

Introduction à l'arbre de décision dans l'exploration de données
Dans le monde d'aujourd'hui sur le «Big Data», le terme «Data Mining» signifie que nous devons examiner de grands ensembles de données et effectuer un «mining» sur les données et faire ressortir le jus ou l'essence important de ce que les données veulent dire. Une situation très analogue est celle de l'extraction du charbon où différents outils sont nécessaires pour extraire le charbon enfoui profondément sous le sol. Parmi les outils de l'exploration de données, «l'Arbre de décision» est l'un d'entre eux. Ainsi, l'exploration de données en soi est un vaste domaine dans lequel les prochains paragraphes nous plongeront en profondeur dans «l'outil» d'arbre de décision dans l'exploration de données.
Algorithme d'arbre de décision dans l'exploration de données
Un arbre de décision est une approche d'apprentissage supervisé dans laquelle nous formons les données présentes en sachant déjà quelle est réellement la variable cible. Comme son nom l'indique, cet algorithme a une structure arborescente. Examinons d'abord l'aspect théorique de l'arbre de décision, puis examinons-le dans une approche graphique. Dans l'Arbre de décision, l'algorithme divise l'ensemble de données en sous-ensembles sur la base de l'attribut le plus important ou le plus significatif. L'attribut le plus significatif est désigné dans le nœud racine et c'est là que le fractionnement a lieu de l'ensemble de données présent dans le nœud racine. Ce fractionnement est appelé nœuds de décision. Dans le cas où il n'y a plus de division possible, ce nœud est appelé nœud nœud.
Afin d'arrêter l'algorithme pour atteindre un stade écrasant, un critère d'arrêt est utilisé. L'un des critères d'arrêt est le nombre minimum d'observations dans le nœud avant que la division ne se produise. Lors de l'application de l'arbre de décision lors du fractionnement de l'ensemble de données, il faut faire attention à ce que de nombreux nœuds puissent simplement avoir des données bruyantes. Afin de répondre à des problèmes de données aberrants ou bruyants, nous utilisons des techniques connues sous le nom d'élagage de données. L'élagage des données n'est rien d'autre qu'un algorithme pour classer les données du sous-ensemble, ce qui rend difficile l'apprentissage à partir d'un modèle donné.
L'algorithme Arbre de décision a été publié sous la forme ID3 (dichotomiseur itératif) par le chercheur en machine J. Ross Quinlan. Plus tard, C4.5 est sorti en tant que successeur d'ID3. ID3 et C4.5 sont une approche gourmande. Examinons maintenant un organigramme de l'algorithme Arbre de décision.
Pour notre compréhension du pseudocode, nous prendrions "n" points de données ayant chacun des attributs "k". L'organigramme ci-dessous est fait en gardant à l'esprit le «gain d'informations» comme condition pour une scission.
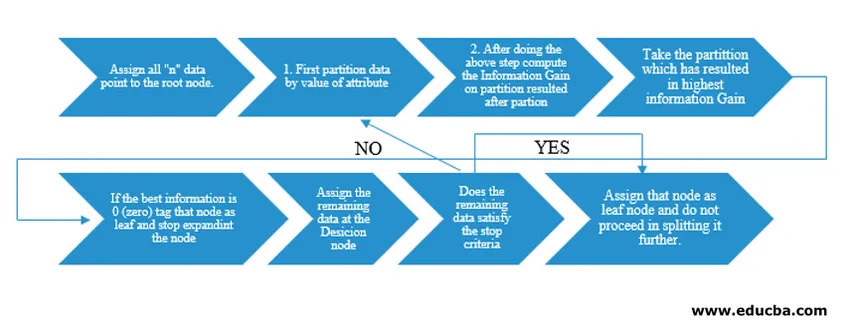
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Au lieu du Gain d'Information (IG), nous pouvons également utiliser l'Indice Gini comme critère de scission. Pour comprendre la différence entre ces deux critères en termes profanes, nous pouvons considérer ce gain d'informations comme la différence d'entropie avant le fractionnement et après le fractionnement (fractionné sur la base de toutes les fonctionnalités disponibles).
