
Introduction à l'élimination en arrière
Alors que l'homme et la machine se dirigent vers l'évolution numérique, diverses machines techniques comptent pour se former non seulement mais intelligemment pour sortir avec une meilleure reconnaissance des objets du monde réel. Une telle technique introduite précédemment, appelée «élimination vers l'arrière», visait à favoriser les fonctionnalités indispensables tout en supprimant les fonctionnalités nugatoires pour permettre une meilleure optimisation dans une machine. La maîtrise totale de la reconnaissance d'objets par Machine est proportionnelle aux caractéristiques qu'elle considère.
Les fonctions qui n'ont aucune référence sur la sortie prévue doivent être déchargées de la machine et cela se termine par une élimination en arrière. La bonne précision et la complexité temporelle de la reconnaissance de tout objet verbal réel par Machine dépendent de son apprentissage. L'élimination vers l'arrière joue donc son rôle rigide pour la sélection des fonctionnalités. Il calcule le taux de dépendance des caractéristiques à la variable dépendante trouve la signification de son appartenance au modèle. Pour l'accréditer, il vérifie le taux calculé avec un niveau de signification standard (par exemple 0, 06) et prend une décision pour la sélection des fonctionnalités.
Pourquoi impliquons-nous une élimination en amont ?
Des traits inutiles et redondants propulsent la complexité de la logique machine. Il dévore inutilement le temps et les ressources du modèle. La technique susmentionnée joue donc un rôle compétent pour forger le modèle en toute simplicité. L'algorithme cultive la meilleure version du modèle en optimisant ses performances et en tronquant ses ressources nominatives consommables.
Il réduit les caractéristiques les moins remarquables du modèle, ce qui provoque du bruit dans la décision de la ligne de régression. Des traits d'objet non pertinents peuvent engendrer une classification erronée et une prédiction. Les caractéristiques non pertinentes d'une entité peuvent constituer un déséquilibre dans le modèle par rapport à d'autres caractéristiques importantes d'autres objets. L'élimination vers l'arrière favorise l'adaptation du modèle au meilleur des cas. Par conséquent, l'élimination vers l'arrière est recommandée à utiliser dans un modèle.
Comment appliquer l'élimination en arrière?
L'élimination vers l'arrière commence avec toutes les variables d'entité, en la testant avec la variable dépendante sous un ajustement sélectionné de critère de modèle. Il commence à éradiquer les variables qui détériorent la ligne de régression de l'ajustement. Répéter cette suppression jusqu'à ce que le modèle atteigne un bon ajustement. Voici les étapes pour pratiquer l'élimination en arrière:
Étape 1: Choisissez le niveau de signification approprié pour résider dans le modèle de la machine. (Prenez S = 0, 06)
Étape 2: alimenter toutes les variables indépendantes disponibles dans le modèle par rapport à la variable dépendante et calculer la pente et intercepter pour tracer une ligne de régression ou une ligne d'ajustement.
Étape 3: Traversez avec toutes les variables indépendantes qui possèdent la valeur la plus élevée (Take I) une par une et procédez avec le toast suivant: -
a) Si I> S, exécutez la 4ème étape.
b) Sinon abandonner et le modèle est parfait.
Étape 4: supprimez la variable choisie et incrémentez la traversée.
Étape 5: Forgez à nouveau le modèle et calculez à nouveau la pente et l'ordonnée à l'origine de la ligne d'ajustement avec des variables résiduelles.
Les étapes susmentionnées sont résumées dans le rejet des caractéristiques dont le taux de signification est supérieur à la valeur de signification sélectionnée (0, 06) pour éviter la surclassification et la surutilisation des ressources qui se sont révélées très complexes.
Mérites et inconvénients de l'élimination en arrière
Voici quelques mérites et inconvénients de l'élimination en arrière donnés ci-dessous en détail:
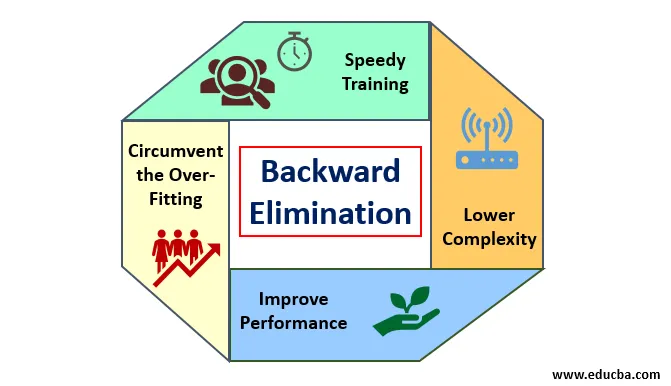
1. Fond
Les mérites de l'élimination en amont sont les suivants:
- Formation rapide: la machine est entraînée avec un ensemble de fonctionnalités disponibles de modèle, ce qui se fait en très peu de temps si les fonctionnalités non essentielles sont supprimées du modèle. Un apprentissage rapide de l'ensemble de données n'est possible que lorsque le modèle traite des caractéristiques importantes et exclut toutes les variables de bruit. Il dessine une complexité simple pour la formation. Mais le modèle ne doit pas subir de sous-ajustement qui se produit en raison du manque de fonctionnalités ou d'échantillons inadéquats. La fonction d'échantillon doit être abondante dans un modèle pour la meilleure classification. Le temps requis pour former le modèle devrait être inférieur tout en maintenant la précision de la classification et laissé sans variable de sous-prédiction.
