

Présentation des types de clustering
Avant d'apprendre les types de clustering, comprenons ce qu'est le clustering et pourquoi est-il si important dans l'industrie du machine learning en ce moment.
Qu'est-ce que le clustering? Le clustering est un processus dans lequel l'algorithme divise les points de données en un nombre défini de groupes sur la base du principe que des points de données similaires restent proches les uns des autres et tombent dans le même groupe.
Pourquoi est-ce si important maintenant? Comprenons qu'en voyant un exemple, par exemple, il y a une boutique de vêtements en ligne et ils veulent mieux comprendre leurs clients afin de rendre leur stratégie publicitaire plus efficace. Il ne leur est pas possible d'avoir un type de stratégie unique pour chaque client, au lieu de cela, ils peuvent diviser les clients en un certain nombre de groupes (en fonction de leurs achats précédents) et avoir une stratégie distincte de groupes distincts. Cela rend l'entreprise plus efficace, c'est la raison pour laquelle le clustering est important dans l'industrie maintenant.
Types de clustering
Les méthodes de regroupement sont classées en deux types: les méthodes dures et les méthodes douces. Dans la méthode de clustering dur, chaque point de données ou observation appartient à un seul cluster. Dans la méthode de clustering souple, chaque point de données n'appartiendra pas complètement à un cluster, mais peut être membre de plusieurs clusters, il a un ensemble de coefficients d'appartenance correspondant à la probabilité d'être dans un cluster donné.
Actuellement, il existe différents types de méthodes de clustering utilisées, ici dans cet article, voyons quelques-unes des plus importantes comme le clustering hiérarchique, le clustering de partitionnement, le clustering flou, le clustering basé sur la densité et le clustering basé sur le modèle de distribution. Voyons maintenant chacun d'eux avec un exemple:
1. Partitionnement du clustering
Le partitionnement Le clustering est un type de technique de clustering qui divise l'ensemble de données en un nombre défini de groupes. (Par exemple, la valeur de K en KNN et il sera décidé avant de former le modèle). Elle peut également être appelée méthode basée sur les centroïdes. Dans cette approche, le centre de cluster (centroïde) est formé de telle sorte que la distance des points de données dans ce cluster soit minimale lorsqu'elle est calculée avec d'autres centroïdes de cluster. Un exemple le plus populaire de cet algorithme est l'algorithme KNN. Voici à quoi ressemble un algorithme de clustering de partitionnement
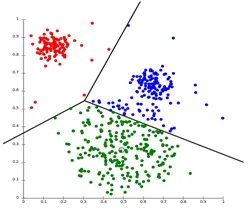
2. Regroupement hiérarchique
Le clustering hiérarchique est un type de technique de clustering qui divise cet ensemble de données en un certain nombre de clusters, où l'utilisateur ne spécifie pas le nombre de clusters à générer avant de former le modèle. Ce type de technique de clustering est également connu sous le nom de méthodes basées sur la connectivité. Dans cette méthode, le partitionnement simple de l'ensemble de données ne sera pas effectué, alors qu'il nous fournit la hiérarchie des clusters qui fusionnent les uns avec les autres après une certaine distance. Une fois le regroupement hiérarchique effectué sur l'ensemble de données, le résultat sera une représentation arborescente des points de données (dendogramme), qui sont divisés en grappes. Voici à quoi ressemble un regroupement hiérarchique après la formation
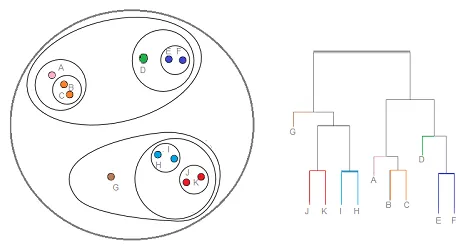
Lien source: Clustering hiérarchique
Dans le clustering de partitionnement et le clustering hiérarchique, une différence principale que nous pouvons remarquer est dans le clustering de partitionnement, nous allons pré-spécifier la valeur du nombre de clusters dans lesquels nous voulons que l'ensemble de données soit divisé et nous ne prédéfinissons pas cette valeur dans le clustering hiérarchique .
