

Introduction à Join dans Spark SQL
Comme nous le savons, les jointures en SQL sont utilisées pour combiner des données ou des lignes de deux tables ou plus en fonction d'un champ commun entre elles. Dans cette rubrique, nous allons en savoir plus sur Join in Spark SQL Join in Spark SQL.
Dans Spark SQL, Dataframe ou Dataset sont une structure tabulaire en mémoire comportant des lignes et des colonnes réparties sur plusieurs nœuds. Comme les tables SQL normales, nous pouvons également effectuer des opérations de jointure sur Dataframe ou Dataset présents dans Spark SQL en fonction d'un champ commun entre eux.
Il existe différents types d'opérations de jointure disponibles dans SQL. En fonction du cas d'utilisation métier, nous faisons le choix de l'opération Join. Dans la section suivante, nous allons montrer chaque type de jointure avec un exemple.
Types de jointure dans Spark SQL
Voici les différents types de jointures disponibles dans Spark SQL:
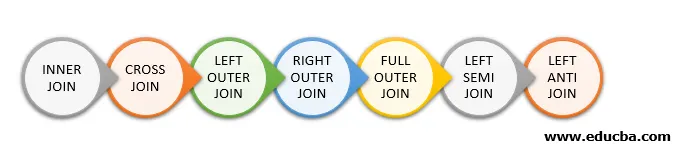
- JOINTURE INTERNE
- CROSS JOIN
- JOINTURE EXTERNE GAUCHE
- JOINT EXTERIEUR DROIT
- JOINTURE EXTÉRIEURE COMPLÈTE
- SEMI-JOIN GAUCHE
- GAUCHE ANTI JOIN
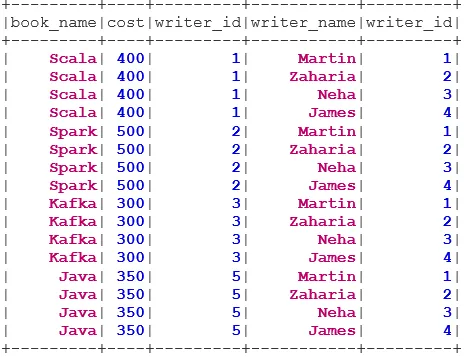
Exemple de création de données
Nous utiliserons les données suivantes pour illustrer les différents types de jointures:
Livre de données du livre:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer Dataset:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Types de jointures
Ci-dessous sont mentionnés 7 types différents de jointures:
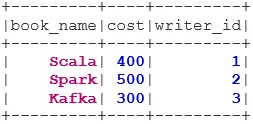
1. INNER JOIN
L'INNER JOIN renvoie l'ensemble de données dont les lignes ont des valeurs correspondantes dans les deux ensembles de données, c'est-à-dire que la valeur du champ commun sera la même.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
CROSS JOIN renvoie l'ensemble de données qui est le nombre de lignes du premier ensemble de données multiplié par le nombre de lignes du deuxième ensemble de données. Ce type de résultat est appelé le produit cartésien.
Condition préalable: pour utiliser une jointure croisée, spark.sql.crossJoin.enabled doit être défini sur true. Sinon, l'exception sera levée.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. JOINT EXTERIEUR GAUCHE
LEFT OUTER JOIN renvoie l'ensemble de données contenant toutes les lignes de l'ensemble de données de gauche et les lignes correspondantes de l'ensemble de données de droite.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. JOINTURE EXTERNE DROITE
RIGHT OUTER JOIN renvoie l'ensemble de données qui contient toutes les lignes de l'ensemble de données de droite et les lignes correspondantes de l'ensemble de données de gauche.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. JOINTURE EXTÉRIEURE COMPLÈTE
FULL OUTER JOIN renvoie l'ensemble de données qui contient toutes les lignes lorsqu'il existe une correspondance dans l'ensemble de données gauche ou droit.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. SEMI-JOINT GAUCHE
LEFT SEMI JOIN renvoie l'ensemble de données qui contient toutes les lignes de l'ensemble de données de gauche ayant leur correspondance dans l'ensemble de données de droite. Contrairement à LEFT OUTER JOIN, l'ensemble de données renvoyé dans LEFT SEMI JOIN ne contient que les colonnes de l'ensemble de données de gauche.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. GAUCHE ANTI JOIN
L'ANTI SEMI JOIN renvoie l'ensemble de données qui contient toutes les lignes de l'ensemble de données de gauche qui n'ont pas leur correspondance dans l'ensemble de données de droite. Il contient également uniquement les colonnes de l'ensemble de données de gauche.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusion - Rejoignez Spark SQL
La jonction de données est l'une des opérations les plus courantes et les plus importantes pour répondre à notre cas d'utilisation commerciale. Spark SQL prend en charge tous les types fondamentaux de jointures. Lors de l'adhésion, nous devons également prendre en compte les performances, car elles peuvent nécessiter des transferts réseau importants ou même créer des ensembles de données au-delà de notre capacité à gérer. Pour améliorer les performances, Spark utilise l'optimiseur SQL pour réorganiser ou pousser les filtres. Spark restreint également la jointure dangereuse i. e CROSS JOIN. Pour utiliser une jointure croisée, spark.sql.crossJoin.enabled doit être défini sur true explicitement.
Articles recommandés
Ceci est un guide pour rejoindre Spark SQL. Nous discutons ici des différents types de jointures disponibles dans Spark SQL avec l'exemple. Vous pouvez également consulter l'article suivant.
- Types de jointures dans SQL
- Table en SQL
- Requête d'insertion SQL
- Transactions en SQL
- Filtres PHP | Comment valider l'entrée utilisateur à l'aide de divers filtres?