

Introduction au tri dans Tableau
Le tri est une fonctionnalité très importante pour analyser les données. Cela nous aide à organiser les données dans la commande requise, à savoir. croissant ou décroissant, ou basé sur une combinaison de facteurs. Le concept apparemment simple prend de l'importance dans Tableau car les visualisations sont présentées d'une manière particulière en fonction de la méthode de tri appliquée. Dans Tableau, différents arrangements de tri offrent différentes perspectives sur les données via des visualisations. Tableau ne se limite donc pas aux méthodes traditionnelles de tri pour la disposition des données; l'applique plutôt à la visualisation et nous aide à tirer des enseignements des résultats visuels. Dans Tableau, le tri peut être effectué avec plusieurs dimensions.
Tri détaillé dans Tableau avec des illustrations
Maintenant, essayons de comprendre la profondeur offerte pour l'analyse en triant dans Tableau. Pour les démonstrations, nous allons utiliser les données de volume de distribution pour un produit. Les dimensions du tableau sont l'unité de distribution, le code DU, la région, le mode et la ville. Le volume de distribution est une mesure. Une unité de distribution est une unité géographique plus petite que la région.
1. Chargeons d'abord les données. Dans le menu Données, cliquez sur «Nouvelle source de données», ou bien cliquez sur «Se connecter aux données». Les deux options sont présentées dans les deux captures d'écran suivantes. En sélectionnant le type de source de données approprié, chargez les données. Dans ce cas, le type de source de données est Microsoft Excel.
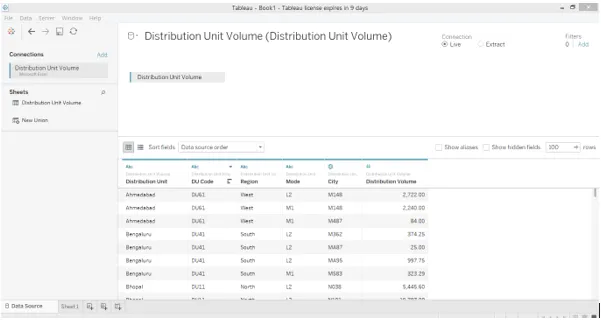
2. Les données sont chargées comme on peut le voir dans l'onglet Source de données comme ci-dessous.
3. Maintenant, passez à l'onglet de feuille. Dans l'onglet de la feuille, nous pouvons voir les dimensions et la mesure sous les sections respectives comme indiqué ci-dessous.
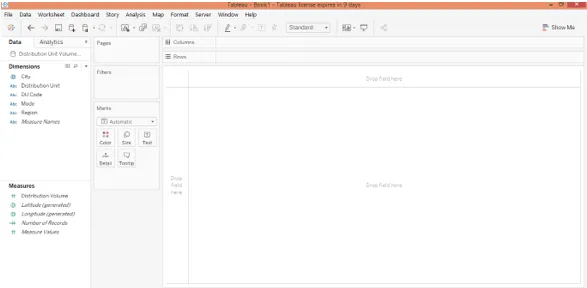
4. Maintenant, faites glisser l'unité de distribution des dimensions et la région dans la région des lignes et mesurez le volume de distribution dans la région des colonnes. Cliquez sur l'icône du graphique à barres horizontales dans «Montrez-moi». La visualisation suivante est générée qui montre le volume de distribution par unité de distribution et également la région à laquelle l'unité de distribution appartient. Initialement, le résultat est trié par ordre alphabétique de la dimension «Unité de distribution».
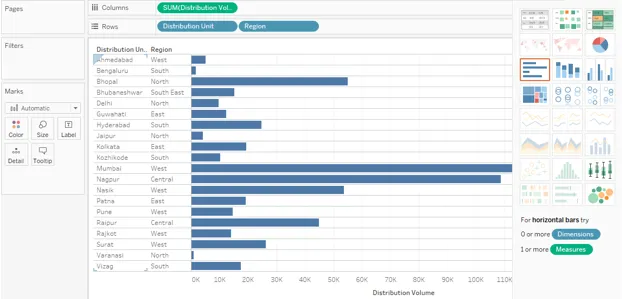
5. Maintenant, nous allons passer par différentes méthodes de tri. L'une des manières les plus simples est illustrée dans la capture d'écran ci-dessous. Cliquez sur le symbole AZ près de l'en-tête de dimension. Par défaut, le résultat est trié par ordre alphabétique des valeurs de dimension. Cliquez sur le symbole pour trier le résultat dans l'ordre alphabétique inverse.
