

Différence entre MapReduce et Spark
Map Reduce est un cadre open source pour l'écriture de données dans HDFS et le traitement de données structurées et non structurées présentes dans HDFS. Map Reduce est limité au traitement par lots et sur d'autres Spark est capable d'effectuer tout type de traitement. SPARK est un moteur de traitement indépendant pour le traitement en temps réel qui peut être installé sur n'importe quel système de fichiers distribués comme Hadoop. SPARK offre des performances 10 fois plus rapides que Map Reduce sur disque et 100 fois plus rapides que Map Reduce sur un réseau en mémoire.
Besoin de SPARK
- Analyse itérative: Map-Reduce n'est pas aussi efficace qu'un SPARK pour résoudre les problèmes qui nécessitent une analyse itérative, car il doit aller sur le disque pour chaque itération.
- Interactive Analytics: Map-Reduce est souvent utilisé pour exécuter des requêtes ad hoc pour lesquelles il doit accéder à une mémoire sur disque qui, là encore, n'est pas aussi efficace que SPARK car cette dernière fait référence dans la mémoire, ce qui est plus rapide.
- Ne convient pas pour OLTP: Comme il fonctionne sur le framework orienté par lots, il ne convient pas pour un grand nombre de transactions courtes.
- Ne convient pas au graphique: la bibliothèque de graphiques Apache traite le graphique, ce qui ajoute plus de complexité à Map Reduce.
- Ne convient pas aux opérations triviales: pour les opérations comme un filtre et des jointures, nous pourrions avoir besoin de réécrire les travaux, ce qui devient plus complexe en raison du modèle de valeur-clé.
Comparaison directe entre MapReduce et Spark (infographie)
Ci-dessous se trouve la principale différence de 15 entre MapReduce et Spark

Différences clés entre MapReduce et Spark
Voici les listes de points, décrivez les principales différences entre MapReduce et Spark:
- Spark est adapté au temps réel car il traite en utilisant en mémoire tandis que MapReduce est limité au traitement par lots.
- Spark a RDD (Resilient Distributed Dataset), ce qui nous donne des opérateurs de haut niveau, mais dans Map Reduce, nous devons coder chaque opération, ce qui la rend relativement difficile.
- Spark peut traiter des graphiques et prend en charge l'outil d'apprentissage automatique.
- Voici la différence entre l'écosystème MapReduce vs Spark.
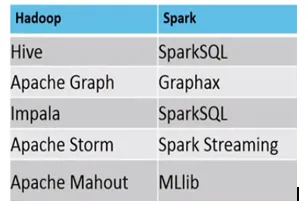
Exemple, où MapReduce vs Spark conviennent, sont les suivants
Spark: Détection de fraude par carte de crédit
MapReduce: Réalisation de rapports réguliers nécessitant une prise de décision.
Tableau de comparaison MapReduce vs Spark
| Base de comparaison | MapReduce | Étincelle |
| Cadre | Un framework open source pour écrire des données dans HDFS et traiter des données structurées et non structurées présentes dans HDFS. | Un framework open source pour un traitement des données plus rapide et polyvalent |
| La vitesse | Map-Reduce traite les données (lecture et écriture) à partir du disque afin que le suintement soit lent par rapport à Spark. | Spark est au moins 10 fois plus rapide sur le disque et 100 fois plus rapide en mémoire que celui de Map Reduce. |
| Difficulté | Nous devons coder / gérer chaque processus. | Avec la disponibilité du RDD (Resilient Distributed Dataset), il est facile de programmer. |
| Temps réel | Ne convient pas pour la transaction OLTP uniquement pour le mode batch | Il peut gérer le traitement en temps réel. Utilisation de SPARK Streaming. |
| Latence | Cadre de calcul de latence de haut niveau | Cadre de calcul de latence de bas niveau. |
| Tolérance aux pannes | Les démons maîtres vérifient le rythme cardiaque des démons esclaves et en cas d'échec des démons esclaves, les démons maîtres replanifient toutes les opérations en attente et en cours sur un autre esclave. | Les RDD offrent une tolérance aux pannes pour SPARK. Ils se réfèrent à l'ensemble de données présent dans le stockage externe comme (HDFS, HBase) et fonctionnent en parallèle. |
| Planificateur | Dans Map Reduce, nous utilisons un planificateur externe comme Oozie. | Comme SPARK fonctionne avec l'informatique en mémoire, il agit comme son propre ordonnanceur. |
| Coût | Map Reduce est relativement moins cher que SPARK. | Comme il fonctionne en mémoire, il nécessite donc beaucoup de RAM, ce qui le rend relativement plus coûteux. |
| Plateforme développée sur | Map Reduce a été développé en utilisant Java. | SPARK a été développé en utilisant Scala. |
| Langue prise en charge | Map Reduce prend essentiellement en charge C, C ++, Ruby, Groovy, Perl, Python. | Spark prend en charge Scala, Java, Python, R, SQL. |
| Prise en charge SQL | Map Reduce exécute des requêtes à l'aide du langage de requête Hive. | Spark possède son propre langage de requête appelé Spark SQL. |
| Évolutivité | Dans Map Reduce, nous pouvons ajouter jusqu'à n nombre de nœuds. Le plus grand cluster Hadoop compte 14 000 nœuds. | Dans Spark, nous pouvons également ajouter n nombre de nœuds. Le plus grand cluster Spark compte 8 000 nœuds. |
| Apprentissage automatique | Map Reduce prend en charge l'outil Apache Mahout pour l'apprentissage automatique. | Spark prend en charge l'outil MLlib pour l'apprentissage automatique. |
| Mise en cache | Map Reduce n'est pas en mesure de mettre en cache les données en mémoire, ce n'est donc pas aussi rapide que Spark. | Spark met en cache les données en mémoire pour d'autres itérations, ce qui est très rapide par rapport à Map Reduce. |
| Sécurité | Map Reduce prend en charge davantage de projets et de fonctionnalités de sécurité par rapport à Spark | La sécurité Spark n'est pas encore arrivée à maturité comme celle de Map Reduce |
Conclusion - MapReduce vs Spark
Selon la différence ci-dessus entre MapReduce et Spark, il est assez clair que SPARK est un moteur informatique beaucoup plus avancé que Map Reduce. Spark est compatible avec tout type de format de fichier et également assez rapide que Map Reduce. L'étincelle a également des capacités de traitement graphique et d'apprentissage automatique.
D'une part, Map Reduce est limité au traitement par lots et d'autre part Spark est capable de faire tout type de traitement (batch, interactif, itératif, streaming, graphique). En raison de sa grande compatibilité, Spark est le favori de Data Scientist et, par conséquent, il remplace Map Reduce et se développe rapidement. Mais nous devons toujours stocker les données dans HDFS et nous pouvons aussi parfois avoir besoin de HBase. Nous devons donc exécuter Spark et Hadoop pour tirer le meilleur parti.
Articles recommandés:
Ceci a été un guide pour MapReduce vs Spark, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- 7 choses importantes sur Apache Spark (Guide)
- Hadoop vs Apache Spark - Choses intéressantes que vous devez savoir
- Apache Hadoop vs Apache Spark | Top 10 des comparaisons que vous devez savoir!
- Comment fonctionne MapReduce?
- Confluence de la technologie et de l'analyse commerciale