
Introduction aux modèles d'apprentissage automatique
Un aperçu des différents modèles d'apprentissage automatique utilisés dans la pratique. Selon la définition, un modèle d'apprentissage automatique est une configuration mathématique obtenue après l'application de méthodologies d'apprentissage automatique spécifiques. En utilisant la vaste gamme d'API, la construction d'un modèle d'apprentissage automatique est assez simple de nos jours avec moins de lignes de codes. Mais la véritable compétence d'un professionnel de la science des données appliquée réside dans le choix du modèle correct en fonction de l'énoncé du problème et de la validation croisée au lieu de lancer des données de manière aléatoire vers des algorithmes sophistiqués. Dans cet article, nous aborderons différents modèles d'apprentissage automatique et comment les utiliser efficacement en fonction du type de problèmes qu'ils abordent.
Types de modèles d'apprentissage automatique
En fonction du type de tâches, nous pouvons classer les modèles d'apprentissage automatique dans les types suivants:
- Modèles de classification
- Modèles de régression
- Regroupement
- Réduction de la dimensionnalité
- Deep Learning etc.
1) Classification
En ce qui concerne l'apprentissage automatique, la classification est la tâche de prédire le type ou la classe d'un objet dans un nombre fini d'options. La variable de sortie pour la classification est toujours une variable catégorielle. Par exemple, prédire qu'un e-mail est du spam ou non est une tâche de classification binaire standard. Maintenant, notons quelques modèles importants pour les problèmes de classification.
- Algorithme K-voisins les plus proches - simple mais exhaustif sur le plan des calculs.
- Naive Bayes - Basé sur le théorème de Bayes.
- Régression logistique - Modèle linéaire pour la classification binaire.
- SVM - peut être utilisé pour les classifications binaires / multiclasses.
- Arbre de décision - Classificateur basé sur ' If Else ', plus robuste aux valeurs aberrantes.
- Ensembles - Combinaison de plusieurs modèles d'apprentissage automatique assemblés pour obtenir de meilleurs résultats.
2) Régression
Dans la machine, l'apprentissage de la régression est un ensemble de problèmes où la variable de sortie peut prendre des valeurs continues. Par exemple, la prévision du prix d'une compagnie aérienne peut être considérée comme une tâche de régression standard. Notons quelques modèles de régression importants utilisés dans la pratique.
- Régression linéaire - Le modèle de référence le plus simple pour la tâche de régression ne fonctionne bien que lorsque les données sont linéairement séparables et que la multicolinéarité est très faible ou inexistante.
- Régression Lasso - Régression linéaire avec régularisation L2.
- Régression de crête - Régression linéaire avec régularisation L1.
- Régression SVM
- Régression de l'arbre de décision, etc.
3) Clustering
En termes simples, le clustering est la tâche de regrouper des objets similaires. Les modèles d'apprentissage automatique permettent d'identifier automatiquement des objets similaires sans intervention manuelle. Nous ne pouvons pas construire de modèles efficaces de machine learning supervisé (modèles qui doivent être formés avec des données sélectionnées ou étiquetées manuellement) sans données homogènes. Le clustering nous aide à y parvenir de manière plus intelligente. Voici quelques-uns des modèles de clustering les plus utilisés:
- K signifie - Simple mais souffre d'une grande variance.
- K signifie ++ - Version modifiée de K signifie.
- K médoïdes.
- Clustering agglomératif - Un modèle de clustering hiérarchique.
- DBSCAN - Algorithme de clustering basé sur la densité, etc.
4) Réduction de la dimensionnalité
La dimensionnalité est le nombre de variables prédictives utilisées pour prédire la variable indépendante ou la cible. Souvent dans les ensembles de données du monde réel, le nombre de variables est trop élevé. Trop de variables apportent également la malédiction du sur-ajustement aux modèles. En pratique, parmi ces grands nombres de variables, toutes les variables ne contribuent pas également à l'objectif et dans un grand nombre de cas, nous pouvons en fait conserver des variances avec un nombre de variables moindre. Énumérons quelques modèles couramment utilisés pour la réduction de la dimensionnalité.
