

Questions et réponses d'entrevue d'apprentissage en profondeur
Aujourd'hui, le Deep Learning est considéré comme l'une des technologies à la croissance la plus rapide avec une énorme capacité à développer une application qui a été considérée comme difficile il y a quelque temps. La reconnaissance vocale, la reconnaissance d'images, la recherche de modèles dans un ensemble de données, la classification d'objets dans les photographies, la génération de texte de caractères, les voitures autonomes et bien d'autres ne sont que quelques exemples où le Deep Learning a montré son importance.
Vous avez donc finalement trouvé votre emploi de rêve dans le Deep Learning, mais vous vous demandez comment résoudre le Deep Learning Interview et quelles pourraient être les probables questions du Deep Learning Interview. Chaque entretien est différent et la portée d'un travail est également différente. En gardant cela à l'esprit, nous avons conçu les questions et réponses d'entrevue d'apprentissage en profondeur les plus courantes pour vous aider à réussir votre entrevue.
Vous trouverez ci-dessous quelques questions d'entrevue d'apprentissage approfondi qui sont fréquemment posées dans l'entrevue et pourraient également aider à tester vos niveaux:
Partie 1 - Questions d'entrevue d'apprentissage approfondi (de base)
Cette première partie couvre les questions et réponses d'entrevue de base sur l'apprentissage en profondeur
1. Qu'est-ce que l'apprentissage en profondeur?
Répondre:
Le domaine de l'apprentissage automatique qui se concentre sur les réseaux de neurones artificiels profonds qui sont vaguement inspirés par le cerveau. Alexey Grigorevich Ivakhnenko a publié le premier général sur le travail du réseau Deep Learning. Aujourd'hui, il trouve son application dans divers domaines tels que la vision par ordinateur, la reconnaissance vocale, le traitement du langage naturel.
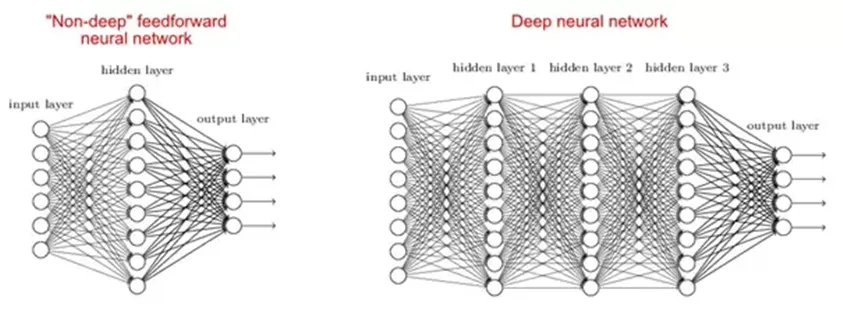
2. Pourquoi les réseaux profonds sont-ils meilleurs que les réseaux peu profonds?
Répondre:
Il existe des études qui disent que les réseaux peu profonds et profonds peuvent s'adapter à n'importe quelle fonction, mais comme les réseaux profonds ont plusieurs couches cachées souvent de types différents, ils sont donc en mesure de créer ou d'extraire de meilleures fonctionnalités que les modèles peu profonds avec moins de paramètres.
3. Quelle est la fonction de coût?
Répondre:
Une fonction de coût est une mesure de la précision du réseau neuronal par rapport à l'échantillon d'apprentissage donné et à la sortie attendue. C'est une valeur unique, non vectorielle car elle donne les performances du réseau neuronal dans son ensemble. Il peut être calculé comme ci-dessous la fonction d'erreur quadratique moyenne: -
MSE = 1n∑i = 0n (Y i – Yi) 2
Où Y et la valeur souhaitée Y est ce que nous voulons minimiser.
Passons aux prochaines questions d'entrevue sur l'apprentissage en profondeur.
4. Qu'est-ce que la descente en pente?
Répondre:
La descente de gradient est essentiellement un algorithme d'optimisation, qui est utilisé pour apprendre la valeur des paramètres qui minimise la fonction de coût. Il s'agit d'un algorithme itératif qui se déplace dans le sens de la descente la plus raide définie par le négatif du gradient. Nous calculons la descente de gradient de la fonction de coût pour un paramètre donné et mettons à jour le paramètre par la formule ci-dessous: -
Θ: = Θ – αd∂ΘJ (Θ)
Où Θ - est le vecteur de paramètre, α - taux d'apprentissage, J (Θ) - est une fonction de coût.
5. Qu'est-ce que la rétropropagation?
Répondre:
La rétropropagation est un algorithme d'apprentissage utilisé pour un réseau neuronal multicouche. Dans cette méthode, nous déplaçons l'erreur d'une extrémité du réseau à tous les poids à l'intérieur du réseau et permettant ainsi un calcul efficace du gradient. Il peut être divisé en plusieurs étapes comme suit: -
PropagationPropagation vers l'avant des données d'entraînement afin de générer des résultats.
HenLorsque la valeur cible et la valeur de sortie sont dérivées, une dérivée d'erreur peut être calculée par rapport à l'activation de la sortie.
