
Différences entre Data Scientist et Machine Learning
Un Data Scientist est un expert chargé de collecter, d'examiner et d'interpréter de grands volumes de données afin de reconnaître les moyens d'aider une entreprise à améliorer ses opérations et à gagner un avantage viable sur ses concurrents. Il suit une approche interdisciplinaire. Il se situe entre la connexion des mathématiques, des statistiques, du génie logiciel, de l'intelligence artificielle et du Design Thinking. Il traite de la collecte de données, du nettoyage, de l'analyse, de la visualisation, du modèle de validation, de la prédiction des expériences, de la conception, des tests et des hypothèses beaucoup plus loin. L'apprentissage automatique est une division de l'intelligence artificielle qui est utilisée par la science des données pour atteindre ses objectifs. L'apprentissage automatique se concentre principalement sur les algorithmes, les structures polynomiales et l'ajout de mots. Il se compose d'un groupe d'algorithmes, de machines et leur permet d'apprendre sans être clairement programmé pour cela.
Scientifique des données
Ce rôle de Data Scientist est une branche du rôle des statistiques qui inclut l'utilisation de la version avancée des technologies analytiques, y compris l'apprentissage automatique et la modélisation prédictive, pour fournir des visions au-delà de l'analyse statistique. La pétition pour les compétences en science des données s'est considérablement développée ces dernières années, les entreprises cherchant à collecter des informations utiles à partir des énormes quantités de données structurées, semi-structurées et non structurées qu'une grande entreprise produit et appelées collectivement big data. Le but de toutes les étapes est simplement de tirer des informations des données.
Tâches standard:
- Allouer, agréger et synthétiser les données de diverses sources structurées et non structurées
- Explorer, développer et appliquer un apprentissage intelligent aux données du monde réel, fournir des résultats importants et des actions réussies basées sur eux
- Analyser et fournir les données collectées dans l'organisation
- Concevoir et construire de nouveaux processus de modélisation, d'exploration de données et de mise en œuvre
- Développer des prototypes, des algorithmes, des modèles prédictifs, des prototypes
- Effectuer des demandes d'analyse de données et communiquer leurs conclusions et décisions
De plus, il existe des tâches plus spécifiques selon le domaine dans lequel l'employeur travaille ou le projet est mis en œuvre.
Données brutes -> Data Science --> Informations exploitables
Apprentissage automatique
Le poste d'Ingénieur Machine Learning est plus «technique». ML Engineer a plus en commun avec le génie logiciel classique qu'avec Data Scientist. Il vous aide à apprendre la fonction objectif qui trace les entrées de la variable cible et / ou des variables indépendantes des variables dépendantes.
Les tâches standard de ML Engineer sont généralement similaires à celles de Data Scientist. Vous devez également être en mesure de travailler avec des données, d'expérimenter différents algorithmes d'apprentissage automatique qui permettront de résoudre la tâche, de créer des prototypes et des solutions prêtes à l'emploi.
Les connaissances et compétences requises pour ce poste chevauchent également celles de Data Scientist. Parmi les principales différences, je voudrais souligner:
- Solides compétences en programmation dans un ou plusieurs langages populaires (généralement Python et Java), ainsi que dans les bases de données;
- Moins d'accent sur la capacité de travailler dans des environnements d'analyse de données, mais plus d'accent sur les algorithmes d'apprentissage automatique;
- R et Python pour la modélisation sont préférables à Matlab, SPSS et SAS;
- Capacité à utiliser des bibliothèques prêtes à l'emploi pour diverses piles dans l'application, par exemple Mahout, Lucene pour Java, NumPy / SciPy pour Python;
- Possibilité de créer des applications distribuées à l'aide de Hadoop et d'autres solutions.
Comme vous pouvez le voir, le poste d'ingénieur ML (ou plus étroit) nécessite plus de connaissances en génie logiciel et, par conséquent, convient bien aux développeurs expérimentés. Très souvent, le cas fonctionne lorsque le développeur habituel doit résoudre la tâche ML pour son devoir, et il commence à comprendre les algorithmes et les bibliothèques nécessaires.
