

Différence entre Hadoop et Hive
Hadoop:
Hadoop est un Framework ou un logiciel qui a été inventé pour gérer des données volumineuses ou Big Data. Hadoop est utilisé pour stocker et traiter les grandes données réparties sur un cluster de serveurs de base.
Hadoop stocke les données à l'aide du système de fichiers distribué Hadoop et les traite / interroge à l'aide du modèle de programmation Map Reduce.
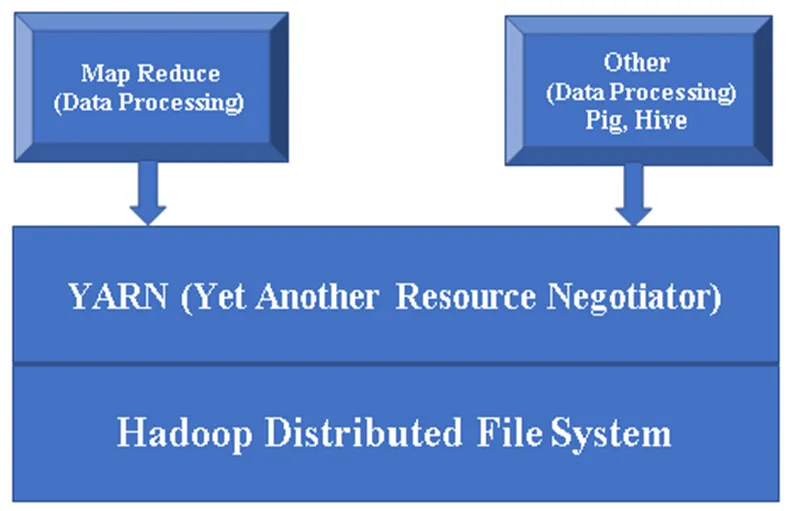
Figure 1, une architecture de base d'un composant Hadoop.
Composants majeurs de Hadoop:
Hadoop Base / Common: Hadoop common vous fournira une plate-forme pour installer tous ses composants.
HDFS (Hadoop Distributed File System): HDFS est une partie importante du framework Hadoop, il prend en charge toutes les données de Hadoop Cluster. Il fonctionne sur l'architecture maître / esclave et stocke les données à l'aide de la réplication.
Architecture et réplication maître / esclave:
- Nœud maître / nœud de nom: le nœud de nom stocke les métadonnées de chaque bloc / fichier stocké dans HDFS, HDFS ne peut avoir qu'un seul nœud maître (en cas de HA, un autre nœud maître fonctionnera comme nœud maître secondaire).
- Nœud esclave / nœud de données: les nœuds de données contiennent des fichiers de données réels en blocs. HDFS peut avoir plusieurs nœuds de données.
- Réplication: HDFS stocke ses données en les divisant en blocs. La taille de bloc par défaut est de 64 Mo. En raison de la réplication, les données sont stockées dans 3 nœuds de données différents (le facteur de réplication par défaut peut être augmenté selon les besoins), d'où la moindre possibilité de perdre les données en cas de défaillance d'un nœud.
YARN (Yet Another Resource Negotiator): Il est essentiellement utilisé pour gérer les ressources Hadoop et joue également un rôle important dans la planification de l'application des utilisateurs.
MR (Map Reduce): Il s'agit du modèle de programmation de base de Hadoop. Il est utilisé pour traiter / interroger les données dans le cadre Hadoop.
Ruche:
Hive est une application qui s'exécute sur le framework Hadoop et fournit une interface de type SQL pour le traitement / requête des données. Hive est conçu et développé par Facebook avant de faire partie du projet Apache-Hadoop.
Hive exécute sa requête à l'aide de HQL (langage de requête Hive). Hive a la même structure que le SGBDR et presque les mêmes commandes peuvent être utilisées dans Hive.
Hive peut stocker les données dans des tables externes, il n'est donc pas obligatoire d'utiliser HDFS, il prend également en charge les formats de fichiers tels que ORC, fichiers Avro, fichiers de séquence et fichiers texte, etc.
