

Qu'est-ce que l'algorithme de stimulation?
Le boost est la méthode des algorithmes qui convertit l'apprenant faible en apprenant fort. Il s'agit d'une technique qui ajoute de nouveaux modèles pour corriger les erreurs des modèles existants.
Exemple:
Comprenons ce concept à l'aide de l'exemple suivant. Prenons un exemple de l'e-mail. Comment allez-vous reconnaître votre e-mail, qu'il s'agisse de spam ou non? Vous pouvez le reconnaître par les conditions suivantes:
- Si un e-mail contient beaucoup de sources, cela signifie qu'il s'agit de spam.
- Si un e-mail ne contient qu'une seule image de fichier, il s'agit d'un spam.
- Si un e-mail contient le message «Vous possédez une loterie de $ xxxxx», cela signifie qu'il s'agit d'un spam.
- Si un e-mail contient une source connue, ce n'est pas du spam.
- S'il contient le domaine officiel comme educba.com, etc., cela signifie qu'il ne s'agit pas d'un spam.
Les règles susmentionnées ne sont pas très puissantes pour reconnaître le spam ou non, par conséquent, ces règles sont appelées des apprenants faibles.
Pour convertir un apprenant faible en apprenant fort, combinez la prédiction de l'apprenant faible en utilisant les méthodes suivantes.
- Utilisation de la moyenne ou de la moyenne pondérée.
- Considérez que la prédiction a un vote plus élevé.
Considérez les 5 règles mentionnées ci-dessus, il y a 3 votes pour le spam et 2 votes pour le non spam. Puisqu'il y a du spam à vote élevé, nous le considérons comme du spam.
Comment fonctionne le boosting des algorithmes?
Boosting Algorithms combine chaque apprenant faible pour créer une règle de prédiction solide. Pour identifier la règle faible, il existe un algorithme d'apprentissage de base (Machine Learning). Chaque fois que l'algorithme de base est appliqué, il crée de nouvelles règles de prédiction à l'aide du processus d'itération. Après une certaine itération, il combine toutes les règles faibles pour créer une seule règle de prédiction.
Pour choisir la bonne distribution, suivez les étapes ci-dessous:
Étape 1: l'algorithme d'apprentissage de base combine chaque distribution et applique un poids égal à chaque distribution.
Étape 2: Si une prédiction se produit pendant le premier algorithme d'apprentissage de base, nous accordons une grande attention à cette erreur de prédiction.
Étape 3: Répétez l'étape 2 jusqu'à ce que la limite de l'algorithme d'apprentissage de base soit atteinte ou haute précision.
Étape 4: Enfin, il combine tous les apprenants faibles pour créer une tule de prédiction forte.
Types d'algorithme de stimulation
Les algorithmes de stimulation utilisent différents moteurs tels que le tampon de décision, l'algorithme de classification de maximisation de marge, etc. Il existe trois types d'algorithmes de stimulation qui sont les suivants:
- Algorithme AdaBoost (Adaptive Boosting)
- Algorithme de renforcement du gradient
- Algorithme XG Boost
Algorithme AdaBoost (Boosting Adaptatif)
Pour comprendre AdaBoost, veuillez vous référer à l'image ci-dessous:
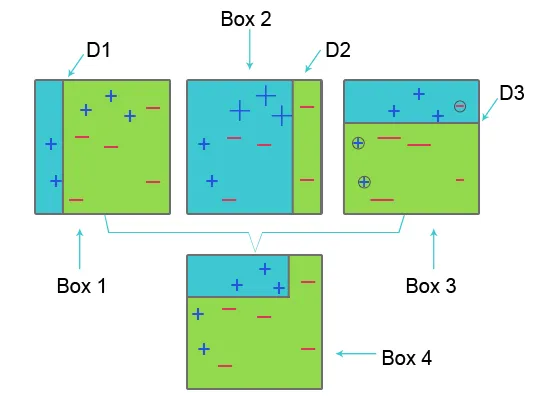
Case 1: Dans la case 1 pour chaque ensemble de données, nous avons attribué des poids égaux et pour classer le signe plus (+) et moins (-), nous appliquons le moignon de décision D1 qui crée une ligne verticale sur le côté gauche de la case 1. Cette ligne est incorrecte prédit trois signe plus (+) comme moins (-), donc nous appliquons des poids plus élevés à ces signes plus et appliquons un autre moignon de décision.