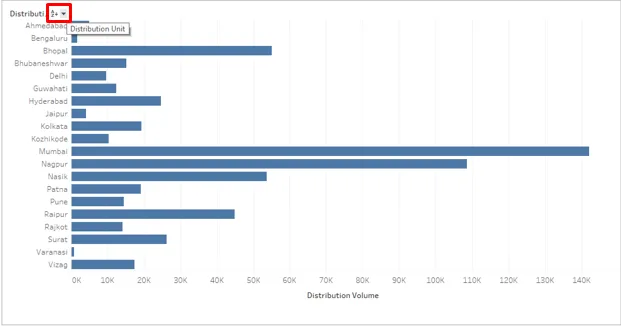
6. Cliquez sur le bouton déroulant comme indiqué dans la capture d'écran ci-dessous. Il y a deux options ici, à savoir. Alphabétique et SUM (Volume de distribution). Ainsi, nous pouvons voir que toutes les méthodes de tri possibles sont fournies car le résultat peut être trié dans l'ordre alphabétique de la dimension ainsi que sur une mesure dans l'ordre croissant ou décroissant. Cliquez sur l'option SUM (Distribution Volume) pour faciliter le tri sur la mesure.
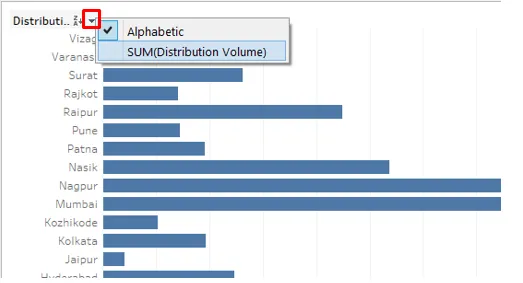
7. En suivant la procédure ci-dessus, le résultat est trié comme suit. Comme on peut le voir, le résultat a été trié dans l'ordre décroissant de la mesure.
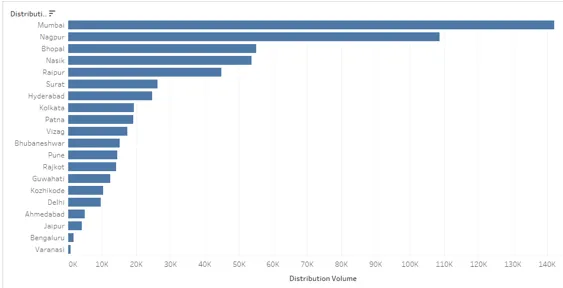
8. Cliquez à nouveau sur le symbole de tri et le résultat est trié dans l'ordre croissant comme ci-dessous. Cliquez à nouveau sur le symbole de tri pour effacer le tri.

