
Différence entre HBase et Cassandra
HBase est une base de données qui utilise le système de fichiers distribué Hadoop pour son stockage. HBase est une partie importante de HDFS et s'exécute au-dessus du cluster Hadoop. HBase n'est pas une base de données relationnelle traditionnelle, elle nécessite une approche de modélisation des données différente. Cassandra travaille sur le modèle de réplication des données, donc en cas d'indisponibilité d'un nœud, il n'y aura aucune perte de données. Cassandra est une base de données distribuée, ce qui signifie que les données sont accessibles par un client à partir de n'importe quel cluster et de n'importe quel nœud
1.1) Cassandre:
Il a été lancé par Facebook car il est toujours sur la demande. Cassandra a été lancée en 2005 et mise à la disposition du public en 2008. Cassandra a été développée pour des applications permanentes telles que les réseaux sociaux comme Facebook et Twitter.
Cassandra fonctionne sur une architecture «toujours active » et possède un modèle de nœud actif-actif, donc il n'y a pas de SPoF (point de défaillance unique). CQL (Cassandra Query Language) est le langage de requête de Cassandra mais ayant la même syntaxe que SQL. Il prend en charge tous les principaux systèmes d'exploitation tels que Linux, Unix, OSX et Windows.
Toujours allumé:
Cassandra est une base de données avec un modèle de distribution et tous les nœuds sont les mêmes au sein du cluster. Les données sont répliquées sur des nœuds configurables donc en cas d'échec de certains non. de nœuds n'entraînera pas la perte des données.
(Toujours sur le modèle)
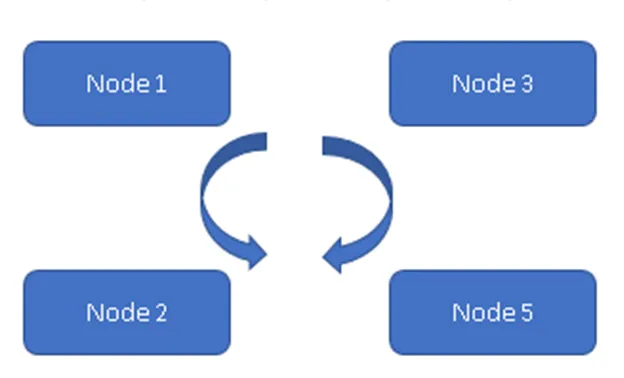
Dans la figure 1, les quatre nœuds sont synchronisés les uns avec les autres et répliquent les données au sein du cluster. Tous travaillent sur le modèle actif-actif, donc en cas de défaillance d'un nœud, cela n'entraînera pas de perte de données. Un client peut lire les données du reste des nœuds / nœuds disponibles.
1.2) HBase:
HBase est une base de données basée sur NoSQL et conçue pour traiter les requêtes dans de grandes tables ayant des milliards de lignes avec des millions de colonnes et s'exécutant sur un cluster de matériel standard / matériel. Il vous offre des capacités de requête en temps réel avec la vitesse d'un « magasin de clés / valeurs » .
HBase est en fait basé / fonctionne sur un modèle de données à quatre dimensions.
- ID de ligne / clé de ligne
- Famille de colonnes.
- Paires clé-valeur.
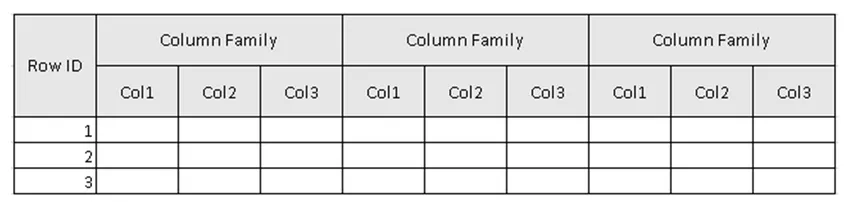
(Figure 2, exemple de schéma de la table dans HBase.)
