
En général, l'architecture Apache Flume est composée des composants suivants:
- Source de canal
- Canal Flume
- Évier Flume
- Agent Flume
- Événement Flume
Prenons un bref aperçu de chaque composant Flume
1. Source de canal
Une source Flume est présente sur les générateurs de données comme Face book ou Twitter. La source collecte les données du générateur et transfère ces données vers Flume Channel sous la forme d'événements Flume. Flume prend en charge divers types de sources comme Avro Flume Source: se connecte sur le port Avro et reçoit les événements du client externe Avro, Thrift Flume Source - se connecte sur le port Thrift et reçoit les événements des flux de clients externes Thrift, Spooling Directory Source et Kafka Flume Source.
2. Canal Flume
Un magasin intermédiaire qui met en mémoire tampon les événements envoyés par Flume Source jusqu'à ce qu'ils soient consommés par Sink est appelé Flume Channel. Le canal agit comme un pont intermédiaire entre la source et le récepteur. Les canaux de canal sont de nature transactionnelle.
Flume prend en charge le canal File et le canal Memory. Le canal de fichier est de nature durable, ce qui signifie qu'une fois les données écrites sur le canal, elles ne seront pas perdues, même si l'agent redémarre. En mémoire, les événements de canal sont stockés en mémoire, il n'est donc pas durable mais de nature très rapide.
3. évier de canal
Un Flume Sink est présent sur les référentiels de données comme HDFS, HBase. Flume sink consomme les événements de Channel et les stocke dans les magasins de destination comme HDFS. Il n'y a pas de règle telle que le récepteur doit livrer des événements au magasin, mais nous pouvons le configurer de telle manière qu'un récepteur puisse livrer des événements à un autre agent. Flume prend en charge divers éviers comme HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
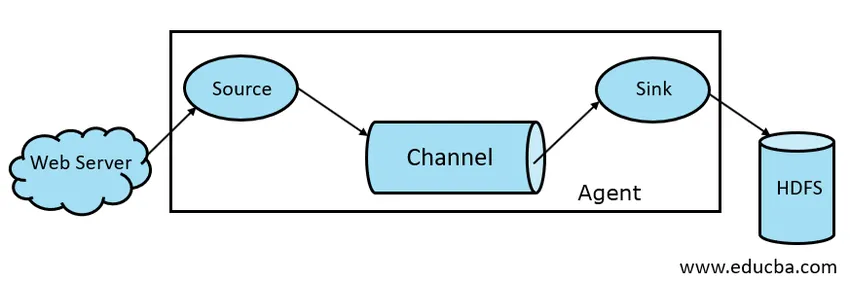
Fig 1.1 Architecture de base du canal
4. Agent Flume
Un agent Flume est un processus Java de longue durée qui s'exécute sur une combinaison source - canal - récepteur. Flume peut avoir plus d'un agent. Nous pouvons considérer Flume comme une collection d'agents Flume connectés qui sont distribués dans la nature.
5. Événement Flume
Un événement est l'unité de données transportée dans Flume . La représentation générale de l'objet de données dans Flume est appelée événement. L'événement est constitué d'une charge utile d'un tableau d'octets avec des en-têtes facultatifs.
Fonctionnement de Flume
Un agent Flume est un processus java composé de Source - Channel - Sink dans sa forme la plus simple. La source collecte les données du générateur de données sous forme d'événements et les transmet à Channel. Une source peut fournir à plusieurs canaux selon les besoins. Le fan out est le processus par lequel une seule source écrit sur plusieurs canaux afin de pouvoir les diffuser sur plusieurs récepteurs.
Un événement est l'unité de base des données transmises dans Flume. Channel met en mémoire tampon les données jusqu'à ce qu'elles soient ingérées par Sink. Sink collecte les données de Channel et les transmet au stockage de données centralisé comme HDFS ou Sink peut transmettre ces événements à un autre agent Flume selon les besoins.
Flume prend en charge les transactions. Afin d'atteindre la fiabilité, Flume utilise des transactions distinctes de la source au canal et du canal à l'évier. Si les événements ne sont pas livrés, la transaction est annulée puis redistribuée ultérieurement.
Afin de comprendre le fonctionnement de Flume, prenons un exemple de configuration Flume où la source est le répertoire de mise en file d'attente et le récepteur est Hdfs. Dans cet exemple, l'agent Flume est sous la forme la plus simple, c'est-à-dire une topologie source unique - canal - récepteur configurée à l'aide d'un fichier de propriétés java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Dans l'exemple de configuration ci-dessus, l'agent est la base avec laquelle nous définissons d'autres propriétés. source1 et sink1 et channel1 sont respectivement les noms de source, sink et channel et leurs types et emplacements sont également mentionnés en conséquence.
Avantages d'Apache Flume
- Flume est évolutif, fiable et tolérant aux pannes par nature. Ces propriétés sont discutées en détail ci-dessous
- Évolutif - Flume est évolutif horizontalement, c'est-à-dire que nous pouvons ajouter de nouveaux nœuds selon nos besoins
- Fiable - Apache Flume prend en charge les transactions et garantit qu'aucune donnée n'est perdue lors du processus de transmission de données. Il a différentes transactions de source en canal et de canal en source.
- Flume est personnalisable et prend en charge diverses sources et récepteurs comme Kafka, Avro, le répertoire de mise en file d'attente, Thrift, etc.
- Dans Flume, une seule source peut transmettre des données à plusieurs canaux et ces canaux à leur tour transmettront les données à plusieurs récepteurs, ainsi une seule source peut transmettre des données à plusieurs récepteurs. Ce mécanisme est appelé Fan out. Flume prend également en charge Fan out.
- Flume fournit le flux régulier de transmission de données, c'est-à-dire si la vitesse de lecture des données augmente, puis la vitesse d'écriture des données augmente également.
- Bien que Flume écrive généralement des données sur un stockage centralisé comme HDFS ou Hbase, nous pouvons configurer Flume selon nos besoins afin que Sink puisse écrire des données vers un autre agent. Cela montre la flexibilité de Flume
- Apache Flume est de nature open source.
Conclusion
Dans cet article Flume, les composants de Flume et le fonctionnement de Flume sont discutés en détail. Flume est une plateforme flexible, fiable et évolutive pour transmettre des données à un magasin centralisé comme HDFS. Sa capacité à s'intégrer à diverses applications comme Kafka, Hdfs, Thrift en fait une option viable pour l'ingestion de données.
Articles recommandés
Cela a été un guide pour Apache Flume. Nous discutons ici de l'architecture, du fonctionnement et des avantages d'Apache Flume. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Qu'est-ce que Apache Flink?
- Différence entre Apache Kafka et Flume
- Architecture Big Data
- Outils Hadoop
- Apprenez les différents événements JavaScript