- Complexité inférieure: la complexité du modèle se trouve être élevée si le modèle envisage l'étendue des fonctionnalités, y compris le bruit et les fonctionnalités non liées. Le modèle consomme beaucoup d'espace et de temps pour traiter un tel éventail de fonctionnalités. Cela peut augmenter le taux de précision de la reconnaissance des formes, mais le taux peut également contenir du bruit. Pour se débarrasser d'une complexité aussi élevée du modèle, l'algorithme d'élimination vers l'arrière joue un rôle nécessaire en retirant les caractéristiques indésirables du modèle. Il simplifie la logique de traitement du modèle. Seules quelques fonctionnalités essentielles sont suffisantes pour dessiner un bon ajustement qui se contente d'une précision raisonnable.
- Améliorer les performances: les performances du modèle dépendent de nombreux aspects. Le modèle subit une optimisation en utilisant l'élimination vers l'arrière. L'optimisation du modèle est l'optimisation de l'ensemble de données utilisé pour l'apprentissage du modèle. Les performances du modèle sont directement proportionnelles à son taux d'optimisation qui repose sur la fréquence des données significatives. Le processus d'élimination vers l'arrière n'est pas destiné à déclencher l'altération à partir d'un prédicateur basse fréquence. Mais il ne commence l'altération qu'à partir de données à haute fréquence car la complexité du modèle dépend principalement de cette partie.
- Contourner le sur-ajustement: La situation de sur-ajustement se produit lorsque le modèle a obtenu trop d'ensembles de données et qu'une classification ou une prédiction est effectuée dans laquelle certains prédicateurs ont obtenu le bruit d'autres classes. Dans ce montage, le modèle devait donner une précision étonnamment élevée. En cas de surajustement, le modèle peut ne pas classer la variable en raison de la confusion créée dans la logique en raison de trop de conditions. La technique d'élimination vers l'arrière réduit la caractéristique étrangère pour contourner la situation de sur-ajustement.
2. Démérites
Les démérites de l'élimination en amont sont les suivantes:
- Dans la méthode d'élimination vers l'arrière, on ne peut pas savoir quel prédicateur est responsable du rejet d'un autre prédicateur en raison de son atteinte à l'insignifiance. Par exemple, si le prédicateur X a une certaine signification qui était suffisamment bonne pour résider dans un modèle après avoir ajouté le prédicateur Y. Mais l'importance de X devient obsolète lorsqu'un autre prédicteur Z entre dans le modèle. Ainsi, l'algorithme d'élimination vers l'arrière n'indique aucune dépendance entre deux prédicteurs qui se produit dans la «technique de sélection vers l'avant».
- Après avoir supprimé une fonction d'un modèle par un algorithme d'élimination en arrière, cette fonction ne peut plus être sélectionnée. En bref, l'élimination vers l'arrière n'a pas une approche flexible pour ajouter ou supprimer des fonctionnalités / prédicteurs.
- Les normes pour sélectionner la valeur de signification (0, 06) dans le modèle sont inflexibles. L'élimination en amont n'a pas de procédure flexible pour non seulement choisir mais aussi changer la valeur insignifiante selon les besoins afin d'obtenir le meilleur ajustement sous un ensemble de données adéquat.
Conclusion
La technique d'élimination vers l'arrière réalisée pour améliorer les performances du modèle et optimiser sa complexité. Il est très utilisé dans plusieurs régressions où le modèle traite de l'ensemble de données étendu. Il s'agit d'une approche facile et simple à comparer à la sélection directe et à la validation croisée dans laquelle une surcharge d'optimisation s'est produite. La technique d'élimination vers l'arrière initie l'élimination des caractéristiques de valeur de signification plus élevée. Son objectif fondamental est de rendre le modèle moins complexe et d'interdire les situations de sur-ajustement.
Articles recommandés
Ceci est un guide pour l'élimination en arrière. Ici, nous discutons comment appliquer l'élimination en arrière avec les mérites et les démérites. Vous pouvez également consulter les articles suivants pour en savoir plus-
- Apprentissage automatique hyperparamètre
- Clustering dans l'apprentissage automatique
- Machine virtuelle Java
- Apprentissage automatique non supervisé