
Introduction aux fichiers R CSV
Les fichiers CSV sont largement utilisés pour stocker les informations sous forme de tableau, chaque ligne étant un enregistrement de données. Afin de lire, écrire ou manipuler des données dans R, nous devons avoir certaines données disponibles avec nous. Les données peuvent être trouvées sur Internet ou peuvent être recueillies auprès de diverses sources telles que des enquêtes. En utilisant R, on peut lire, écrire et éditer les données qui sont stockées dans un environnement externe. R peut lire et écrire des données de divers formats comme XML, CSV et Excel. Dans cet article, nous verrons comment R peut être utilisé pour lire, écrire et effectuer différentes opérations sur des fichiers CSV.
Création d'un fichier CSV dans R
Dans cette section, nous verrons comment un bloc de données peut être créé et exporté vers le fichier CSV dans R. Dans le premier, nous allons créer un bloc de données qui comprend les variables employé et salaire respectif.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
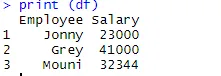
Une fois la trame de données créée, il est temps d'utiliser la fonction d'exportation de R pour créer un fichier CSV dans R. Afin d'exporter la trame de données dans CSV, nous pouvons utiliser le code ci-dessous.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
Dans la ligne de code ci-dessus, nous avons fourni un répertoire de chemin pour notre renommée de données et stocké la trame de données au format CSV. Dans le cas ci-dessus, le fichier CSV a été enregistré sur mon bureau personnel. Ce fichier particulier sera utilisé dans notre tutoriel pour effectuer plusieurs opérations.
Lecture de fichiers CSV dans R
Lors de l'analyse avec R, dans de nombreux cas, nous devons lire les données du fichier CSV. R est très fiable lors de la lecture de fichiers CSV. Dans l'exemple ci-dessus, nous avons créé le fichier, que nous utiliserons pour lire à l'aide de la commande read.csv. Voici l'exemple pour le faire dans R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

La commande ci-dessus lit le fichier Employee.csv qui est disponible sur le bureau et l'affiche dans R studio. La commande d'en-tête implique que l'en-tête est rendu disponible pour l'ensemble de données et la commande sep implique que les données sont séparées par des virgules.
Écrire des fichiers CSV en R
L'écriture dans un fichier CSV est l'une des fonctionnalités les plus utiles disponibles dans R pour un analyste de données. Cela peut être utilisé pour écrire un fichier CSV modifié dans un nouveau fichier CSV afin d'analyser les données. La commande Write.csv est utilisée pour écrire le fichier sur CSV.
Dans le code ci-dessous df dans le bloc de données dans lequel nos données sont disponibles, ajouter est utilisé pour spécifier que le nouveau fichier est créé au lieu d'ajouter ou d'écraser dans l'ancien fichier. Ajouter faux suggère qu'un nouveau fichier CSV est créé. Sep représente le champ séparé par une virgule.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
Opérations CSV
Les opérations CSV sont nécessaires pour inspecter les données une fois qu'elles ont été chargées dans le système. R dispose de plusieurs fonctionnalités intégrées pour vérifier et inspecter les données. Ces opérations fournissent des informations complètes concernant l'ensemble de données.
L'une des commandes les plus couramment utilisées est un résumé.
> summary(df)
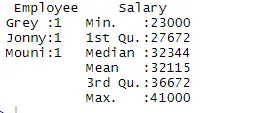
La commande de résumé nous fournit des statistiques par colonne. La variable numérique est décrite d'une manière statistique qui inclut des résultats statistiques tels que la moyenne, la min, la médiane et la max. Dans l'exemple ci-dessus, deux variables qui sont Employé et Salaire sont séparées et les statistiques pour la variable numérique qui est Salaire nous sont présentées.
La commande View () est utilisée pour ouvrir l'ensemble de données dans un autre onglet et le vérifier manuellement.
> View(df)

