

Introduction à l'architecture Hadoop
Hadoop Architecture est un framework open source qui aide à traiter facilement de grands ensembles de données. Il aide à créer des applications qui traitent d'énormes données avec plus de vitesse. Il utilise les concepts informatiques distribués où les données sont réparties sur différents nœuds d'un cluster. Les applications construites à l'aide de Hadoop utilisent des ordinateurs standard. Ces ordinateurs sont disponibles facilement sur le marché à des tarifs avantageux. Ce résultat permet d'obtenir une plus grande puissance de calcul à faible coût. Toutes les données présentes dans Hadoop résident sur HDFS au lieu d'un système de fichiers local. HDFS est un système de fichiers distribué Hadoop. Ce modèle est basé sur Data Locality où la logique de calcul est envoyée aux nœuds présents dans un cluster qui contient les données. Cette logique n'est rien d'autre qu'une logique qui compile le programme.
Architecture Hadoop
L'idée de base de cette architecture est que l'ensemble du stockage et du traitement se fait en deux étapes et de deux manières. La première étape est le traitement qui est effectué par la carte de réduire la programmation et la deuxième étape consiste à stocker les données qui sont effectuées sur HDFS. Il a une architecture maître-esclave pour le stockage et le traitement des données. Le nœud maître pour le stockage de données dans Hadoop est le nœud de nom. Il existe également un nœud maître qui effectue le travail de surveillance et de traitement parallèle des données en utilisant Hadoop Map Reduce. Les esclaves sont d'autres machines du cluster Hadoop qui aident à stocker des données et effectuent également des calculs complexes. Chaque nœud esclave a été affecté à un traqueur de tâches et un nœud de données a un traqueur de travaux qui aide à exécuter les processus et à les synchroniser efficacement. Ce type de système peut être configuré sur le cloud ou sur site. Le nœud Nom est un point de défaillance unique lorsqu'il ne s'exécute pas en mode haute disponibilité. L'architecture Hadoop a également prévu de maintenir un nœud de nom en attente afin de protéger le système contre les pannes. Auparavant, il y avait des nœuds de nom secondaires qui faisaient office de sauvegarde lorsque le nœud de nom principal était arrêté.
FSimage et modifier le journal
FSimage et le journal d'édition garantissent la persistance des métadonnées du système de fichiers pour suivre toutes les informations et le nœud de nom stocke les métadonnées dans deux fichiers. Ces fichiers sont FSimage et le journal d'édition. Le travail de FSimage est de conserver un instantané complet du système de fichiers à un moment donné. Les modifications qui sont constamment apportées à un système doivent être enregistrées. Ces modifications incrémentielles telles que le changement de nom ou l'ajout de détails au fichier sont stockées dans le journal d'édition. Le cadre fournit une meilleure option plutôt que de créer une nouvelle FSimage à chaque fois, une meilleure option étant capable de stocker les données tout en un nouveau fichier pour FSimage. FSimage crée un nouvel instantané chaque fois que des modifications sont apportées Si le nœud Nom échoue, il peut restaurer son état précédent. Le nœud de nom secondaire peut également mettre à jour sa copie chaque fois qu'il y a des modifications dans FSimage et modifier les journaux. Ainsi, il garantit que même si le nœud de nom est en panne, en présence d'un nœud de nom secondaire, il n'y aura pas de perte de données. Le nœud de nom ne nécessite pas que ces images doivent être rechargées sur le nœud de nom secondaire.