Comparaison directe entre Data Scientist et Machine Learning
Vous trouverez ci-dessous les 5 principales différences entre Data Scientist et Ingénieur Machine Learning 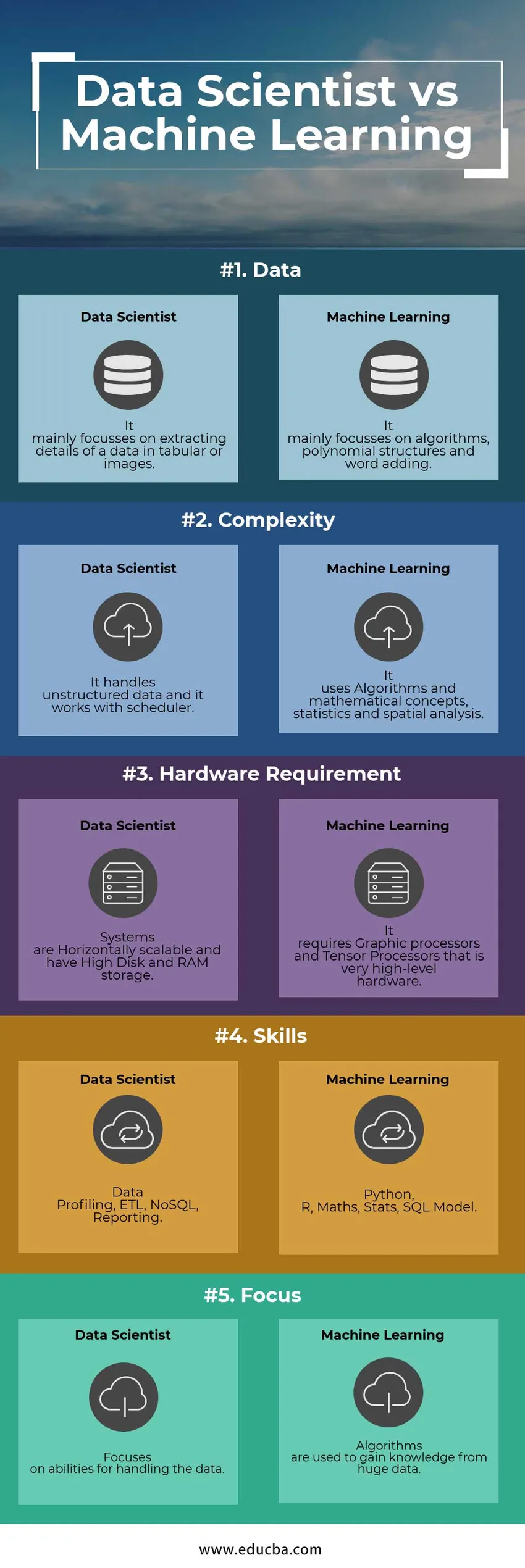
Différence clé entre Data Scientist et Machine Learning
Voici les listes de points, décrivez les principales différences entre Data Scientist et ingénieur Machine Learning
- L'apprentissage automatique et les statistiques font partie de la science des données. Le mot apprentissage dans l'apprentissage automatique signifie que les algorithmes dépendent de certaines données, utilisées comme ensemble d'apprentissage, pour affiner certains paramètres de modèle ou d'algorithme. Cela englobe de nombreuses techniques telles que la régression, les Bayes naïfs ou le clustering supervisé. Mais toutes les techniques ne rentrent pas dans cette catégorie. Par exemple, le clustering non supervisé - une technique statistique et de science des données - vise à détecter les clusters et les structures de cluster sans aucune connaissance ni formation préalable pour aider l'algorithme de classification. Un être humain est nécessaire pour étiqueter les grappes trouvées. Certaines techniques sont hybrides, comme la classification semi-supervisée. Certaines techniques de détection de modèle ou d'estimation de densité entrent dans cette catégorie.
