
Introduction à Hive Group By
Grouper par comme son nom l'indique, il regroupera l'enregistrement qui répond à certains critères. Dans cet article, nous allons regarder le groupe par HIVE. Dans les SGBDR hérités comme MySQL, SQL, etc., group by est l'une des clauses les plus anciennes utilisées. Maintenant, il a trouvé sa place de manière similaire dans le stockage de données basé sur des fichiers connu sous le nom de HIVE.
Nous savons que la ruche a dépassé de nombreux SGBDR hérités dans la gestion d'énormes données sans qu'un sou soit dépensé pour les fournisseurs de maintenance des bases de données et des serveurs. Nous avons juste besoin de configurer HDFS pour gérer la ruche. Généralement, nous passons aux tables car l'utilisateur final peut interpréter à partir de sa structure et peut interroger car les fichiers seront maladroits pour eux. Mais nous avons dû le faire en payant les fournisseurs pour fournir des serveurs et maintenir nos données sous forme de tableaux. Ainsi, Hive fournit le mécanisme rentable où il tire parti des systèmes basés sur des fichiers (la façon dont la ruche enregistre ses données) ainsi que des tables (structure de table sur laquelle les utilisateurs finaux peuvent interroger).
Par groupe
Grouper par utilise les colonnes définies de la table Hive pour regrouper les données. Par exemple, considérez que vous avez un tableau avec les données du recensement de chaque ville de tous les États où le nom de la ville et le nom de l'État sont l'une des colonnes. Maintenant, dans la requête, si nous groupons par états, toutes les données de différentes villes d'un état particulier seront regroupées et on peut facilement visualiser les données mieux avant la façon dont group by a été appliqué.
Syntaxe de Hive Group By
La syntaxe générale de la clause group by est la suivante:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
ou pour des requêtes plus simples,
from Group By
Select department, count(*) from the university.college Group By department;
Ici, le département se réfère à l'une des colonnes de la table du collège qui est présente dans la base de données universitaire et sa valeur est différente dans des départements comme les arts, les mathématiques, l'ingénierie, etc.
J'ai créé un exemple de table deck_of_cards pour illustrer le groupe par. Son instruction create table est la suivante:
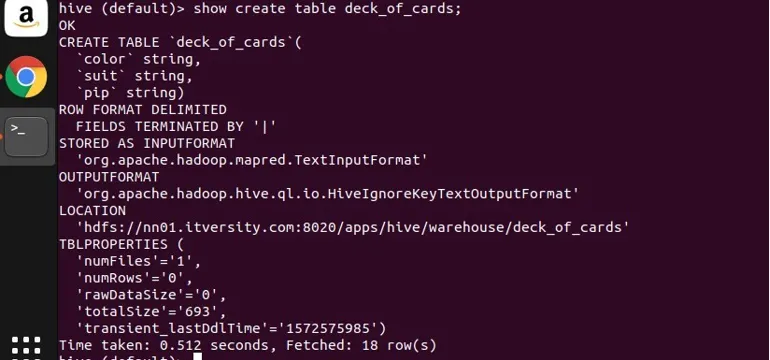
vous pouvez voir ci-dessus qu'il a trois colonnes de chaîne de couleur, costume et pip. Permettez-moi d'écrire une requête pour regrouper les données par leur couleur et obtenir leur nombre.
select color, count(*) from deck_of_cards group by color;
Hive prend essentiellement la requête ci-dessus pour la convertir en programme de réduction de carte en générant le code java et le fichier jar correspondants, puis s'exécute. Ce processus peut prendre un peu de temps, mais il peut certainement gérer les mégadonnées par rapport au SGBDR traditionnel. Voir la capture d'écran ci-dessous avec le journal détaillé pour exécuter la requête ci-dessus.
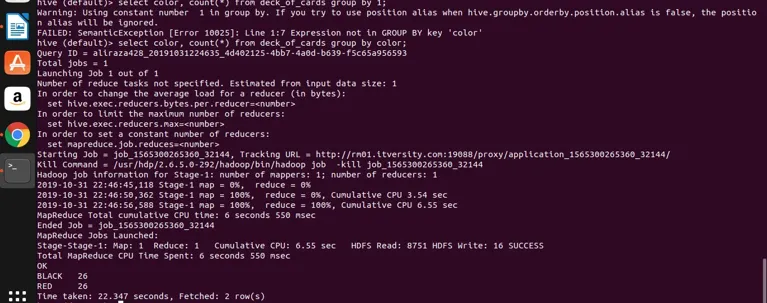
vous pouvez voir que NOIR est 26 et ROUGE est 26.
appliquons maintenant le regroupement sur deux colonnes (couleur et couleur et obtention du nombre de groupes) et voyons le résultat ci-dessous.
Select color, suit, count(*) from deck_of_cards group by color, suit
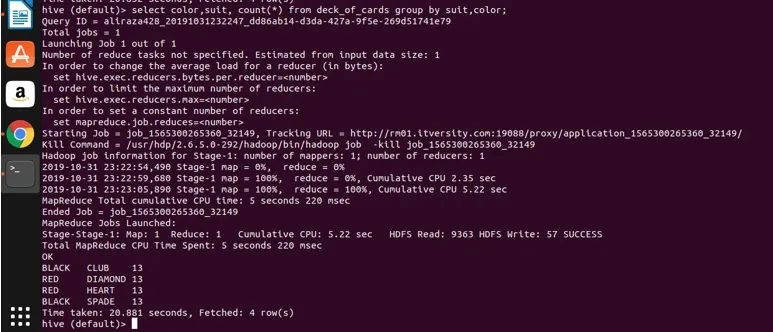
Fondamentalement, il existe quatre groupes distincts au-dessus du Club, Spade qui ont la couleur noire et Diamond et le cœur qui sont de couleur rouge.
