

Introduction à l' algorithme d'arbre de décision
Lorsque nous avons un problème à résoudre qui est soit un problème de classification soit un problème de régression, l'algorithme d'arbre de décision est l'un des algorithmes les plus populaires utilisés pour construire les modèles de classification et de régression. Ils entrent dans la catégorie de l'apprentissage supervisé, c'est-à-dire les données étiquetées.
Qu'est-ce que l'algorithme d'arbre de décision?
L'algorithme d'arbre de décision est un algorithme d'apprentissage automatique supervisé où les données sont divisées en continu à chaque ligne en fonction de certaines règles jusqu'à ce que le résultat final soit généré. Prenons un exemple, supposons que vous ouvriez un centre commercial et bien sûr, vous voudriez qu'il grandisse en affaires avec le temps. Donc, pour cette question, vous auriez besoin de clients de retour ainsi que de nouveaux clients dans votre centre commercial. Pour cela, vous devez préparer différentes stratégies commerciales et marketing telles que l'envoi d'e-mails à des clients potentiels; créer des offres et des offres, cibler de nouveaux clients, etc. Mais comment savoir qui sont les clients potentiels? En d'autres termes, comment classer la catégorie des clients? Comme certains clients visiteront une fois par semaine et d'autres voudraient visiter une ou deux fois par mois, ou certains visiteront dans un quart. Les arbres de décision sont donc l'un de ces algorithmes de classification qui classeront les résultats en groupes jusqu'à ce qu'il ne reste plus de similitude.
De cette façon, l'arbre de décision descend dans un format arborescent. Les principaux éléments d'un arbre de décision sont les suivants:
- Nœuds de décision, qui est l'endroit où les données sont divisées ou, disons, c'est un endroit pour l'attribut.
- Lien de décision, qui représente une règle.
- Les feuilles de décision, qui sont les résultats finaux.

Fonctionnement d'un algorithme d'arbre de décision
De nombreuses étapes sont impliquées dans le fonctionnement d'un arbre de décision:
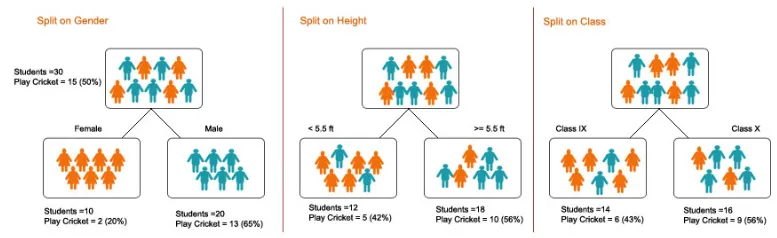
1. Fractionnement - C'est le processus de partitionnement des données en sous-ensembles. Le fractionnement peut être effectué sur divers facteurs comme indiqué ci-dessous, c'est-à-dire en fonction du sexe, de la taille ou de la classe.
2. Élagage - C'est le processus de raccourcissement des branches de l'arbre de décision, limitant ainsi la profondeur de l'arbre
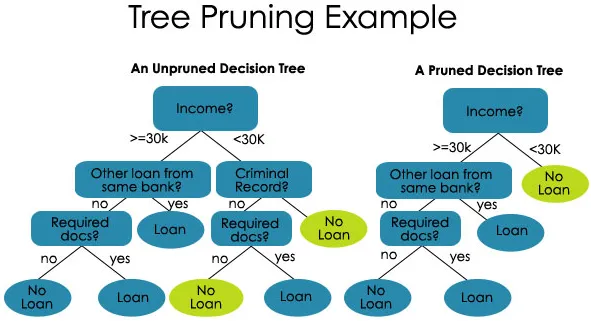
L'élagage est également de deux types:
- Pré-élagage - Ici, nous arrêtons de faire croître l'arbre lorsque nous ne trouvons aucune association statistiquement significative entre les attributs et la classe à un nœud particulier.
- Post-élagage - Afin de post-élagage, nous devons valider les performances du modèle de l'ensemble de test, puis couper les branches qui sont le résultat d'un sur-ajustement du bruit de l'ensemble d'apprentissage.
3. Sélection d'arbre - La troisième étape est le processus de recherche du plus petit arbre qui correspond aux données.
Exemples et illustration de la construction d'un arbre de décision
Maintenant, comme nous avons appris les principes d'un arbre de décision. Comprenons et illustrons cela à l'aide d'un exemple.
Disons que vous voulez jouer au cricket un jour particulier (par exemple, samedi). Quels sont les facteurs impliqués qui décideront si le jeu va se produire ou non?
De toute évidence, le facteur principal est le climat, aucun autre facteur n'a autant de probabilité que le climat d'avoir l'interruption du jeu.