- La science des données est bien plus que l'apprentissage automatique. Les données, en science des données, peuvent ou non provenir d'une machine ou d'un processus mécanique (les données d'enquête peuvent être collectées manuellement, les essais cliniques impliquent un type spécifique de petites données) et cela peut n'avoir rien à voir avec l'apprentissage comme je viens de le dire. Mais la principale différence est le fait que la science des données couvre tout le spectre du traitement des données, pas seulement les aspects algorithmiques ou statistiques. La science des données couvre également l'intégration des données, l'architecture distribuée, l'apprentissage automatique automatisé, la visualisation des données, les tableaux de bord et l'ingénierie du Big Data.
Tableau comparatif Data Scientist vs Machine Learning
Voici les listes de points, décrivez les comparaisons entre Data Scientist vs Machine Learning engineer:
| Fonctionnalité | Scientifique des données | Apprentissage automatique |
| Les données | Il se concentre principalement sur l'extraction des détails d'une donnée sous forme de tableau ou d'images | Il se concentre principalement sur les algorithmes, les structures polynomiales et l'ajout de mots |
| Complexité | Il gère les données non structurées et fonctionne avec le planificateur | Il utilise des algorithmes et des concepts mathématiques, des statistiques et une analyse spatiale |
| Configuration matérielle requise | Les systèmes sont évolutifs horizontalement et disposent d'un stockage sur disque et RAM élevé | Il nécessite des processeurs graphiques et des processeurs Tensor qui sont du matériel de très haut niveau |
| Compétences | Profilage des données, ETL, NoSQL, Reporting | Python, R, mathématiques, statistiques, modèle SQL |
| Concentrer | Se concentre sur les capacités de traitement des données | Les algorithmes sont utilisés pour acquérir des connaissances à partir d'énormes données |
Conclusion - Data Scientist vs Machine Learning
L'apprentissage automatique vous aide à apprendre la fonction objectif qui trace les entrées de la variable cible et / ou des variables indépendantes des variables dépendantes
Un scientifique des données fait beaucoup d'exploration des données et arrive à la stratégie globale de la façon de les traiter. Il est responsable de poser des questions à l'intérieur des données et de trouver les réponses que l'on peut raisonnablement tirer des données. L'ingénierie des fonctionnalités appartient au domaine du Data Scientist. La créativité joue également un rôle ici et un ingénieur en apprentissage automatique connaît plus d'outils et peut créer des modèles en fonction d'un ensemble de fonctionnalités et de données - selon les instructions du Data Scientist. Le domaine du prétraitement des données et de l'extraction des fonctionnalités appartient à l'ingénieur ML.
La science et l'examen des données utilisent l'apprentissage automatique pour ce type de validation et de création archétypales. Il est essentiel de noter que tous les algorithmes de cette création de modèle peuvent ne pas provenir de l'apprentissage automatique. Ils peuvent arriver de nombreux autres domaines. Le modèle souhaite être toujours pertinent. Si les situations changent, alors le modèle que nous avons créé plus tôt peut devenir immatériel. Les exigences du modèle doivent être vérifiées à différents moments et doivent être adaptées si sa certitude diminue.
La science des données est un vaste domaine. Si nous essayons de le mettre dans un pipeline, il aurait l'acquisition de données, le stockage de données, le prétraitement ou le nettoyage des données, les modèles d'apprentissage dans les données (via l'apprentissage automatique), en utilisant l'apprentissage pour les prédictions. C'est une façon de comprendre comment l'apprentissage automatique s'intègre dans la science des données.
Article recommandé
Il s'agit d'un guide des différences entre Data Scientist et ingénieur en apprentissage automatique, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Exploration de données vs apprentissage automatique - 10 meilleures choses que vous devez savoir
- Apprentissage automatique vs analyse prédictive - 7 différences utiles
- Data Scientist vs Business Analyst - Découvrez les 5 différences impressionnantes
- Data Scientist vs Data Engineer - 7 comparaisons étonnantes
- D'entretiens chez Software Engineering | Top et les plus demandés