

Introduction à la machine Boltzmann restreinte
La machine Boltzmann restreinte est une méthode qui peut trouver automatiquement des modèles dans les données en reconstruisant notre entrée. Geoff Hinton est le fondateur du deep learning. RBM est un réseau superficiel à deux couches dans lequel le premier est visible et le suivant est la couche cachée. Chaque nœud unique de la couche visible est joint à chaque nœud unique de la couche cachée. La machine Boltzmann restreinte est considérée comme restreinte car deux nœuds de la même couche ne forment pas de connexion. Un RBM est l'équivalent numérique d'un traducteur bidirectionnel. Dans le chemin aller, un RBM reçoit l'entrée et la convertit en un ensemble de nombres qui code l'entrée. Dans le chemin vers l'arrière, il prend cela comme résultat et traite cet ensemble d'entrées et les traduit en sens inverse pour former les entrées retracées. Un réseau super-formé pourra effectuer cette transition inverse avec une grande véracité. En deux étapes, le poids et les valeurs ont un rôle très important. Ils permettent à RBM de décoder les interrelations entre les entrées et aident également RBM à décider quelles valeurs d'entrée sont les plus importantes pour détecter les sorties correctes.
Travail de la machine Boltzmann restreinte
Chaque nœud visible unique reçoit une valeur de bas niveau d'un nœud de l'ensemble de données. Au premier nœud de la couche invisible, X est formé par un produit de poids et ajouté à un biais. Le résultat de ce processus est transmis à l'activation qui produit la puissance du signal d'entrée donné ou de la sortie du nœud.
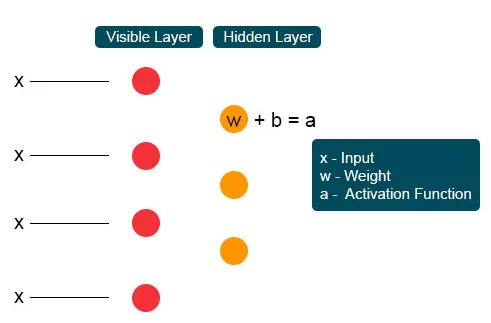
Dans le processus suivant, plusieurs entrées se joindraient à un seul nœud caché. Chaque X est combiné par le poids individuel, l'ajout du produit est matraqué aux valeurs et encore une fois le résultat est transmis par activation pour donner la sortie du nœud. À chaque nœud invisible, chaque entrée X est combinée par un poids individuel W. L'entrée X a ici trois poids, ce qui en fait douze ensemble. Le poids formé entre la couche devient un tableau où les lignes sont précises pour les nœuds d'entrée et les colonnes sont satisfaites pour les nœuds de sortie.
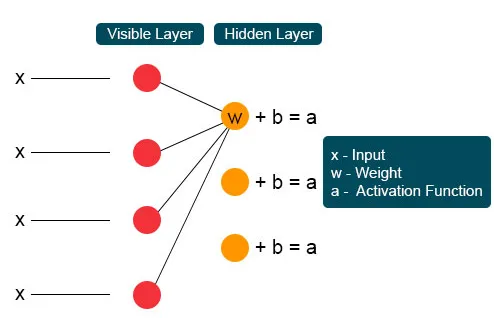
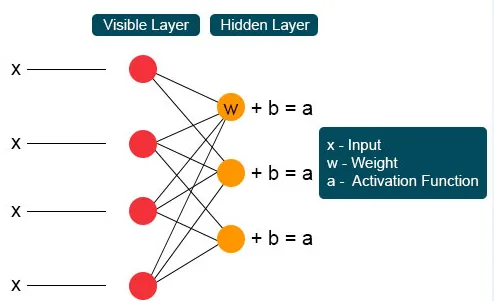
Chaque nœud invisible obtient quatre réponses multipliées par leur poids. L'ajout de cet effet est à nouveau ajouté à la valeur. Cela agit comme un catalyseur pour qu'un processus d'activation se produise et le résultat est à nouveau transmis à l'algorithme d'activation qui produit chaque sortie unique pour chaque entrée invisible.
Le premier modèle dérivé ici est le modèle basé sur l'énergie. Ce modèle associe l'énergie scalaire à chaque configuration de la variable. Ce modèle définit la distribution de probabilité à travers une fonction d'énergie comme suit,
(1) 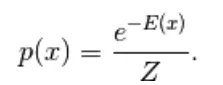
Ici, Z est le facteur de normalisation. C'est la fonction de partition en termes de systèmes physiques
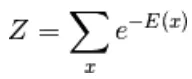
Dans cette fonction basée sur l'énergie suit une régression logistique que la première étape définira le log-. la probabilité et la suivante définiront la fonction de perte comme étant une probabilité négative.