Nous avons collecté les données des 10 derniers jours qui sont présentées ci-dessous:
| journée | Météo | Température | Humidité | Vent | Jouer? |
| 1 | Nuageux | Chaud | Haute | Faible | Oui |
| 2 | Ensoleillé | Chaud | Haute | Faible | Non |
| 3 | Ensoleillé | Doux | Ordinaire | Fort | Oui |
| 4 | Pluvieux | Doux | Haute | Fort | Non |
| 5 | Nuageux | Doux | Haute | Fort | Oui |
| 6 | Pluvieux | Cool | Ordinaire | Fort | Non |
| sept | Pluvieux | Doux | Haute | Faible | Oui |
| 8 | Ensoleillé | Chaud | Haute | Fort | Non |
| 9 | Nuageux | Chaud | Ordinaire | Faible | Oui |
| dix | Pluvieux | Doux | Haute | Fort | Non |
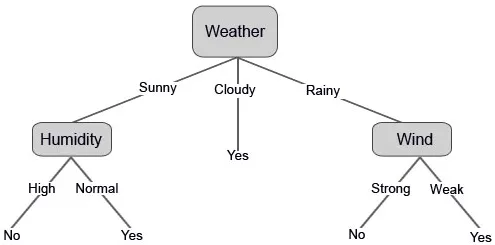
Construisons maintenant notre arbre de décision sur la base des données que nous avons obtenues. Nous avons donc divisé l'arbre de décision en deux niveaux, le premier est basé sur l'attribut «Météo» et la deuxième ligne est basée sur «Humidité» et «Vent». Les images ci-dessous illustrent un arbre de décision appris.
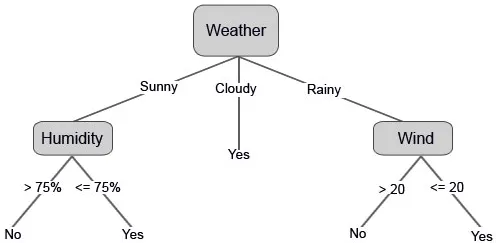
Nous pouvons également définir certaines valeurs de seuil si les fonctionnalités sont continues.
Qu'est-ce que l'entropie dans l'algorithme d'arbre de décision?
En termes simples, l'entropie est la mesure du désordre de vos données. Bien que vous ayez peut-être entendu ce terme dans vos cours de mathématiques ou de physique, c'est la même chose ici.
La raison pour laquelle Entropy est utilisé dans l'arbre de décision est que le but ultime de l'arbre de décision est de regrouper des groupes de données similaires en classes similaires, c'est-à-dire de ranger les données.
Voyons l'image ci-dessous, où nous avons l'ensemble de données initial et nous sommes tenus d'appliquer un algorithme d'arbre de décision afin de regrouper les points de données similaires dans une catégorie.
Après la scission de la décision, comme nous pouvons clairement le voir, la plupart des cercles rouges relèvent d'une classe tandis que la plupart des croix bleues relèvent d'une autre classe. Par conséquent, la décision a été de classer les attributs qui pourraient être basés sur divers facteurs.
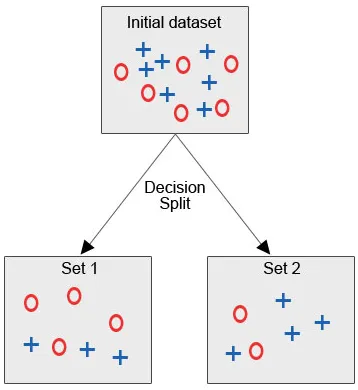
Maintenant, essayons de faire quelques calculs ici:
Disons que nous avons des ensembles «N» de l'élément et ces éléments se répartissent en deux catégories, et maintenant afin de regrouper les données en fonction des étiquettes, nous introduisons le rapport:
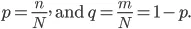
L'entropie de notre ensemble est donnée par l'équation suivante:
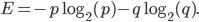
Voyons le graphique de l'équation donnée:
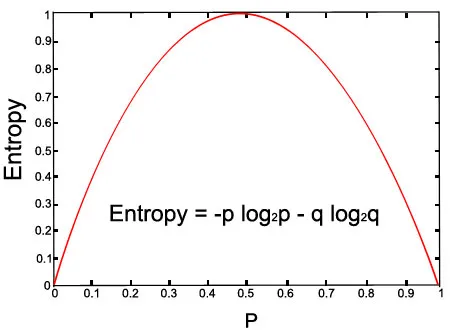
Image ci-dessus (avec p = 0, 5 et q = 0, 5)
Les avantages
1. Un arbre de décision est simple à comprendre et une fois qu'il est compris, nous pouvons le construire.
2. Nous pouvons implémenter un arbre de décision sur des données numériques et catégorielles.
3. L'arbre de décision s'est avéré être un modèle robuste avec des résultats prometteurs.
4. Ils sont également rapides avec des données volumineuses.
5. Il nécessite moins d'efforts pour la formation des données.
Désavantages
1. Instabilité - Seulement si les informations sont précises et exactes, l'arbre de décision fournira des résultats prometteurs. Même s'il y a un léger changement dans les données d'entrée, cela peut provoquer de grands changements dans l'arborescence.
2. Complexité - Si l'ensemble de données est énorme avec de nombreuses colonnes et lignes, il est très complexe de concevoir un arbre de décision avec de nombreuses branches.
3. Coûts - Parfois, les coûts restent également un facteur principal car lorsque l'on est obligé de construire un arbre de décision complexe, il nécessite des connaissances avancées en analyse quantitative et statistique.
Conclusion
Dans cet article, nous avons appris l'algorithme de l'arbre de décision et comment en construire un. Nous avons également vu le grand rôle joué par Entropy dans l'algorithme de l'arbre de décision et enfin, nous avons vu les avantages et les inconvénients de l'arbre de décision.
Articles recommandés
Cela a été un guide pour l'algorithme d'arbre de décision. Ici, nous avons discuté du rôle joué par l'entropie, le travail, les avantages et les inconvénients. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Méthodes importantes d'exploration de données
- Qu'est-ce que l'application Web?
- Guide sur Qu'est-ce que la science des données?
- Questions d'entretiens pour le poste de Data Analyst
- Application de l'arbre de décision dans l'exploration de données