L'entropie est comme le hasard et nous atteindrions un point après la scission pour avoir le moins d'état aléatoire. Par conséquent, le gain d'informations doit être optimal sur la fonctionnalité que nous voulons diviser. Sinon, si nous voulons choisir de diviser sur la base de l'indice Gini, nous trouverions l'indice Gini pour différents attributs et en utilisant le même, nous trouverons l'indice Gini pondéré pour une répartition différente et utiliser celui avec un indice Gini plus élevé pour diviser l'ensemble de données.
Arbre de décision important dans l'exploration de données
Voici quelques-uns des termes importants d'un arbre de décision dans l'exploration de données donnés ci-dessous:
- Nœud racine: il s'agit du premier nœud où le fractionnement a lieu.
- Nœud feuille: c'est le nœud après lequel il n'y a plus de ramification.
- Nœud de décision: le nœud formé après la division des données d'un nœud précédent est appelé nœud de décision.
- Branche: sous - section d'un arbre contenant des informations sur les conséquences de la scission au niveau du nœud de décision.
- Élagage: lorsqu'il y a suppression de sous-nœuds d'un nœud de décision pour répondre à une donnée aberrante ou bruyante, c'est l'élagage. On pense également que c'est le contraire du fractionnement.
Application de l'arbre de décision dans l'exploration de données
Arbre de décision a une architecture de type organigramme intégré avec le type d'algorithme. Il a essentiellement un type de type «Si X puis Y sinon Z» pendant la séparation. Ce type de modèle est utilisé pour comprendre l'intuition humaine dans le domaine programmatique. Par conséquent, on peut largement utiliser cela dans divers problèmes de catégorisation.
- Cet algorithme peut être largement utilisé dans le domaine où la fonction objectif est liée par rapport à l'analyse effectuée.
- Lorsqu'il existe de nombreux plans d'action disponibles.
- Analyse aberrante.
- Comprendre l'ensemble significatif de fonctionnalités pour l'ensemble de données et «extraire» les quelques fonctionnalités d'une liste de centaines de fonctionnalités dans les mégadonnées.
- Sélection du meilleur vol pour voyager vers une destination.
- Processus décisionnel basé sur différentes situations circonstancielles.
- Analyse de désabonnement.
- Analyse des sentiments.
Avantages de l'arbre de décision
Voici quelques avantages de l'arbre de décision expliqué ci-dessous:
- Facilité de compréhension: La façon dont l'arbre de décision est représenté sous ses formes graphiques le rend facile à comprendre pour une personne ayant des antécédents non analytiques. Surtout pour les dirigeants qui veulent voir quelles caractéristiques sont importantes juste un coup d'œil à l'arbre de décision peut faire ressortir leur hypothèse.
- Exploration des données: Comme discuté, l'obtention de variables significatives est une fonctionnalité de base de l'arbre de décision et en l'utilisant, on peut comprendre pendant l'exploration des données pour décider quelle variable nécessiterait une attention particulière au cours de la phase d'exploration de données et de modélisation.
- Il y a très peu d'intervention humaine pendant la phase de préparation des données et en raison de ce temps consommé pendant les données, le nettoyage est réduit.
- L'Arbre de décision est capable de gérer des variables tant catégoriques que numériques et de répondre également à des problèmes de classification multi-classes.
- Dans le cadre de l'hypothèse, les arbres de décision n'ont aucune hypothèse à partir d'une structure spatiale et de classification.
Conclusion
Enfin, pour conclure, les arbres de décision apportent une toute autre classe de non-linéarité et permettent de résoudre des problèmes de non-linéarité. Cet algorithme est le meilleur choix pour imiter une pensée au niveau décisionnel des humains et la représenter sous une forme mathématique-graphique. Il adopte une approche descendante pour déterminer les résultats de nouvelles données invisibles et suit le principe de diviser pour mieux régner.
Articles recommandés
Ceci est un guide de l'arbre de décision dans l'exploration de données. Nous discutons ici de l'algorithme, de l'importance et de l'application de l'arbre de décision dans l'exploration de données ainsi que de ses avantages. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Apprentissage automatique de la science des données
- Types de techniques d'analyse de données
- Arbre de décision en R
- Qu'est-ce que l'exploration de données?
- Guide des différentes méthodologies d'analyse des données