9. Le résultat peut également être trié en cliquant sur le symbole de tri comme ci-dessous
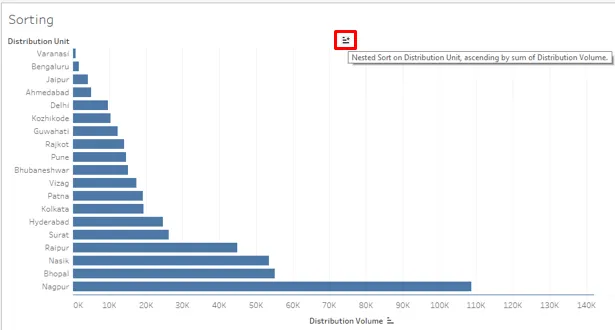
10. Cliquez sur le symbole de tri dans la barre d'outils comme indiqué ci-dessous.
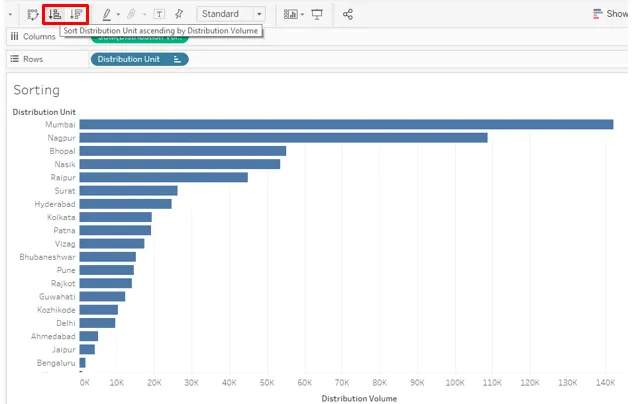
11. Les techniques de tri ci-dessus nous aident à trier les données rapidement et facilement. Maintenant, nous allons essayer de découvrir d'autres options. Dans le menu déroulant de la dimension, cliquez sur «Effacer le tri». Il effacera le type qui a été appliqué précédemment.
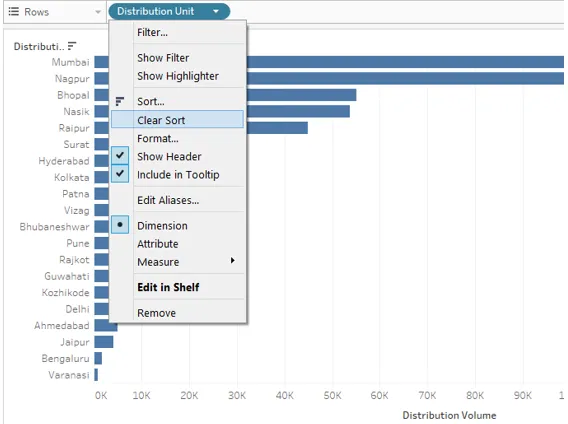
12. Une fois le tri effacé, cliquez sur l'option Trier juste au-dessus de l'option Effacer le tri dans le menu déroulant. Cliquez sur l'option Trier pour générer la boîte de dialogue comme indiqué dans la capture d'écran ci-dessous. Il y a deux options ici, à savoir. «Trier par» et «Ordre de tri». Ils auront en outre plusieurs options. Nous les verrons un par un.
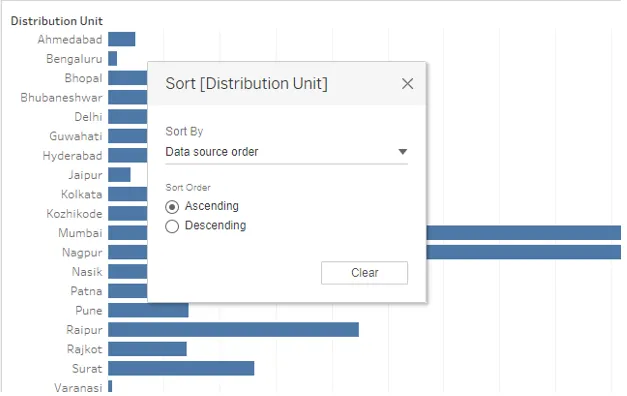
Comme vu ci-dessus, le tri par défaut est «Ordre de la source de données». Cet ordre est essentiellement l'ordre alphabétique.
13. Le menu déroulant Trier par affiche plusieurs options. L'ordre alphabétique trie le résultat par ordre alphabétique des valeurs de dimension. Sélectionnez l'option «Champ» pour explorer plus d'options.