HenPuis nous rétropropagons pour calculer la dérivée de l'erreur par rapport à l'activation de la sortie sur la précédente et continuons cela pour toutes les couches cachées.
SingEn utilisant les dérivées précédemment calculées pour la sortie et toutes les couches cachées, nous calculons les dérivées d'erreur par rapport aux poids.
NdEnsuite, nous mettons à jour les poids.
6. Expliquez les trois variantes suivantes de descente de gradient: batch, stochastique et mini-batch?
Répondre:
Descente de gradient stochastique : Ici, nous utilisons un seul exemple d'apprentissage pour le calcul du gradient et les paramètres de mise à jour.
Descente de gradient par lots : ici, nous calculons le gradient pour l'ensemble de données et effectuons la mise à jour à chaque itération.
Descente de gradient en mini-lot : c'est l'un des algorithmes d'optimisation les plus populaires. C'est une variante de la descente de gradient stochastique et ici, au lieu d'un seul exemple d'apprentissage, un mini-lot d'échantillons est utilisé.
Partie 2 - Questions d'entrevue d'apprentissage en profondeur (avancé)
Jetons maintenant un coup d'œil aux questions d'entrevue avancées sur l'apprentissage en profondeur.
7. Quels sont les avantages de la descente en gradient en mini-lots?
Répondre:
Voici les avantages de la descente en gradient en mini-batch
• Ceci est plus efficace que la descente de gradient stochastique.
• La généralisation en trouvant les minima plats.
• Les mini-lots permettent d'aider à approximer le gradient de l'ensemble d'entraînement, ce qui nous aide à éviter les minima locaux.
8. Qu'est-ce que la normalisation des données et pourquoi en avons-nous besoin?
Répondre:
La normalisation des données est utilisée pendant la rétropropagation. Le principal motif de la normalisation des données est de réduire ou d'éliminer la redondance des données. Ici, nous redimensionnons les valeurs pour qu'elles s'inscrivent dans une plage spécifique afin d'obtenir une meilleure convergence.
Passons aux prochaines questions d'entrevue sur l'apprentissage en profondeur.
9. Qu'est-ce que l'initialisation du poids dans les réseaux de neurones?
Répondre:
L'initialisation du poids est l'une des étapes très importantes. Une mauvaise initialisation de poids peut empêcher un réseau d'apprendre, mais une bonne initialisation de poids aide à donner une convergence plus rapide et une meilleure erreur globale. Les biais peuvent généralement être initialisés à zéro. La règle pour fixer les poids est d'être proche de zéro sans être trop petite.
10. Qu'est-ce qu'un encodeur automatique?
Répondre:
Un autoencodeur est un algorithme d'apprentissage automatique autonome qui utilise le principe de rétropropagation, où les valeurs cibles sont définies pour être égales aux entrées fournies. En interne, il a une couche cachée qui décrit un code utilisé pour représenter l'entrée.
Quelques faits clés sur l'autoencodeur sont les suivants: -
• Il s'agit d'un algorithme ML non supervisé similaire à l'analyse en composantes principales
• Il minimise la même fonction objectif que l'analyse en composantes principales
• C'est un réseau de neurones
• La sortie cible du réseau neuronal est son entrée
11. Puis-je me reconnecter d'une sortie de couche 4 à une entrée de couche 2?
Répondre:
Oui, cela peut être fait en considérant que la sortie de la couche 4 est du pas de temps précédent comme dans RNN. En outre, nous devons supposer que le lot d'entrée précédent est parfois corrélé avec le lot actuel.
Passons aux prochaines questions d'entrevue sur l'apprentissage en profondeur.
12. Qu'est-ce que la machine Boltzmann?
Répondre:
La machine Boltzmann est utilisée pour optimiser la solution d'un problème. Le travail de la machine Boltzmann consiste essentiellement à optimiser les poids et la quantité pour le problème donné.
Quelques points importants à propos de Boltzmann Machine -
• Il utilise une structure récurrente.
• Il se compose de neurones stochastiques, qui consistent en l'un des deux états possibles, soit 1 ou 0.
• Les neurones qui s'y trouvent sont soit dans un état adaptatif (état libre) soit dans un état fermé (état gelé).
• Si nous appliquons un recuit simulé sur un réseau Hopfield discret, il deviendrait alors Boltzmann Machine.
13. Quel est le rôle de la fonction d'activation?
Répondre:
La fonction d'activation est utilisée pour introduire la non-linéarité dans le réseau neuronal en l'aidant à apprendre des fonctions plus complexes. Sans quoi le réseau neuronal ne pourrait apprendre que la fonction linéaire qui est une combinaison linéaire de ses données d'entrée.
Articles recommandés
Cela a été un guide pour la liste des questions et réponses d'entrevue d'apprentissage en profondeur afin que le candidat puisse réprimer facilement ces questions d'entrevue d'apprentissage en profondeur. Vous pouvez également consulter les articles suivants pour en savoir plus
- Apprenez les 10 questions les plus utiles d'entrevue de HBase
- Questions et réponses utiles pour l'entretien sur l'apprentissage automatique
- Les 5 questions d'entrevue les plus utiles sur la science des données
- Questions et réponses importantes pour l'entretien avec Ruby