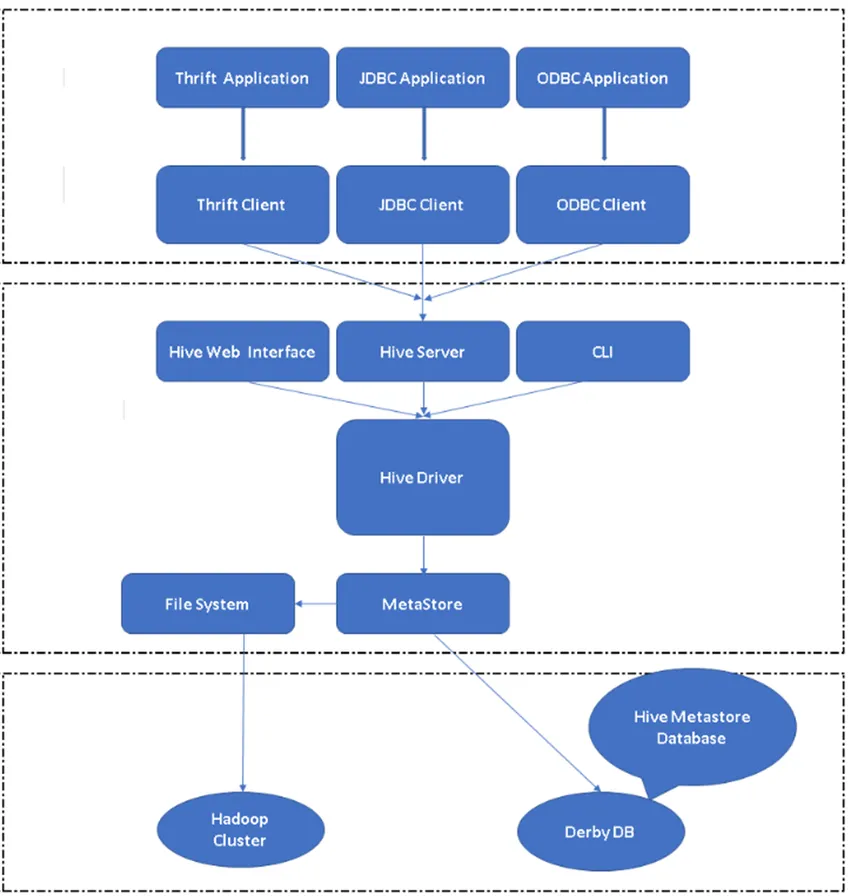
Figure 2, Architecture de Hive et ses principaux composants.
Composante principale de la ruche:
Clients Hive: non seulement SQL, Hive prend également en charge des langages de programmation tels que Java, C, Python à l'aide de divers pilotes tels que ODBC, JDBC et Thrift. On peut écrire n'importe quelle application client de ruche dans d'autres langues et peut s'exécuter dans Hive en utilisant ces clients.
Services Hive: sous les services Hive, l'exécution des commandes et des requêtes a lieu. L'interface Web Hive comporte cinq sous-composants.
- CLI: interface de ligne de commande par défaut fournie par Hive pour l'exécution des requêtes / commandes Hive.
- Hive Web Interfaces: Il s'agit d'une interface utilisateur graphique simple. C'est une alternative à la ligne de commande Hive et utilisée pour exécuter les requêtes et les commandes dans l'application Hive.
- Hive Server: Il est également appelé Apache Thrift. Il est responsable de prendre des commandes à partir d'interfaces de ligne de commande différentes et différentes et de soumettre toutes les commandes / requêtes à Hive. Il récupère également le résultat final.
- Pilote Apache Hive: il est responsable de prendre les entrées de l'interface CLI, de l'interface utilisateur Web, ODBC, JDBC ou Thrift par un client et de transmettre les informations au métastore où toutes les informations du fichier sont stockées.
- Metastore: Metastore est un référentiel pour stocker toutes les informations de métadonnées Hive. Les métadonnées de Hive stockent les informations telles que la structure des tables, les partitions et le type de colonne, etc.
Stockage Hive: Il s'agit de l'emplacement où la tâche réelle est exécutée. Toutes les requêtes qui s'exécutent à partir de Hive ont effectué l'action dans le stockage Hive.
Comparaison directe entre Hadoop et Hive (infographie)
Voici la différence entre les 8 meilleurs Hadoop et Hive
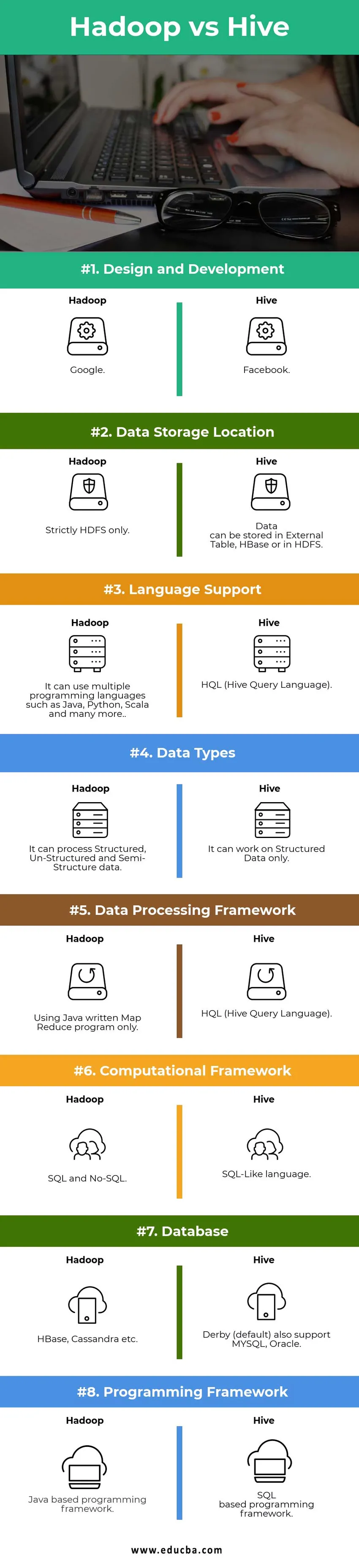
Différences clés entre Hadoop et Hive:
Voici les listes de points, décrivez les principales différences entre Hadoop et Hive:
1) Hadoop est un cadre pour traiter / interroger les Big Data tandis que Hive est un outil basé sur SQL qui s'appuie sur Hadoop pour traiter les données.