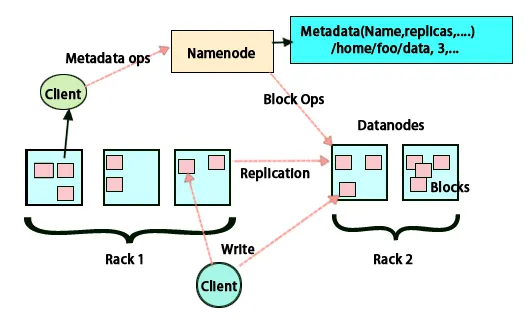
Réplication de données
HDFS est conçu pour traiter des données rapidement et fournir des données fiables. Il stocke les données sur plusieurs machines et dans de grands clusters. Tous les fichiers sont stockés dans une série de blocs. Ces blocs sont répliqués pour la tolérance aux pannes. La taille du bloc et le facteur de réplication peuvent être décidés par les utilisateurs et configurés selon les besoins des utilisateurs. Par défaut, le facteur de réplication est 3. Le facteur de réplication peut être spécifié au moment de la création du fichier et il peut être modifié ultérieurement. Toutes les décisions concernant ces répliques sont prises par le nœud de nom. Le nœud de nom continue d'envoyer des pulsations et un rapport de blocage à intervalles réguliers pour tous les nœuds de données du cluster. La réception du rythme cardiaque implique que le nœud de données fonctionne correctement. Le rapport de bloc spécifie la liste de tous les blocs présents sur le nœud de données.
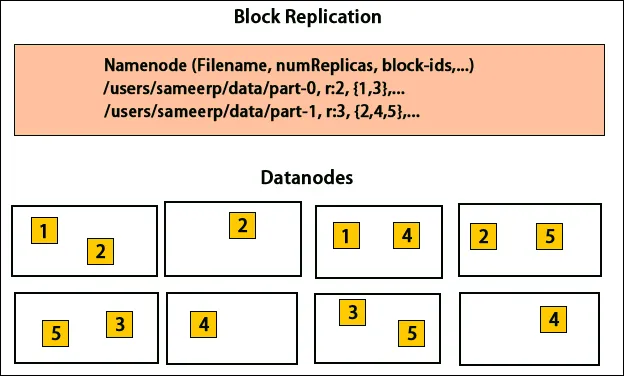
Placement des répliques
Le placement des répliques est une tâche très importante dans Hadoop pour la fiabilité et les performances. Tous les différents blocs de données sont placés sur des racks différents. L'implémentation du placement des répliques peut être effectuée selon la fiabilité, la disponibilité et l'utilisation de la bande passante du réseau. Le cluster d'ordinateurs peut être réparti sur différents racks. Pas plus de deux nœuds peuvent être placés sur le même rack. La troisième réplique doit être placée sur un rack différent pour garantir une plus grande fiabilité des données. Les deux nœuds du rack communiquent via différents commutateurs. Le nœud de nom a l'ID de rack pour chaque nœud de données. Mais placer tous les nœuds sur des racks différents empêche la perte de données et permet l'utilisation de la bande passante de plusieurs racks. Il réduit également le trafic inter-rack et améliore les performances. En outre, le risque de défaillance du rack est très inférieur à celui d'une défaillance de nœud. Il réduit la bande passante réseau globale lorsque les données sont lues à partir de deux racks uniques plutôt que de trois.
Réduire la carte
Map Reduce est utilisé pour le traitement des données stockées sur HDFS. Il écrit des données réparties sur des applications réparties, ce qui garantit un traitement efficace de grandes quantités de données. Ils traitent sur de grandes grappes et nécessitent des produits fiables et tolérants aux pannes. Le cœur de Map-Reduce peut être constitué de trois opérations telles que la cartographie, la collecte de paires et la lecture aléatoire des données résultantes.
Conclusion - Architecture Hadoop
Hadoop est un framework open source qui aide dans un système tolérant aux pannes. Il peut stocker de grandes quantités de données et aide à stocker des données fiables. Les deux parties du stockage des données dans HDFS et du traitement par le biais de la carte réduisent l'aide à un fonctionnement correct et efficace. Il a une architecture qui aide à gérer tous les blocs de données et également à avoir la copie la plus récente en la stockant dans FSimage et à modifier les journaux. Le facteur de réplication permet également d'avoir des copies des données et de les récupérer en cas de panne. HDFS déplace également les fichiers supprimés vers le répertoire de la corbeille pour une utilisation optimale de l'espace.
Articles recommandés
Cela a été un guide pour l'architecture Hadoop. Ici, nous avons discuté de l'architecture, de la réduction de la carte, du placement des répliques, de la réplication des données. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Devenez développeur Hadoop
- Introduction à Android
- Qu'est-ce que Tableau? | Un aperçu
- Qu'est-ce que MapReduce dans Hadoop?