La fonction Str fournira aux utilisateurs plus de détails concernant la colonne de l'ensemble de données. Dans l'exemple ci-dessous, nous pouvons voir que la variable Employee a Factor comme type de données et la variable Salary a int (integer) comme type de données.
> str(df)

Dans de nombreux cas, nous devrons voir le nombre total de lignes disponibles dans le cas de l'ensemble de données volumineux, pour lequel nous pouvons utiliser la commande nrow (). Veuillez voir l'exemple ci-dessous.
> # to show the total number of rows in the dataset
> nrow(df)

De manière similaire pour afficher le nombre total de colonnes, nous pouvons utiliser la commande ncol ()
> ncol(df)

R nous permet d'afficher le nombre de lignes souhaité à l'aide de la commande ci-dessous. Lorsque leur nombre n de lignes disponibles dans l'ensemble de données, nous pouvons spécifier la plage de lignes à afficher.
> # to display first 2 rows of the data
> df(1:2, )

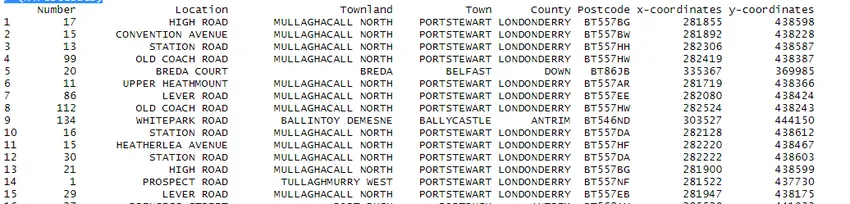
L'opération de données est effectuée sur l'ensemble de données volumineuses. À titre d'illustration, j'ai téléchargé le jeu de données open source de code postal NI sur Internet.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
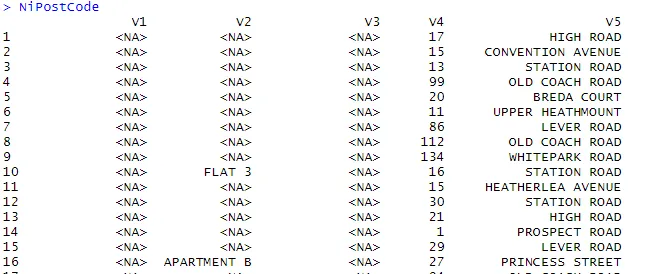
Dans l'ensemble de données ci-dessus, nous pouvons voir que les noms d'en-tête sont manquants et que de nombreuses valeurs nulles sont présentes. L'ensemble de données doit être nettoyé afin d'être prêt pour l'analyse. À l'étape suivante, les en-têtes seront des noms en conséquence.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Maintenant, comptons le nombre de valeurs manquantes dans la trame de données, puis supprimons-les en conséquence.
> # count of all missing values
> table(is.na (NiPostCode))

À partir de la commande ci-dessus, nous pouvons voir que le nombre total de blancs ou de NA dans la trame de données est proche de 5445148. La suppression de toutes les valeurs nulles entraînera la perte de l'énorme quantité de données, il est donc sage de supprimer les colonnes où plus de la moitié de 50% des données sont manquantes.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Conclusion
Dans ce didacticiel, nous avons vu comment les fichiers CSV peuvent être créés, lus et ajoutés à l'aide d'opérations dans R. Nous avons appris à créer un nouvel ensemble de données dans R, puis à l'importer au format CSV. Nous avons également vu plusieurs opérations telles que renommer l'en-tête et compter le nombre de lignes et de colonnes.
Articles recommandés
Ceci est un guide des fichiers R CSV. Nous discutons ici de la création, de la lecture et de l'écriture d'un fichier CSV en R avec les opérations CSV. Vous pouvez également consulter l'article suivant pour en savoir plus -
- JSON vs CSV
- Processus d'exploration de données
- Carrières en analyse de données
- Excel vs CSV