2) Hive traite / interroge toutes les données en utilisant HQL (Hive Query Language) c'est un langage de type SQL tandis que Hadoop ne peut comprendre que Map Reduce.
3) Map Reduce fait partie intégrante de Hadoop, la requête de Hive est d'abord convertie en Map Reduce que traitée par Hadoop pour interroger les données.
4) Hive fonctionne sur une requête SQL Like tandis que Hadoop la comprend en utilisant uniquement la réduction de carte basée sur Java.
5) Dans Hive, les commandes traditionnelles des «bases de données relationnelles» utilisées précédemment peuvent également être utilisées pour interroger les données volumineuses tandis que dans Hadoop, il faut écrire des programmes Map Reduce complexes en utilisant Java qui n'est pas similaire à Java traditionnel.
6) Hive peut uniquement traiter / interroger les données structurées tandis que Hadoop est destiné à tous les types de données, qu'elles soient structurées, non structurées ou semi-structurées.
7) En utilisant Hive, on peut traiter / interroger les données sans programmation complexe tandis que dans l'écosystème Simple Hadoop, il faut écrire un programme Java complexe pour les mêmes données.
8) Les frameworks Hadoop d'un côté ont besoin d'une ligne de 100 s pour préparer un programme MR basé sur Java.
9) Dans Hive, il est très difficile d'insérer la sortie d'une requête comme entrée d'une autre alors que la même requête peut être effectuée facilement en utilisant Hadoop avec MR.
10) Il n'est pas obligatoire d'avoir Metastore dans le cluster Hadoop tandis que Hadoop stocke toutes ses métadonnées dans HDFS (Hadoop Distributed File System).
Tableau de comparaison Hadoop vs Hive
| Points de comparaison | Ruche | Hadoop |
|
Design et développement | ||
| Emplacement de stockage des données |
Les données peuvent être stockées dans External Table, HBase ou en HDFS. | Strictement HDFS uniquement. |
| Support linguistique | HQL (Hive Query Language) |
Il peut utiliser plusieurs langages de programmation tels que Java, Python, Scala et bien d'autres. |
| Types de données | Il ne peut fonctionner que sur les données structurées. |
Il peut traiter des données structurées, non structurées et semi-structurées. |
| Cadre de traitement des données |
HQL (Hive Query Language) | Utilisation du programme Map Reduce écrit en Java uniquement. |
|
Cadre de calcul | Langage de type SQL. | SQL et No-SQL. |
| Base de données |
Derby (par défaut) prend également en charge MYSQL, Oracle… | HBase, Cassandra etc…. |
| Cadre de programmation |
Cadre de programmation basé sur SQL. | Cadre de programmation basé sur Java. |
Conclusion - Hadoop vs Hive
Hadoop et Hive sont tous deux utilisés pour traiter les Big Data. Hadoop est un cadre qui fournit une plate-forme à d'autres applications pour interroger / traiter les Big Data tandis que Hive est juste une application basée sur SQL qui traite les données en utilisant HQL (Hive Query Language)
Hadoop peut être utilisé sans Hive pour traiter les mégadonnées alors qu'il n'est pas facile d'utiliser Hive sans Hadoop.
En conclusion, nous ne pouvons comparer Hadoop et Hive de toute façon et sous aucun aspect. Hadoop et Hive sont complètement différents. L'exécution conjointe des deux technologies peut rendre le processus de requête Big Data beaucoup plus facile et confortable pour les utilisateurs Big Data.
Articles recommandés:
Ceci a été un guide pour Hadoop vs Hive, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Hadoop vs Apache Spark - Choses intéressantes que vous devez savoir
- HADOOP vs RDBMS | Connaître les 12 différences utiles
- Comment le Big Data change le visage des soins de santé
- Top 12 Comparaison d'Apache Hive vs Apache HBase (Infographie)
- Guide incroyable sur Hadoop vs Spark