Encadré 2: Dans l'encadré 2, la taille de trois signes plus (+) incorrectement prédits augmente par rapport à un autre. Le deuxième moignon de décision D2 sur le côté droit du bloc prédit que ce signe plus incorrectement prédit (+) est correct. Mais comme une erreur de classification s'est produite en raison du poids inégal avec un signe moins (-), nous attribuons un poids plus élevé à un signe moins (-) et appliquons un autre moignon de décision.
Encadré 3: dans l'encadré trois en raison d'une erreur de classification erronée, le signe moins (-) a un poids élevé. ici, le moignon de décision D3 est appliqué pour prédire cette erreur de classification et la corriger. Cette fois pour classer le signe plus (+) et le signe moins (-), une ligne horizontale est créée.
Encadré 4: Dans l'encadré 4, les souches de décision D1, D2 et D3 sont combinées pour créer une nouvelle prédiction forte.
Les travaux de boosting adaptatif sont similaires à ceux mentionnés ci-dessus. Il combine le groupe d'apprenants faibles en fonction de l'âge du poids pour créer un apprenant fort. Dans la première itération, il donne un poids égal à chaque ensemble de données et commence à prédire cet ensemble de données. Si une prédiction incorrecte se produit, elle donne un poids élevé à cette observation. Le Boosting Adaptatif répète cette procédure dans la prochaine phase d'itération et continue jusqu'à ce que la précision soit atteinte. Combine ensuite cela pour créer une forte prédiction.
Algorithme de renforcement de gradient
L'algorithme de renforcement de gradient est une technique d'apprentissage automatique pour définir la fonction de perte et la réduire. Il est utilisé pour résoudre des problèmes de classification à l'aide de modèles de prédiction. Cela implique les étapes suivantes:
1. Fonction de perte
L'utilisation de la fonction de perte dépend du type de problème. L'avantage du gradient boosting est qu'il n'y a pas besoin d'un nouvel algorithme de boosting pour chaque fonction de perte.
2. Apprenant faible
Dans le renforcement du gradient, les arbres de décision sont utilisés comme un apprenant faible. Un arbre de régression est utilisé pour donner de vraies valeurs qui peuvent être combinées ensemble pour créer des prédictions correctes. Comme dans l'algorithme AdaBoost, de petits arbres avec une seule division sont utilisés, c'est-à-dire un moignon de décision. Des arbres plus grands sont utilisés pour les grands niveaux i, e 4-8 niveaux.
3. Modèle additif
Dans ce modèle, les arbres sont ajoutés un à la fois. les arbres existants restent les mêmes. Lors de l'ajout d'arbres, la descente en pente est utilisée pour minimiser la fonction de perte.
XG Boost
XG Boost est l'abréviation de Extreme Gradient Boosting. XG Boost est une implémentation améliorée de l'algorithme de renforcement de gradient qui est développé pour une vitesse de calcul élevée, une évolutivité et de meilleures performances.
XG Boost a diverses fonctionnalités qui sont les suivantes:
- Traitement parallèle: XG Boost fournit un traitement parallèle pour la construction d'arbres qui utilise des cœurs de processeur pendant la formation.
- Validation croisée: XG Boost permet aux utilisateurs d'exécuter la validation croisée du processus de boosting à chaque itération, ce qui permet d'obtenir facilement le nombre optimal exact d'itérations de boosting en une seule fois.
- Optimisation du cache: il fournit une optimisation du cache des algorithmes pour une vitesse d'exécution plus élevée.
- Calcul distribué : pour la formation de grands modèles, XG Boost permet le calcul distribué.
Articles recommandés
Dans cet article, nous avons vu ce qu'est l'algorithme de stimulation, divers types d'algorithmes de stimulation dans l'apprentissage automatique et leur fonctionnement. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Qu'est-ce que l'apprentissage automatique? | Une définition
- Langages de programmation pour l'apprentissage des algorithmes
- Qu'est-ce que la technologie Blockchain?
- Qu'est-ce qu'un algorithme?