
Introduction aux techniques d'ensemble
L'apprentissage en ensemble est une technique d'apprentissage automatique qui utilise plusieurs modèles de base et combine leurs résultats pour produire un modèle optimisé. Ce type d'algorithme d'apprentissage automatique aide à améliorer les performances globales du modèle. Ici, le modèle de base le plus couramment utilisé est le classificateur de l'arbre de décision. Un arbre de décision fonctionne essentiellement sur plusieurs règles et fournit une sortie prédictive, où les règles sont les nœuds et leurs décisions seront leurs enfants et les nœuds feuilles constitueront la décision finale. Comme le montre l'exemple d'un arbre de décision.
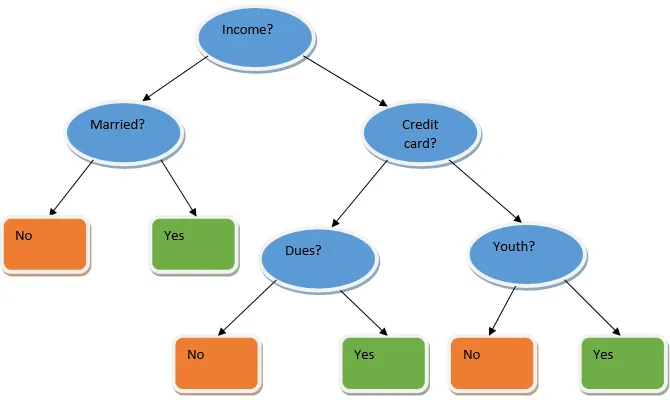
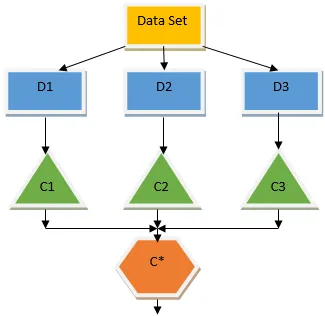
L'arbre de décision ci-dessus indique essentiellement si une personne / un client peut obtenir un prêt ou non. Une des règles d'admissibilité au prêt oui est que si (revenu = oui et marié = non) alors prêt = oui, c'est ainsi que fonctionne un classificateur d'arbre de décision. Nous allons incorporer ces classificateurs en tant que modèle de base multiple et combiner leur sortie pour construire un modèle prédictif optimal. La figure 1.b montre l'image globale d'un algorithme d'apprentissage d'ensemble.
Types de techniques d'ensembles
Différents types d'ensembles, mais nous nous concentrerons principalement sur les deux types ci-dessous:
- Ensachage
- Booster
Ces méthodes aident à réduire la variance et le biais dans un modèle d'apprentissage automatique. Essayons maintenant de comprendre ce qu'est le biais et la variance. Le biais est une erreur qui se produit en raison d'hypothèses incorrectes dans notre algorithme; un biais élevé indique que notre modèle est trop simple / trop mince. La variance est l'erreur qui est causée en raison de la sensibilité du modèle à de très petites fluctuations dans l'ensemble de données; une variance élevée indique que notre modèle est très complexe / surajusté. Un modèle ML idéal devrait avoir un bon équilibre entre le biais et la variance.
Agrégation / ensachage Bootstrap
L'ensachage est une technique d'ensemble qui aide à réduire la variance dans notre modèle et évite ainsi le sur-ajustement. L'ensachage est un exemple de l'algorithme d'apprentissage parallèle. L'ensachage fonctionne selon deux principes.
- Bootstrapping: À partir de l'ensemble de données d'origine, différentes populations d'échantillons sont considérées avec remplacement.
- Agrégation: en faisant la moyenne des résultats de tous les classificateurs et en fournissant une sortie unique, pour cela, elle utilise le vote majoritaire dans le cas de la classification et la moyenne dans le cas du problème de régression. L'un des célèbres algorithmes d'apprentissage automatique qui utilise le concept d'ensachage est une forêt aléatoire.
Forêt aléatoire
Dans la forêt aléatoire de l'échantillon aléatoire retiré de la population avec remplacement et un sous-ensemble de caractéristiques est sélectionné dans l'ensemble de toutes les caractéristiques, un arbre de décision est construit. À partir de ces sous-ensembles de fonctionnalités, la fonction qui donne la meilleure répartition est sélectionnée comme racine de l'arbre de décision. Le sous-ensemble de fonctionnalités doit être choisi au hasard à tout prix, sinon nous finirons par ne produire que des arbres corrélés et la variance du modèle ne sera pas améliorée.