Dans la figure 2, Table est la collection de familles de colonnes et la famille de colonnes est la collection de colonnes. Les colonnes sont la collection de paires clé-valeur
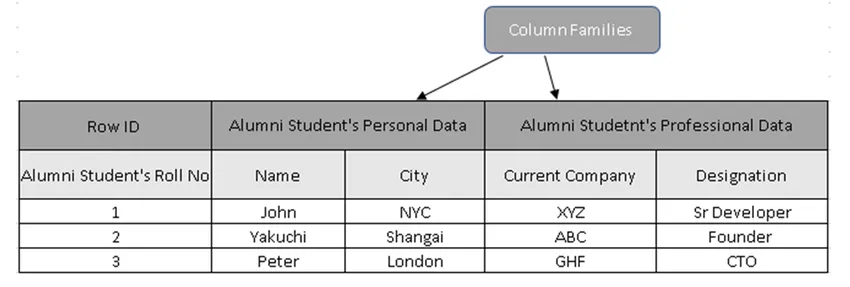
(Figure 3, exemple de tableau dans HBase)
Dans la figure 3, les familles de colonnes sont la collection de données sur les élèves diplômés et les ID de ligne (clés de ligne) contiennent le numéro de rôle de l'élève
En fait, les clés de ligne contiennent la valeur unique par rapport aux données de la famille de colonnes. En utilisant la clé de ligne, on peut extraire tous les détails, les raisons pour lesquelles les bases de données orientées colonnes sont beaucoup plus rapides que les bases de données traditionnelles.
Apache HBase peut être utilisé pour un accès aléatoire en lecture / écriture et fournit un support d'échec. Il prend également en charge la réplication et le travail sur le modèle de base de données de distribution.
Comparaison directe de HBase vs Cassandra (Infographie)
Voici la différence entre les 9 premiers HBase vs Cassandra
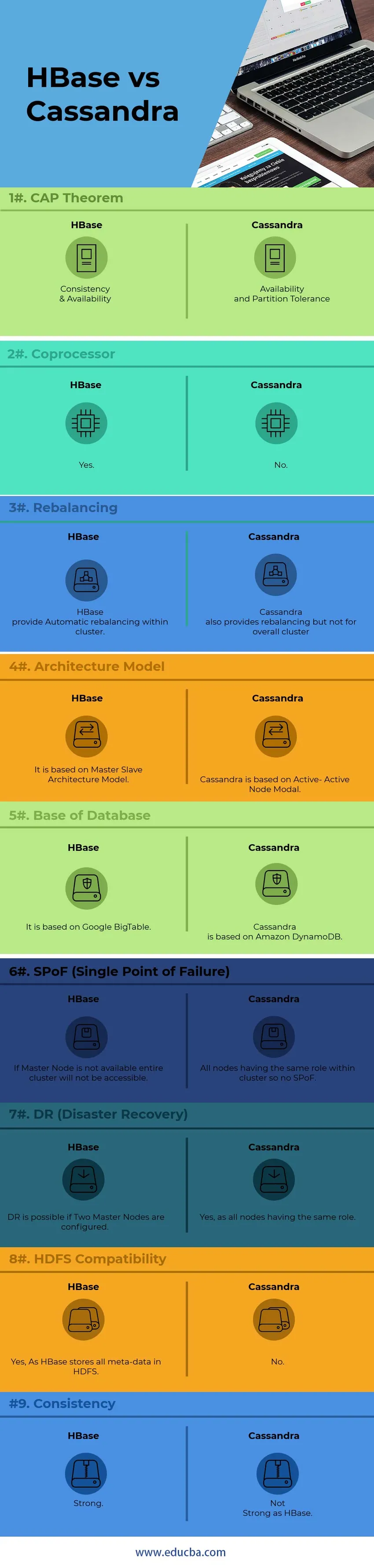 Différences clés entre HBase et Cassandra
Différences clés entre HBase et Cassandra
Voici les listes de points, décrivez les principales différences entre HBase et Cassandra:
1) Pour la communication des nœuds internes, Cassandra utilise le protocole GOSSIP tandis que HBase est basé sur Zookeeper. Les services du protocole GOSSIP sont intégrés à Cassandra de l'autre côté Zookeeper est une application de distribution entièrement distincte.
2) Dans l'architecture Cassandra, tous les nœuds fonctionnent comme un nœud actif tandis que l'architecte HBase suit le modèle de nœud maître-esclave. Dans le modèle Active-Active Node, il n'y a pas de SPoF (Single Point of Failure). Dans HBase, si le nœud maître tombe en panne, le cluster entier ne sera pas accessible.
3) HBase prend en charge le modèle de recherche d'arbre binaire tandis que Cassandra ne prend pas en charge le modèle d'arbre B Sans B-Tree, vous ne pouvez pas rechercher la famille de colonnes de l'utilisateur pour tout le monde avec un anniversaire en avril tandis que vous pouvez rechercher tous ceux qui vivent à Pékin avec un Anniversaire en avril.
4) HBase, prend en charge les langages de script C, C ++, Java, Python et Scala tandis que Cassandra prend également en charge JavaScript et Ruby.
5) HBase a une fonctionnalité appelée coprocesseur alors que Cassandra ne dispose pas d'une telle fonctionnalité pour l'instant. Les coprocesseurs fournissent une bibliothèque et un environnement d'exécution pour exécuter le code utilisateur dans le serveur de région HBase et les processus maîtres.