3. Clustering basé sur la densité
Dans ce regroupement, des grappes techniques seront formées par ségrégation de diverses régions de densité en fonction de différentes densités dans le tracé de données. Le regroupement spatial basé sur la densité et l'application avec bruit (DBSCAN) est l'algorithme le plus utilisé dans ce type de technique. L'idée principale derrière cet algorithme est qu'il devrait y avoir un nombre minimum de points qui contiennent au voisinage d'un rayon donné pour chaque point du cluster. Jusqu'à présent, dans les techniques de cluster discutées ci-dessus, si vous observez attentivement, nous pouvons remarquer une chose commune dans toutes les techniques qui ont la forme de clusters formés, soit sphériques ou ovales ou concaves. DBSCAN peut former des grappes sous différentes formes, ce type d'algorithme est le plus approprié lorsque l'ensemble de données contient du bruit ou des valeurs aberrantes. Voici à quoi ressemble un algorithme de clustering spatial basé sur la densité après la formation.
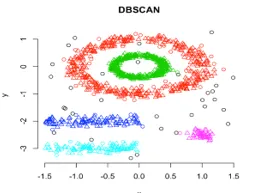
Lien source: Clustering basé sur la densité
4. Clustering basé sur un modèle de distribution
Dans ce type de clustering, les clusters techniques sont formés en identifiant par la probabilité que tous les points de données du cluster proviennent de la même distribution (Normal, Gaussien). L'algorithme le plus populaire dans ce type de technique est le clustering Expectation-Maximization (EM) utilisant des modèles de mélange gaussiens (GMM).
Les techniques de clustering normales comme le clustering hiérarchique et le clustering de partitionnement ne sont pas basées sur des modèles formels, KNN dans le clustering de partitionnement donne des résultats différents avec des valeurs K différentes. Comme KNN et KMN considèrent la moyenne pour le centre du cluster, elle ne convient pas dans certains cas avec les modèles de mélange gaussiens, nous supposons que les points de données sont distribués gaussiens, de cette façon, nous avons deux paramètres pour décrire la forme de la moyenne des clusters et l'écart-type. De cette façon, pour chaque cluster, une distribution gaussienne est affectée, pour obtenir les valeurs optimales de ces paramètres (moyenne et écart-type), un algorithme d'optimisation appelé maximisation des attentes est utilisé. Voici à quoi ressemble EM-GMM après l'entraînement.
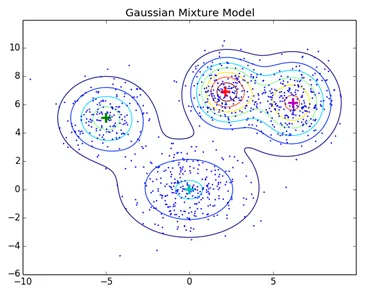
Lien source: clustering basé sur un modèle de distribution
5. Clustering flou
Appartient à une branche des techniques de clustering de méthode douce, alors que toutes les techniques de clustering mentionnées ci-dessus appartiennent aux techniques de clustering de méthode dure. Dans ce type de technique de clustering, les points sont proches du centre, peut-être une partie de l'autre cluster à un degré plus élevé que les points situés au bord du même cluster. La probabilité qu'un point appartenant à un cluster donné soit une valeur comprise entre 0 et 1. L'algorithme le plus populaire dans ce type de technique est FCM (Fuzzy C-means Algorithm) Ici, le centroïde d'un cluster est calculé comme la moyenne de tous les points, pondérés par leur probabilité d'appartenance au cluster.
Conclusion - Types de regroupement
Ce sont quelques-unes des différentes techniques de clustering qui sont actuellement utilisées et dans cet article, nous avons couvert un algorithme populaire dans chaque technique de clustering. Nous devons choisir le type de technologie que nous utilisons, en fonction de notre ensemble de données et des exigences que nous devons satisfaire.
Articles recommandés
Cela a été un guide pour les types de clustering. Nous discutons ici de différents types de clustering avec leurs exemples. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Algorithme de clustering hiérarchique
- Clustering dans l'apprentissage automatique
- Types d'algorithmes d'apprentissage automatique
- Types de techniques d'analyse de données
- Comment utiliser et supprimer la hiérarchie dans Tableau?
- Guide complet des types d'analyse de données