Maintenant que nous avons construit notre modèle avec les échantillons prélevés dans la population, la question est de savoir comment valider le modèle? Étant donné que nous considérons les échantillons avec remplacement, tous les échantillons ne seront pas pris en compte et certains d'entre eux ne seront inclus dans aucun sac, ils sont appelés échantillons hors sac. Nous pouvons valider notre modèle avec ces échantillons OOB (hors sachet). Les paramètres importants à considérer dans une forêt aléatoire sont le nombre d'échantillons et le nombre d'arbres. Considérons «m» comme le sous-ensemble de fonctionnalités et «p» est l'ensemble complet des fonctionnalités, maintenant en règle générale, il est toujours idéal de choisir
- m as√et une taille minimale de nœud égale à 1 pour un problème de classification.
- m comme P / 3 et la taille minimale du nœud à 5 pour un problème de régression.
Les m et p doivent être traités comme des paramètres de réglage lorsque nous traitons un problème pratique. La formation peut être interrompue une fois que l'erreur OOB se stabilise. Un inconvénient de la forêt aléatoire est que lorsque nous avons 100 fonctionnalités dans notre ensemble de données et que seules quelques fonctionnalités sont importantes, cet algorithme fonctionnera mal.
Booster
Le boosting est un algorithme d'apprentissage séquentiel qui aide à réduire le biais dans notre modèle et la variance dans certains cas d'apprentissage supervisé. Il aide également à convertir les apprenants faibles en apprenants forts. Boosting fonctionne sur le principe de placer les apprenants faibles séquentiellement et attribue un poids à chaque point de données après chaque tour; plus de poids est attribué au point de données mal classé dans le cycle précédent. Cette méthode séquentielle pondérée de formation de notre ensemble de données est la principale différence avec celle de l'ensachage.
La Fig3.a montre l'approche générale du renforcement
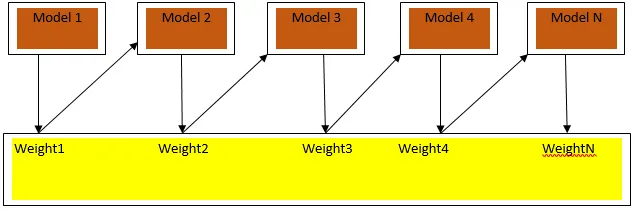
Les prévisions finales sont combinées sur la base du vote à la majorité pondérée dans le cas de la classification et de la somme pondérée dans le cas de la régression. L'algorithme de boosting le plus utilisé est le boosting adaptatif (Adaboost).
Boosting adaptatif
Les étapes impliquées dans l'algorithme Adaboost sont les suivantes:
- Pour les n points de données donnés, nous définissons la classe cible et initialisons tous les poids à 1 / n.
- Nous adaptons les classificateurs à l'ensemble de données et nous choisissons la classification avec l'erreur de classification la moins pondérée
- Nous attribuons des poids pour le classificateur par une règle empirique basée sur la précision, si la précision est supérieure à 50%, le poids est positif et vice versa.
- Nous mettons à jour les poids des classificateurs à la fin de l'itération; nous mettons à jour plus de poids pour le point mal classé afin que dans la prochaine itération nous le classions correctement.
- Après toute l'itération, nous obtenons le résultat final de la prédiction basé sur le vote majoritaire / la moyenne pondérée.
L'adaboosting fonctionne efficacement avec les apprenants faibles (moins complexes) et avec les classificateurs à biais élevé. Les principaux avantages de Adaboosting sont qu'il est rapide, qu'il n'y a pas de paramètres de réglage similaires au cas de l'ensachage et que nous ne faisons aucune hypothèse sur les apprenants faibles. Cette technique ne parvient pas à fournir un résultat précis lorsque
- Il y a plus de valeurs aberrantes dans nos données.
- L'ensemble de données est insuffisant.
- Les apprenants faibles sont très complexes.
Ils sont également sensibles au bruit. Les arbres de décision produits à la suite de l'amplification auront une profondeur limitée et une grande précision.
Conclusion
Les techniques d'apprentissage d'ensemble sont largement utilisées pour améliorer la précision du modèle; nous devons décider de la technique à utiliser en fonction de notre ensemble de données. Mais ces techniques ne sont pas préférées dans certains cas où l'interprétabilité est importante, car nous perdons l'interprétabilité au détriment de l'amélioration des performances. Ceux-ci ont une importance considérable dans l'industrie des soins de santé où une petite amélioration des performances est très précieuse.
Articles recommandés
Ceci est un guide des techniques d'ensemble. Nous discutons ici de l'introduction et de deux principaux types de techniques d'ensemble. Vous pouvez également consulter nos autres articles connexes pour en savoir plus-
- Techniques de stéganographie
- Techniques d'apprentissage automatique
- Techniques de consolidation d'équipe
- Algorithmes de science des données
- Techniques d'apprentissage en ensemble les plus utilisées