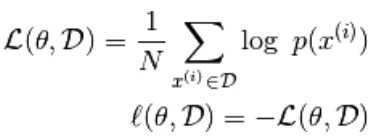
en utilisant le gradient stochastique, 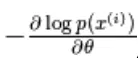 où
où 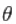 sont les paramètres,
sont les paramètres,
le modèle basé sur l'énergie avec une unité cachée est défini comme «h»
La partie observée est notée «x»
D'après l'équation (1), l'équation de l'énergie libre F (x) est définie comme suit
(2) 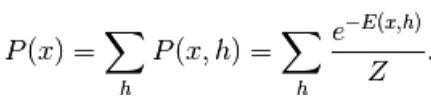
(3) 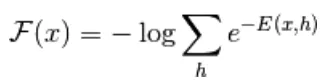
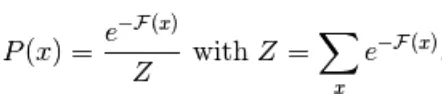
Le gradient négatif a la forme suivante,
(4) 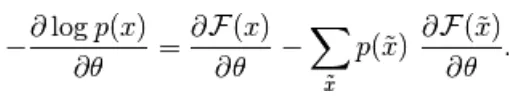
L'équation ci-dessus a deux formes, la forme positive et la forme négative. Le terme positif et négatif n'est pas représenté par les signes des équations. Ils montrent l'effet de la densité de probabilité. La première partie montre la probabilité de réduire l'énergie libre correspondante. La deuxième partie montre la réduction de la probabilité d'échantillons générés. Ensuite, le gradient est déterminé comme suit,
(5) 
Ici, N est des particules négatives. Dans ce modèle basé sur l'énergie, il est difficile d'identifier analytiquement le gradient, car il inclut le calcul de 
Par conséquent, dans ce modèle EBM, nous avons une observation linéaire qui n'est pas en mesure de représenter les données avec précision. Ainsi, dans le prochain modèle restreint Boltzmann Machine, la couche cachée a davantage de précision et de prévention de la perte de données. La fonction d'énergie RBM est définie comme:
(6) 
Ici, W est le poids qui relie les couches visibles et cachées. b est le décalage du calque visible.c est le décalage du calque masqué. en convertissant en énergie libre,
Dans RBM, les unités de la couche visible et cachée sont complètement indépendantes, ce qui peut être écrit comme suit,
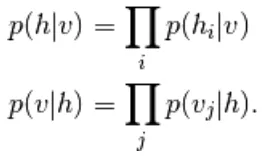
De l'équation 6 et 2, une version probabiliste de la fonction d'activation des neurones,
(sept) 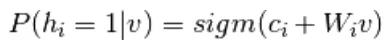
(8) 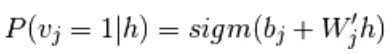
Il est encore simplifié en
(9) 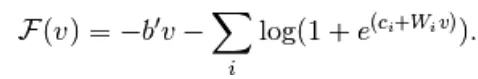
Combinant les équations 5 et 9,
(dix) 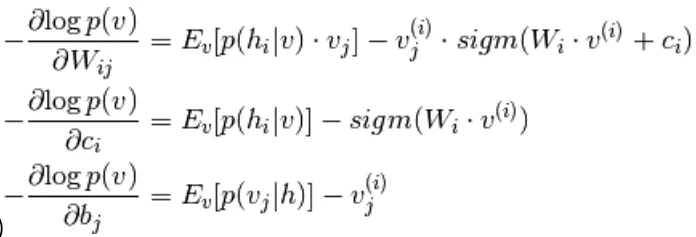
Échantillonnage dans une machine Boltzmann restreinte
Échantillonnage de Gibbs du joint de N variables aléatoires 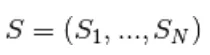 se fait par une séquence de N sous-étapes d'échantillonnage du formulaire
se fait par une séquence de N sous-étapes d'échantillonnage du formulaire 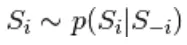 où
où
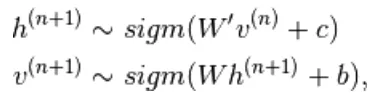
contient 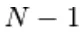 les autres variables aléatoires
les autres variables aléatoires 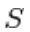 à l'exclusion.
à l'exclusion. 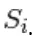
Dans RBM, S est un ensemble d'unités visibles et cachées. Les deux parties sont indépendantes, ce qui peut effectuer ou bloquer l'échantillonnage de Gibbs. Ici, l'unité visible effectue l'échantillonnage et donne une valeur fixe aux unités cachées, les unités cachées simultanément fournissant des valeurs fixes à l'unité visible par échantillonnage
ici, 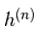 est un ensemble de toutes les unités cachées. Un exemple
est un ensemble de toutes les unités cachées. Un exemple 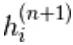 est choisi au hasard pour être 1 (contre 0) avec probabilité,
est choisi au hasard pour être 1 (contre 0) avec probabilité, 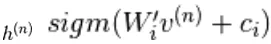 et de même,
et de même, 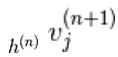 est choisi au hasard pour être 1 (contre 0) avec probabilité
est choisi au hasard pour être 1 (contre 0) avec probabilité 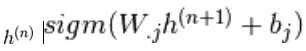
Divergence contrastée
Il est utilisé comme catalyseur pour accélérer le processus d'échantillonnage
Puisque nous nous attendons à être vrai, nous nous attendons à 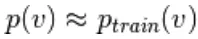 la valeur de distribution doit être proche de P de sorte qu'elle forme une convergence vers la distribution finale de P
la valeur de distribution doit être proche de P de sorte qu'elle forme une convergence vers la distribution finale de P
Mais la divergence contrastée n'attend pas que la chaîne converge. L'échantillon n'est obtenu qu'après le processus de Gibb, nous avons donc fixé ici k = 1 où cela fonctionne étonnamment bien.