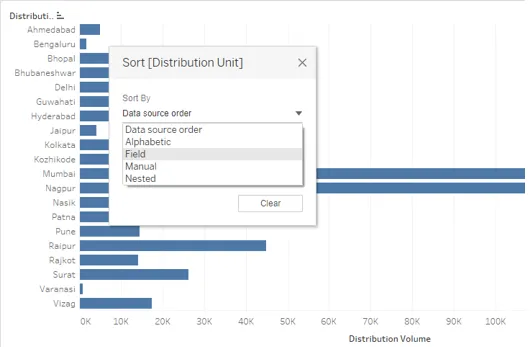
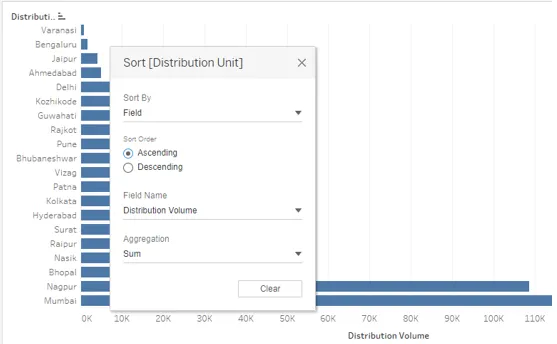
14. Lorsque nous sélectionnons «Champ» dans Trier par, deux autres sections apparaissent dans la boîte de dialogue, qui est «Nom du champ» et «Agrégation». Le nom du champ signifie sur quel champ nous avons l'intention d'appliquer le tri. N'oubliez pas que si un champ n'est pas présent dans la visualisation, même le sélectionner dans la section Nom du champ n'affectera pas le résultat. Dans Agrégation, nous pouvons sélectionner la fonction d'agrégation requise. Cela signifie comment nous aimerions agréger le champ dans le résultat final, par exemple en tant que moyenne ou médiane des valeurs. Nous verrons cela en détail dans la prochaine partie. Initialement, le résultat n'a pas été trié sur la mesure, mais en sélectionnant Croissant dans «Ordre de tri» et Champ dans «Trier par» a trié le résultat dans l'ordre croissant.
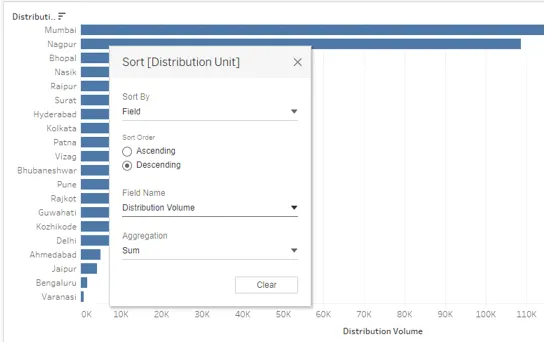
15. Comme indiqué ci-dessous, le résultat a été trié par ordre décroissant. C'est une autre façon de trier les résultats.
16. Dans la section Nom du champ, nous pouvons voir que l'unité de distribution actuelle est sélectionnée. Nous pouvons sélectionner n'importe quel champ selon nos besoins. Assurez-vous simplement que le champ approprié est sélectionné, sinon le résultat incorrect serait renvoyé comme ci-dessous. Ici, l'unité de distribution a été sélectionnée comme valeur de nom de champ et le tri ne s'est pas déroulé comme nous le souhaitons. En effet, l'unité de distribution est une valeur de dimension et non une mesure, c'est-à-dire une variable numérique. Ainsi, par-dessus, Tableau a automatiquement appliqué la fonction Count dans la section Agrégation. Parfois, nous pouvons délibérément appliquer la fonction Count, mais pour qu'elle fonctionne correctement, nous devons considérer quelques éléments que nous verrons dans la partie suivante.
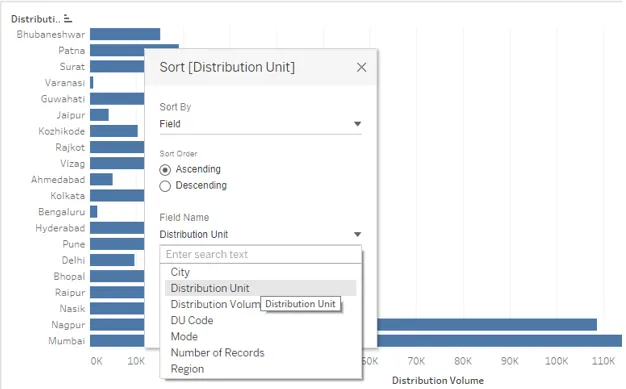
17. La capture d'écran ci-dessous montre diverses fonctions mathématiques / statistiques ou fonctions d'agrégation (dans le langage de la base de données) qui pourraient être appliquées sur la valeur Nom du champ. L'application de la fonction appropriée ne retournera que le bon résultat. Si nous appliquons la fonction Moyenne comme ci-dessous, la valeur moyenne sage Dimension (Unité de Distribution) pour la mesure sera calculée et incorporée dans la sortie. Comme on peut le voir, le résultat n'est pas trié par ordre croissant de la moyenne des valeurs de dimension. Cela est dû au fait que, tout en sélectionnant une fonction d'agrégation dans la boîte de dialogue, nous devons nous assurer que la même fonction d'agrégation est appliquée partout sur la mesure, c'est-à-dire dans la région Colonnes et la carte Marques (si la mesure est présente dans le marque également la carte).