6) HBase est conçu pour prendre en charge l'entrepôt de données tandis que Cassandra sera parfait pour toutes les applications en cours d'exécution comme les applications Web et mobiles.
7) Le langage de requête HBase est un langage personnalisé qui doit être appris tandis que Cassandra utilise son propre langage CQL (Cassandra Query Language) développé qui est un langage de type SQL
8) La gestion de Cassandra est beaucoup plus facile que HBase. Dans Cassandra, un seul processus Java doit être exécuté par nœud tandis que pour HBase, HDFS pleinement opérationnel, plusieurs processus HBase et un système Zookeeper sont requis.
9) HBase fait des sommes de contrôle de bout en bout et un rééquilibrage automatique tandis que Cassandra ne prend pas en charge le rééquilibrage du cluster dans son ensemble.
10) Basé sur le « Théorème CAP», Cassandra travaille sur le modèle AP tandis que HBase est le modèle CP.
Théorème CAP
Ce théorème est utilisé pour les systèmes distribués. C signifie cohérence, A signifie disponibilité et P est tolérance de partition. Théorème du CAP expliqué ci-dessous:
C (cohérence): la cohérence signifie que si quelqu'un a écrit une valeur dans une base de données, les autres peuvent immédiatement lire la même valeur.
R (Disponibilité) : La disponibilité signifie que si certains nœuds ne sont pas disponibles dans votre cluster (les nœuds sont tombés en panne / ne vivent pas dans le cluster en raison d'un problème) n'auront pas d'impact sur l'ensemble du cluster et le système distribué / base de données sera disponible pour accéder aux données. Le Cluster sera accessible pour toutes sortes de tâches.
P (Tolérance de partition): La tolérance de partition signifie que si un centre de données tombe en panne, cela ne devrait pas affecter les données présentes sur les nœuds et toutes les données doivent être accessibles à tout moment. Moyens, la tolérance de partition permet une meilleure réplication des données vers d'autres centres de données ainsi que dans l'environnement de cluster.
Tableau de comparaison HBase vs Cassandra
| Points | HBase | Cassandra |
| Théorème CAP | Cohérence et disponibilité | Disponibilité et tolérance de partition |
| Coprocesseur | Oui | Non |
| Rééquilibrage | HBase fournit un rééquilibrage automatique au sein d'un cluster. | Cassandra fournit également un rééquilibrage mais pas pour le cluster global |
| Modèle d'architecture | Il est basé sur le modèle d'architecture maître-esclave | Cassandra est basé sur Active-Active Node Modal |
| Base de base de données | Il est basé sur Google BigTable | Cassandra est basée sur Amazon DynamoDB |
| SPoF (point de défaillance unique) | Si le nœud maître n'est pas disponible, le cluster entier ne sera pas accessible | Tous les nœuds ayant le même rôle au sein du cluster, donc pas de SPoF |
| DR (Disaster Recovery) | DR est possible si deux nœuds maîtres sont configurés. | Oui, car tous les nœuds ayant le même rôle |
| Compatibilité HDFS | Oui, comme HBase stocke toutes les métadonnées dans HDFS | Non |
| Cohérence | Fort | Pas aussi fort que HBase |
Conclusion - HBase vs Cassandra
Facebook et un autre côté des réseaux sociaux préféreraient HBase (auparavant, les deux utilisaient Cassandra, référez-vous à la publication Facebook) en raison de sa disponibilité, l'autre secteur du domaine bancaire recherche la sécurité pour chacune de ses transactions financières afin de sélectionner Cassandra plutôt que HBase.
Cassandra Les principales caractéristiques impliquent une haute disponibilité, une administration minimale et aucun SPoF (Single Point of Failure). L'autre côté HBase est bon pour une lecture et une écriture plus rapides des données avec une évolutivité linéaire.
Des entreprises comme Verizon, Bloomberg, Bank of America et bien d'autres utilisent HBase et Cassandra est utilisée par les principaux sites de réseaux sociaux tels que Twitter, Facebook, etc.
Nous ne pouvons pas conclure lequel est le meilleur, HBase et Cassandra ont tous deux leurs propres avantages et inconvénients. Les performances réelles des bases de données HBase et Cassandra sont visibles dans l'environnement de production.
Articles recommandés:
Ceci a été un guide pour HBase vs Cassandra, leur signification, leur comparaison tête à tête, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Hadoop vs Apache Spark - Choses intéressantes que vous devez savoir
- Comment cracker l'interview du développeur Hadoop?
- Top 5 des tendances Big Data
- 5 défis de l'analyse de Big Data