

Introduction à Python Pandas DataFrame
Plusieurs extensions pour la bibliothèque Python, Pandas, peuvent être trouvées en ligne. L'une de ces données est Panel (pan) Data (das). Ce mot, * Panel *, fait subtilement allusion à une structure de données bidimensionnelle présente dans cette bibliothèque, responsabilisant énormément ses utilisateurs. Cette structure même est appelée DataFrame.
Il s'agit essentiellement d'une matrice de lignes et de colonnes, contenant l'intégralité de votre jeu de données, avec des options très élaborées pour l'indexation. Le DataFrame (DF), peut être imaginé de manière très similaire à une feuille Excel. Mais ce qui le rend puissant, c'est la facilité avec laquelle les opérations d'analyse et de transformation peuvent être effectuées sur les données stockées dans un DataFrame.
Qu'est-ce qu'un DataFrame Pandas Python?
La page Pydata peut être référée pour quelque chose d'une définition officielle.
Si elle est bien comprise, elle mentionne DataFrame comme une structure en colonnes, capable de stocker tout objet python (y compris un DataFrame lui-même) comme une valeur de cellule. (Une cellule est indexée à l'aide d'une combinaison unique de lignes et de colonnes)
DataFrames se compose de trois composants essentiels: données, lignes et colonnes.
- Données: il s'agit des objets / entités réels stockés dans une cellule du DataFrame et des valeurs représentées par ces entités. Un objet est de n'importe quel type de données python valide, qu'il soit intégré ou défini par l'utilisateur.
- Lignes: les références utilisées pour identifier (ou indexer) un ensemble particulier d'observations à partir des données complètes stockées dans un DataFrame sont appelées lignes. Pour être clair, il représente les indices utilisés et pas seulement les données d'une observation particulière.
- Colonnes: références utilisées pour identifier (ou indexer) un ensemble d'attributs pour toutes les observations dans un DataFrame. Comme dans le cas des lignes, celles-ci se réfèrent à l'index de colonne (ou aux en-têtes de colonne) au lieu des seules données de la colonne.
Alors sans plus tarder, essayons quelques façons de créer ces structures incroyablement puissantes.
Étapes pour créer des cadres de données Python Pandas
Un DataFrame Python Pandas peut être créé à l'aide de l'implémentation de code suivante,
1. Importer des pandas
Pour créer des DataFrames, la bibliothèque pandas doit être importée (pas de surprise ici). Nous allons l'importer avec un alias pd pour référencer facilement les objets sous le module.
Code:
import pandas as pd
2. Création du premier objet DataFrame
Une fois la bibliothèque importée, toutes les méthodes, fonctions et constructeurs sont disponibles dans votre espace de travail. Essayons donc de créer un DataFrame vanille.
Code:
import pandas as pd
df = pd.DataFrame()
print(df)
Production:
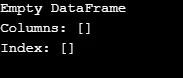
Comme indiqué dans la sortie, le constructeur renvoie un DataFrame vide.
Concentrons-nous maintenant sur la création de DataFrames à partir de données stockées dans certaines des représentations probables.
- DataFrame à partir d'un dictionnaire: Supposons que nous ayons un dictionnaire stockant une liste d'entreprises dans Software Domain et le nombre d'années depuis lesquelles elles sont actives.
Code:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Voyons la représentation de l'objet DataFrame retourné en l'imprimant sur la console.
Production:

Comme on peut le voir, chaque clé du dictionnaire est traitée comme une colonne dans le DataFrame, et les index des lignes sont générés automatiquement à partir de 0. Assez facile hein!
Supposons maintenant que vous vouliez lui donner un index personnalisé au lieu de 0, 1, .. 4. Vous avez juste besoin de passer la liste souhaitée en tant que paramètre au constructeur et les pandas feront le nécessaire.
Code:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Production:
Âge de l'entreprise
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Vous pouvez maintenant définir les indices de ligne sur n'importe quelle valeur souhaitée.
- DataFrame à partir d'un fichier CSV: Créons un fichier CSV contenant les mêmes données que dans le cas de notre dictionnaire. Appelons le fichier CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Le fichier peut être chargé dans une trame de données (en supposant qu'il soit présent dans le répertoire de travail actuel) comme suit.
Code:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Production:
Âge de l'entreprise
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
La définition des noms de paramètres , en contournant une liste de valeurs, les affecte en tant qu'en-têtes de colonne dans le même ordre qu'ils sont présents dans la liste. De même, les indices de ligne peuvent être définis en passant une liste au paramètre d'index, comme indiqué dans la section précédente. L'en-tête = Aucun indique les en-têtes de colonne manquants dans le fichier de données.
Supposons maintenant que les noms des colonnes fassent partie du fichier de données. Ensuite, définir header = False fera le travail requis.
3. CompanyAgeWithHeader.csv
Entreprise, Âge
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Le code deviendra
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Production:
Âge de l'entreprise
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame à partir d'un fichier Excel: Souvent, les données sont partagées dans des fichiers Excel car il reste l'outil le plus populaire utilisé par les gens du commun pour le suivi ad hoc . Ainsi, cela ne devrait pas être ignoré par notre discussion.
Supposons que les données, comme dans CompanyAgeWithHeader.csv, soient désormais stockées dans CompanyAgeWithHeader.xlsx, dans une feuille avec le nom Company Age. Le même DataFrame que ci-dessus sera créé par le code suivant.
Code:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Production:
Âge de l'entreprise
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Comme vous pouvez le voir, le même DataFrame peut être créé en passant le nom de fichier et le nom de feuille.
Lectures complémentaires et prochaines étapes
Les méthodes présentées constituent un très petit sous-ensemble par rapport à toutes les différentes façons dont les DataFrames peuvent être créés. Celles-ci ont été créées avec l'intention d'en démarrer une. Vous devez certainement explorer les références répertoriées et essayer d'explorer d'autres façons, notamment en vous connectant à une base de données pour lire des données directement dans un DataFrame.
Conclusion
Pandas DataFrame s'est avéré être un changeur de jeu dans le monde de la science des données et de l'analyse de données, et est également pratique pour les projets ponctuels à court terme. Il est livré avec une armée d'outils capables de découper et découper l'ensemble de données avec une extrême facilité. J'espère que cela servira de tremplin dans votre voyage à venir.
Articles recommandés
Ceci est un guide de Python-Pandas DataFrame. Nous discutons ici des étapes de création d'une trame de données python-pandas ainsi que de son implémentation de code. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Les 15 principales fonctionnalités de Python
- Différents types d'ensembles Python
- 4 principaux types de variables en Python
- Top 6 des éditeurs de Python
- Tableaux dans la structure de données