La fonction Médiane calculera la valeur médiane et triera le résultat en conséquence. Le décompte comptera combien de valeurs pour ce champ sont là et basé sur ce décompte le tri aura lieu. Lorsque nous sélectionnons Count (Distinct), le compte de toutes les valeurs ne sera pas pris en compte, mais uniquement des valeurs uniques. Le centile tiendra compte des valeurs inférieures au pourcentage spécifié. Lors de l'application de la fonction sur la mesure dans la région Colonnes ou la carte Repères, la fonction vous demandera de spécifier la valeur en pourcentage. Cependant, dans le cas de la section Agrégation, la valeur par défaut du centile est de 95%. Std. Dev et Variance sont des fonctions statistiques. Std. Dev et Variance concernent les écarts-types et la variance de l'échantillon, tandis que Std. Dev (Pop.) Et Variance (Pop.) Concernent les données démographiques.

18. La capture d'écran suivante montre que la fonction AVG est appliquée sur la mesure (Volume de distribution) dans la région Colonnes. La sélection de Moyenne dans l'agrégation pour le tri, comme dans la capture d'écran précédente, ne fonctionnera que lorsque cette condition est remplie. La fonction d'agrégation aux deux endroits doit être la même pour obtenir le résultat correct.

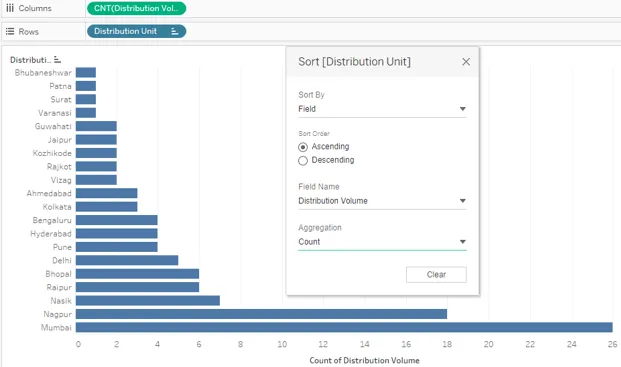
19. Une autre démonstration de la façon dont le tri peut être effectué avec différentes fonctions d'agrégation est présentée ci-dessous. Ici, nous pouvons voir comment la sélection de la fonction CNT, c'est-à-dire du comptage sur la mesure dans la région Colonnes, ainsi que dans la section Agrégation de la boîte de dialogue Trier, nous a donné des résultats triés en fonction du nombre de valeurs pour l'unité de distribution.
20. Nous allons maintenant appliquer la fonction d'écart type dans la section d'agrégation. Comme on peut le voir, la capture d'écran suivante montre comment l'application de la fonction d'écart type STDEV ie a trié le résultat. Comme mentionné, il est essentiel que la même fonction soit appliquée dans la région Colonnes ainsi que dans la section Agrégation. Pour certaines unités de distribution, l'écart type est nul. En effet, l'écart-type prend en compte les écarts au carré de la moyenne.

21. Le résultat du tri via la fonction centile fonctionne en fonction de la valeur du centile sélectionné comme dans la capture d'écran ci-dessous. Choisissons 10 comme valeur centile. Nous verrons si le tri à l'aide de la fonction percentile fonctionne correctement.
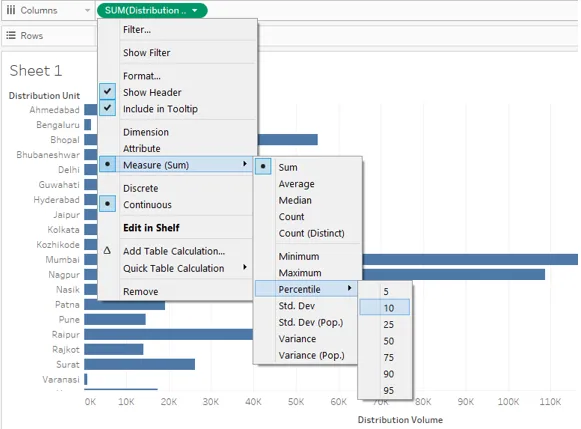
22. Nous avons appliqué la fonction percentile à la fois aux endroits, c'est-à-dire la région des colonnes et la section d'agrégation. Cependant, le résultat n'est pas correct. Remarquez attentivement, sur la mesure, c'est-à-dire le volume de distribution, nous avons appliqué la fonction centile avec la valeur 10, et la valeur centile par défaut pour la fonction centile dans la boîte de dialogue est 95, ce qui a provoqué le décalage.