Stockage du résultat du groupe par cause dans une autre table
Hive, comme tout autre SGBDR, offre la possibilité d'insérer les données avec des instructions create table. Voyons comment stocker le résultat d'une expression de sélection à l'aide d'un groupe par dans une autre table. Permettez-moi d'utiliser la requête ci-dessus où j'ai utilisé deux colonnes dans le groupe par.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
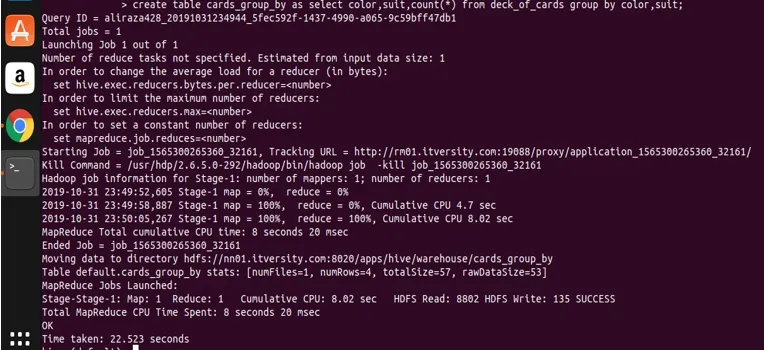
interrogons maintenant la table créée pour voir et valider les données.

Limitons maintenant le résultat du groupe en utilisant la clause having. Comme indiqué dans la syntaxe générique, nous pouvons appliquer une restriction sur le groupe, en utilisant having. Ici, j'utilise la table ordser_items et sa structure est la suivante à partir de la description.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
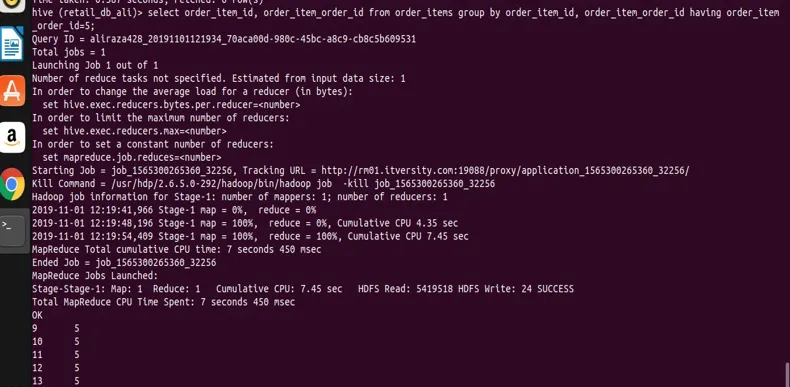
vous pouvez voir à partir du résultat la capture d'écran que nous avons des enregistrements uniquement avec la valeur order_item_order_id 5.
Grouper par accompagné de l'énoncé de cas
Examinons maintenant les requêtes peu complexes impliquant les instructions CASE avec le groupe by. Nous l'appliquerons à la table order_items. Nous verrons ci-dessous que nous pouvons catégoriser les colonnes non agrégées sur lesquelles nous ne pouvons pas appliquer directement la clause group by.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
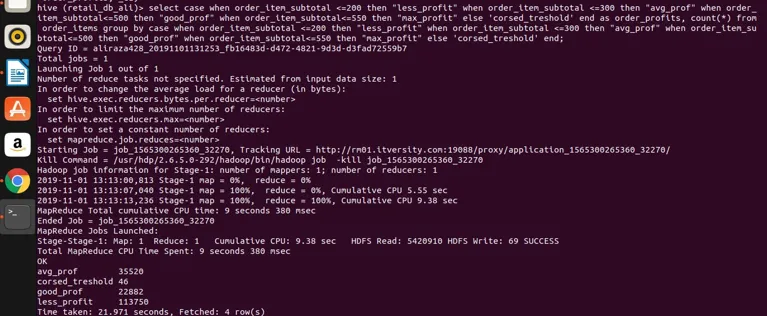
exécutons-le dans la ruche pour les résultats
Conclusion - Hive Group By
afin que nous puissions voir que nous avons regroupé order_item_subtotal en quatre catégories différentes (si vous notez que order_item_subtotal est une colonne non agrégative et que grouper directement par ne peut pas être appliqué dessus) et nous les avons regroupés et avons également obtenu leur nombre pour les valeurs qui satisfont la plage définie dans l'expression de sélection. Voici la règle simple si la colonne n'est pas agrégée et que notre expression de sélection est complexe, alors quoi que ce soit dans l'expression de sélection qui devrait également être présent dans l'expression de clause group by. Nous avons donc vu comment un fameux groupe de clauses RDBMS clause peut également être appliqué sur la ruche sans aucune restriction. Il peut être appliqué à des expressions de sélection simples. Agréger et filtrer les expressions, les expressions de jointure et les expressions CASE complexes également.
Articles recommandés
Ceci est un guide de Hive Group By. Nous discutons ici du groupe par, de la syntaxe, des exemples du groupe ruche par avec différentes conditions et implémentations. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Se joint à Hive
- Qu'est-ce qu'une ruche?
- Architecture de la ruche
- Fonction ruche
- Ordre de ruche par
- Installation de ruche
- 6 principaux types de jointures dans MySQL avec des exemples