

Introduction à l'architecture HBase
HBase est un système de stockage de données clé-valeur distribué et open source et une base de données orientée colonnes avec une sortie d'écriture élevée et une lecture aléatoire à faible latence. En utilisant HBase, nous pouvons effectuer des analyses en ligne en temps réel. L'architecture HBase a une forte lisibilité aléatoire. Dans HBase, les données sont réparties physiquement dans ce que l'on appelle des régions. Chaque région est hébergée par un serveur de région unique et une ou plusieurs régions sont responsables de chaque serveur de région. L'architecture HBase est composée de serveurs maître-esclave. Le cluster HBase a un nœud maître appelé HMaster et plusieurs serveurs de région appelés HRegion Server (HRegion Server). Il existe plusieurs régions - régions dans chaque serveur régional.
Mécanisme de stockage HDFS

Dans HDFS, les données sont stockées dans le tableau comme indiqué ci-dessus.
Chaque ligne a une clé.
Colonne: Il s'agit d'une collection de données qui appartient à une famille de colonnes et qui est incluse dans la ligne.
Famille de colonnes: chaque famille de colonnes comprend une ou plusieurs colonnes.
Chaque table contient une collection de familles de colonnes. Ces colonnes ne font pas partie du schéma.
HBase a des colonnes dynamiques. Différentes cellules peuvent avoir différentes colonnes car les noms de colonne sont codés à l'intérieur des cellules
Qualificateur de colonne: le nom de la colonne est appelé qualificatif de colonne.
Composants d'architecture HBase
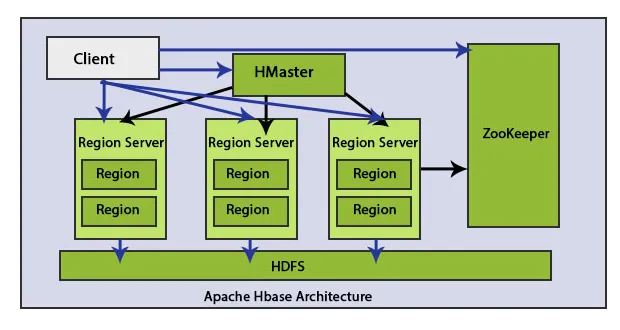
Il existe des éléments principaux dans l'architecture HBase: HMaster et Region Server. Données régionales d'enregistrement HBase.
1. HMaster
Le nœud HMaster est léger et utilisé pour affecter la région à la région du serveur.
Il y a quelques responsabilités principales de Hmaster qui sont:
- Effectuer certaines tâches d'administration, notamment le chargement, l'équilibrage, la création de données, la mise à jour, la suppression, etc.
Responsable des changements dans le schéma ou des modifications des données META selon la direction de l'application cliente
- Une grande partie du travail DDL sur les tables HBase est gérée par HMaster.
Certaines des méthodes exposées par l'interface HMaster le sont principalement. Méthodes orientées données META.
- Tableau (créer, supprimer, activer, désactiver, supprimer le tableau)
- ColumnFamily (ajouter une colonne, modifier la colonne)
- Région (déplacer, attribuer)
Le client communique avec HMaster et ZooKeeper de manière bidirectionnelle. Il contacte directement les serveurs HRegion pour lire et écrire les opérations. HMaster attribue des régions aux serveurs de la région et, à son tour, vérifie l'état de santé des serveurs régionaux.
2. Serveur de région
Nous pouvons avoir une idée approximative du serveur de région par un diagramme ci-dessous.