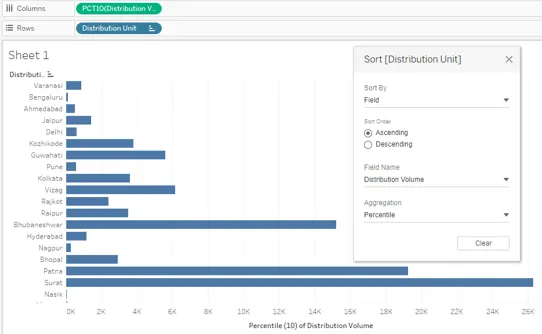
23. Maintenant, nous avons sélectionné 95 comme valeur centile aux deux endroits et nous avons obtenu le résultat correct. La capture d'écran suivante montre le résultat trié obtenu en utilisant correctement la fonction centile.

24. Maintenant, nous allons voir comment fonctionne l'option «Manuel» dans Trier par. Comme son nom l'indique, en utilisant l'option Manual, nous pouvons déplacer vers le haut ou vers le bas une valeur en fonction de la position à laquelle nous le voulons. Ainsi, en faisant glisser la valeur de la dimension vers le haut ou vers le bas, nous pouvons la déplacer selon les besoins et trier le résultat. Le tri manuel peut ne pas être l'option de tri possible lorsqu'il existe plusieurs valeurs pour une dimension, comme plusieurs catégories, etc. La capture d'écran suivante montre comment fonctionne le tri manuel. La ligne noire dans la boîte de dialogue Trier indique que la valeur de dimension juste en dessous est actuellement déplacée.

25. La dernière option dans Trier par est «imbriquée». Dans les versions antérieures de Tableau, le tri imbriqué impliquait des étapes complexes, cependant, il s'agit maintenant d'une option prête à l'emploi, comme le montre la capture d'écran ci-dessous. Le tri imbriqué est utile si nous avons l'intention de trier une dimension dans une autre dimension sur une mesure. Comme ici, nous allons trier la région et l'unité de distribution en fonction du volume de distribution par ordre croissant ou décroissant.
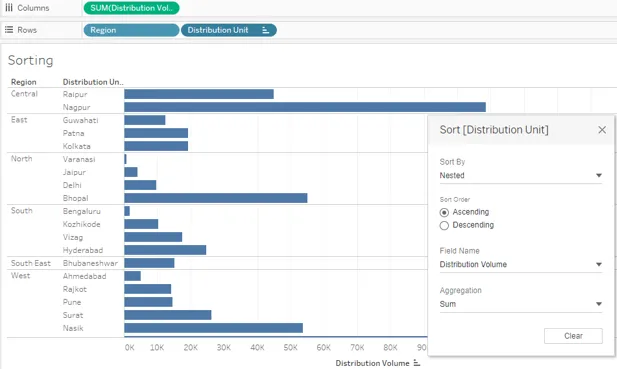
26. Dans les sections précédentes, nous avons vu quelques méthodes standard pour trier les résultats dans Tableau. Nous avons essayé d'explorer tous les angles. Maintenant, nous allons voir une technique de tri non conventionnelle. Cette technique nous permet de trier le résultat d'une manière rapide, comme parfois nous pouvons être intéressés par les valeurs supérieures et inférieures ou minimales et maximales. La méthode est illustrée par la démonstration suivante.