Divergence contrastée persistante
Il s'agit d'une autre méthode de formulaire d'échantillonnage d'approximation. C'est un état persistant pour chaque méthode d'échantillonnage, il extrait de nouveaux échantillons en changeant simplement les paramètres de K.
Couches de la machine Boltzmann restreinte
La machine Boltzmann restreinte a deux couches, des réseaux de neurones peu profonds qui se combinent pour former un bloc de réseaux de croyances profondes. La première couche est la couche visible et l'autre couche est la couche cachée. Chaque unité fait référence à un cercle de type neurone appelé nœud. Les nœuds de la couche cachée sont connectés aux nœuds de la couche visible. Mais deux nœuds de la même couche ne sont pas connectés. Ici, le terme restreint fait référence à aucune communication intracouche. Chaque nœud traite l'entrée et prend la décision stochastique de transmettre ou non l'entrée.
Exemples
Le rôle important de la GAR est une distribution de probabilité. Les langues sont uniques dans leurs lettres et leurs sons. La distribution de probabilité de la lettre peut être élevée ou faible. En anglais, les lettres T, E et A sont largement utilisées. Mais en islandais, les lettres courantes sont A et N. nous ne pouvons pas essayer de reconstruire l'islandais avec un poids basé sur l'anglais. Cela conduira à des divergences.
L'exemple suivant est celui des images. La distribution de probabilité de leur valeur en pixels diffère pour chaque type d'image. Nous pouvons considérer qu'il y a deux images Elephant et Dog pour les nœuds d'entrée de remorquage, la passe avant de RBM générera une question comme dois-je générer un nœud de pixel fort pour le nœud d'éléphant ou le nœud de chien?. Ensuite, le passage en arrière générera des questions comme pour l'éléphant, comment dois-je m'attendre à une distribution de pixels? Ensuite, avec une probabilité et une activation conjointes produites par les nœuds, ils construiront un réseau avec une co-occurrence conjointe comme de grandes oreilles, un tube gris non linéaire, des oreilles souples, la ride est l'éléphant. Par conséquent, la GAR est le processus d'apprentissage en profondeur et de visualisation, ils forment deux biais majeurs et agissent sur leur sens d'activation et de reconstruction.
Avantages de la machine Boltzmann restreinte
- La machine Boltzmann restreinte est un algorithme appliqué utilisé pour la classification, la régression, la modélisation de sujets, le filtrage collaboratif et l'apprentissage des fonctionnalités.
- La machine Boltzmann restreinte est utilisée pour la neuroimagerie, la reconstruction d'images clairsemées dans la planification de mines et également dans la reconnaissance de cibles radar
- RBM capable de résoudre le problème de données déséquilibrées par la procédure SMOTE
- RBM trouve des valeurs manquantes par l'échantillonnage de Gibb qui est appliqué pour couvrir les valeurs inconnues
- RBM surmonte le problème des étiquettes bruyantes par des données d'étiquette non corrigées et ses erreurs de reconstruction
- Le problème des données non structurées est corrigé par l'extracteur de fonctionnalités qui transforme les données brutes en unités cachées.
Conclusion
L'apprentissage en profondeur est très puissant qui est l'art de résoudre des problèmes complexes, il reste une pièce à améliorer et complexe à mettre en œuvre. Les variables libres doivent être configurées avec soin. Les idées derrière le réseau de neurones étaient difficiles auparavant, mais aujourd'hui, l'apprentissage en profondeur est le pied de l'apprentissage automatique et de l'intelligence artificielle. RBM donne donc un aperçu des énormes algorithmes d'apprentissage en profondeur. Il traite de l'unité de base de la composition qui est progressivement devenue de nombreuses architectures populaires et largement utilisée dans de nombreuses industries à grande échelle.
Article recommandé
Cela a été un guide pour la machine Boltzmann restreinte. Nous discutons ici de son fonctionnement, de l'échantillonnage, des avantages et des couches de la machine Boltzmann restreinte. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus _
- Algorithmes d'apprentissage automatique
- Architecture d'apprentissage automatique
- Types d'apprentissage automatique
- Outils d'apprentissage machine
- Implémentation de réseaux de neurones