- PCA - Il crée un nombre moindre de nouvelles variables à partir d'un grand nombre de prédicteurs. Les nouvelles variables sont indépendantes les unes des autres mais moins interprétables.
- TSNE - Fournit une intégration dimensionnelle inférieure des points de données de dimension supérieure.
- SVD - La décomposition en valeurs singulières est utilisée pour décomposer la matrice en parties plus petites afin de calculer efficacement.
5) Apprentissage en profondeur
Le deep learning est un sous-ensemble du machine learning qui traite des réseaux de neurones. Sur la base de l'architecture des réseaux de neurones, énumérons les principaux modèles d'apprentissage en profondeur:
- Perceptron multicouche
- Réseaux de neurones à convolution
- Réseaux de neurones récurrents
- Machine Boltzmann
- Encodeurs automatiques, etc.
Quel modèle est le meilleur?
Ci-dessus, nous avons pris des idées sur de nombreux modèles d'apprentissage automatique. Maintenant, une question évidente nous vient à l'esprit: «Quel est le meilleur modèle parmi eux? Cela dépend du problème en question et d'autres attributs associés tels que les valeurs aberrantes, le volume des données disponibles, la qualité des données, l'ingénierie des fonctionnalités, etc. En pratique, il est toujours préférable de commencer par le modèle le plus simple applicable au problème et d'augmenter la complexité progressivement par un réglage correct des paramètres et une validation croisée. Il existe un proverbe dans le monde de la science des données - «La validation croisée est plus fiable que la connaissance du domaine».
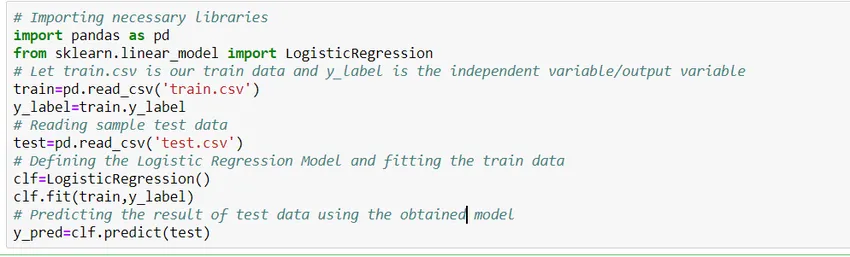
Comment construire un modèle?
Voyons comment construire un modèle de régression logistique simple à l'aide de la bibliothèque Scikit Learn de python. Pour simplifier, nous supposons que le problème est un modèle de classification standard et «train.csv» est le train et «test.csv» est le train et les données d'essai respectivement.
Conclusion
Dans cet article, nous avons discuté des modèles d'apprentissage machine importants utilisés à des fins pratiques et comment construire un modèle d'apprentissage machine simple en python. Le choix d'un modèle approprié pour un cas d'utilisation particulier est très important pour obtenir le bon résultat d'une tâche d'apprentissage automatique. Pour comparer les performances entre différents modèles, des métriques d'évaluation ou KPI sont définis pour des problèmes métier particuliers et le meilleur modèle est choisi pour la production après avoir appliqué la vérification statistique des performances.
Articles recommandés
Ceci est un guide des modèles d'apprentissage automatique. Nous discutons ici des 5 principaux types de modèles d'apprentissage automatique avec leur définition. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Méthodes d'apprentissage automatique
- Types d'apprentissage automatique
- Algorithmes d'apprentissage automatique
- Qu'est-ce que l'apprentissage automatique?
- Apprentissage automatique hyperparamètre
- KPI dans Power BI
- Algorithme de clustering hiérarchique
- Regroupement hiérarchique | Clustering Agglomératif & Diviseur