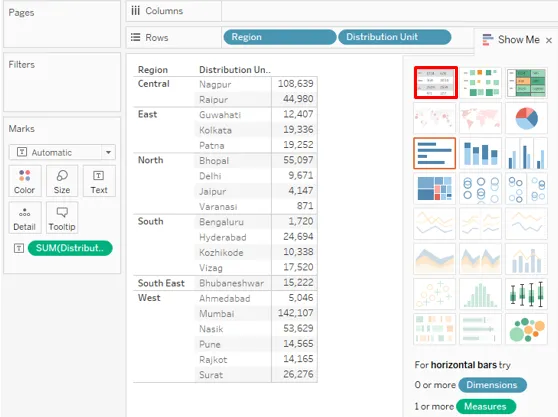
Faites d'abord glisser les dimensions Région et Unité de distribution dans la région Lignes et mesurez le Volume de distribution dans la région Colonnes. Cliquez sur l'icône des tableaux de texte dans l'onglet «Montrez-moi», cela donne le résultat suivant.
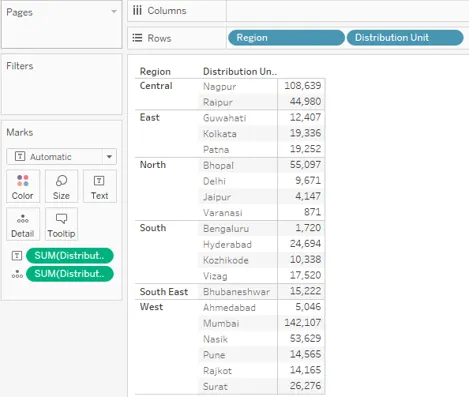
27. Maintenant, faites glisser Distribution Volume pour la deuxième fois. Cette fois, faites-le glisser sur la carte Détail dans les marques, comme indiqué dans la capture d'écran ci-dessous.
28. Modifiez le type de mesure Volume de distribution qui a été glissé sur la carte Détail dans les repères en «Discret» comme indiqué ci-dessous dans la capture d'écran à gauche. La capture d'écran à droite montre que la modification du type de mesure sur Discret fera apparaître la mesure en bleu. Maintenant, la variable discrète peut être utilisée comme dimension.

29. Faites glisser la mesure discrète nouvellement créée dans la région Lignes et placez-la avant la dimension Région. Comme on peut le voir, directement, nous avons obtenu le résultat trié. Le résultat a été trié dans l'ordre croissant de la mesure discrète «Volume de distribution».

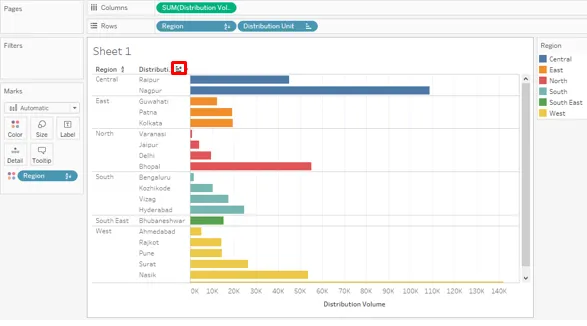
30. Si nous voulons visualiser le volume de distribution par unité de distribution en fonction des régions dans lesquelles ils se trouvent, triés de manière appropriée, nous pouvons suivre la procédure ci-dessous. Dans un premier temps, nous allons faire glisser les dimensions Région et Unité de distribution dans la région Lignes et mesurer le Volume de distribution dans la région Colonnes. Cela créera des groupes par région. Pour distinguer chaque groupe, nous allons faire glisser Région sur Couleur dans la fiche Repères. Pour trier le résultat dans chaque groupe, nous cliquerons sur le symbole de tri près de l'en-tête de dimension, c'est-à-dire l'unité de distribution. Les résultats seront triés séparément dans chaque groupe, comme le montre la capture d'écran suivante.
Conclusion
Le tri est un outil très essentiel pour l'analyse des données. Tableau propose différentes manières de trier le résultat du plus simple au plus complexe, en combinant plusieurs facteurs. Les options exhaustives offertes par Tableau pour trier les données et les visualiser de manière dynamique confèrent à Tableau un caractère unique.
Articles recommandés
Il s'agit d'un guide de tri dans Tableau. Nous discutons ici de l'introduction et des illustrations détaillées du tri dans le tableau. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Graphique à bulles dans Tableau
- Fonction LOOKUP dans Tableau
- Graphique à barres empilées dans Tableau
- Carte de chaleur dans Tableau
- Guide complet de tri en C # avec des exemples
- Tri en Python
- Comment le graphique à barres est utilisé dans Matlab (exemples)