Les serveurs de région sont des nœuds de travail qui gèrent les demandes de lecture, d'écriture, de mise à jour et de suppression des clients. Le serveur de région est léger, il s'exécute sur tous les nœuds du cluster Hadoop. La tâche principale du serveur de région est d'enregistrer les données dans des zones et d'exécuter les demandes des clients. Une autre tâche importante du serveur de région HBase consiste à utiliser la méthode de partage automatique pour effectuer l'équilibrage de charge en distribuant dynamiquement la table HBase lorsqu'elle devient trop volumineuse après l'insertion de données.
Plusieurs serveurs HRegion peuvent être contactés par HMaster et remplissent les fonctions suivantes:
- Gestion et hébergement des régions
- Régions divisées automatiquement
- Traitement des demandes de lecture et d'écriture
- Communication directe avec les clients
3. HDFS
HDFS signifie le système de fichiers distribués Hadoop. Il stocke chaque fichier dans plusieurs blocs et réplique les blocs sur un cluster Hadoop pour maintenir la tolérance aux pannes. HDFS offre une tolérance élevée aux pannes et fonctionne avec des matériaux à faible coût. En utilisant du matériel bon marché pour ajouter des nœuds au cluster et le traiter et le sauvegarder, le client obtiendra de meilleurs résultats que le matériel existant. HDFS contacte les composants de HBase et enregistre beaucoup de données de manière distribuée.
4. Gardien
Zookeeper est un projet open-source. HMaster et HRegionServers s'enregistrent auprès de ZooKeeper.
Il fournit divers services tels que la maintenance des informations de configuration, le nommage, la synchronisation distribuée, etc. La synchronisation distribuée est le processus de fourniture de services de coordination entre les nœuds pour accéder aux applications en cours d'exécution. Il a des nœuds éphémères qui représentent des serveurs de région. Les serveurs maîtres utilisent ces nœuds pour rechercher les serveurs disponibles.
Ces nœuds sont également utilisés pour suivre les partitions réseau et les pannes de serveur. Zookeeper est le support d'interaction entre le serveur de région client. Si un client veut communiquer avec le serveur de région, alors zookeeper est le moyen de communication entre eux.
Comment la recherche s'initialise dans l'architecture HBase
Comme vous le savez, l'emplacement de la table META est enregistré par Zookeeper. Chaque fois qu'un client aborde ou écrit des demandes pour HBase, la procédure est la suivante.
Le client découvre auprès de ZooKeeper comment placer les tables META. Le client demande ensuite la clé de ligne appropriée à leur table META pour accéder à l'emplacement du serveur de région. Avec l'emplacement de la table META, le client met en cache ces informations. Le client ne doit pas s'y référer au tableau META tant que la zone n'est pas déplacée ou déplacée. Ensuite, le serveur META sera à nouveau demandé et le cache sera mis à jour. Comme toujours, les clients ne perdent pas de temps à trouver l'emplacement du serveur régional sur META Server, ce qui permet de gagner du temps et d'accélérer le processus de recherche.
traits
Il est facile à intégrer depuis la source et la destination avec Hadoop.
Le stockage distribué comme HDFS est pris en charge.
Il dispose d'une fonction d'accès aléatoire en utilisant une table de hachage interne pour stocker les données pour des recherches plus rapides dans les fichiers HDFS.
Avantages de l'architecture HBase
- Ceux-ci peuvent stocker de grands ensembles de données
- Nous pouvons partager la base de données
- Gigaoctets à pétaoctets rentables
- Haute disponibilité grâce à la réplication et à l'échec
Inconvénients de l'architecture HBase
- La structure SQL ne prend pas en charge
- Ne prend pas en charge la transaction
- Uniquement avec clé triée
- Problèmes de mémoire de cluster
Conclusion
HBase est l'une des bases de données distribuées orientées colonnes NonSql dans apache. Lors de la comparaison avec Hadoop ou Hive, HBase fonctionne mieux pour récupérer moins d'enregistrements. Donc, dans cet article, nous avons discuté de l'architecture HBase et de ses composants importants.
Articles recommandés
Cela a été un guide pour l'architecture HBase. Ici, nous avons discuté du concept, des composants, des fonctionnalités, des avantages et des inconvénients. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Qu'est-ce que la technologie Big Data?
- HDFS vs HBase, lequel est le meilleur
- Qu'est-ce que le langage d'assemblage?
- Introduction au HTML