
Introduction à AWS Data Pipeline
Les données augmentent de façon exponentielle de jour en jour et deviennent difficiles à gérer par rapport au passé. Nous avons besoin d'outils et de services pour gérer nos données de manière efficace et à moindre coût, c'est là que l'AWS Data Pipeline vient à l'esprit. Il ne s'agit pas seulement de stocker des données, mais vous devez analyser, traiter, transformer les données dans la forme souhaitée au même endroit, tout cela peut être réalisé avec AWS Data Pipeline.
Besoin de pipeline de données
Essayons de comprendre la nécessité d'un pipeline de données avec l'exemple:
Exemple 1
Nous avons un site Web qui affiche des images et des gifs sur la base de recherches ou de filtres d'utilisateurs. Notre objectif principal est de diffuser du contenu. Il y a certains objectifs à atteindre qui sont les suivants: -
- Amélioration de la diffusion de contenu: servir ce que les utilisateurs veulent de manière efficace et assez rapide.
- Gérer efficacement l'application: stockage des données utilisateur ainsi que des journaux du site Web à des fins d'analyse ultérieures.
- Améliorer l'entreprise: l' utilisation des données et des analyses stockées prend la décision d'améliorer les affaires à moindre coût.
Exemple # 2
Il y a certains goulots d'étranglement à prendre en charge pour atteindre les objectifs:
- L'énorme quantité de données dans différents formats et à différents endroits qui rend le traitement, le stockage et la migration des données une tâche complexe.
Différents composants de stockage de données pour différents types de données:
- Données en temps réel possibles pour les utilisateurs enregistrés: Dynamo DB .
- Journaux du serveur Web pour les utilisateurs potentiels: Amazon S3 .
- Données démographiques et identifiants de connexion: Amazon RDS.
- Données de capteur et ensemble de données tiers: Amazon S3.
Solutions
- Solution réalisable: Nous pouvons voir que nous devons faire face à différents types d'outils pour convertir les données de non structurées en structurées pour l'analyse. Ici, nous devons utiliser différents outils pour stocker des données et à nouveau pour convertir, analyser et stocker des données traitées. Pas une solution rentable.
- Solution optimale: utilisez un pipeline de données qui gère le traitement, la visualisation et la migration. Le pipeline de données peut être utile dans la migration des données à partir de différents endroits, en analysant également les données et en les traitant au même endroit en votre nom.
Qu'est-ce que le pipeline de données AWS?
AWS Data Pipeline est essentiellement un service Web proposé par Amazon qui vous aide à transformer, traiter et analyser vos données de manière évolutive et fiable ainsi qu'à stocker les données traitées dans S3, DynamoDb ou votre base de données locale.
- Avec AWS Data Pipeline, vous pouvez facilement accéder aux données de différentes sources.
- Transformez et traitez ces données à grande échelle.
- Transférez efficacement les résultats vers d'autres services tels que S3, la table DynamoDb ou le magasin de données local.
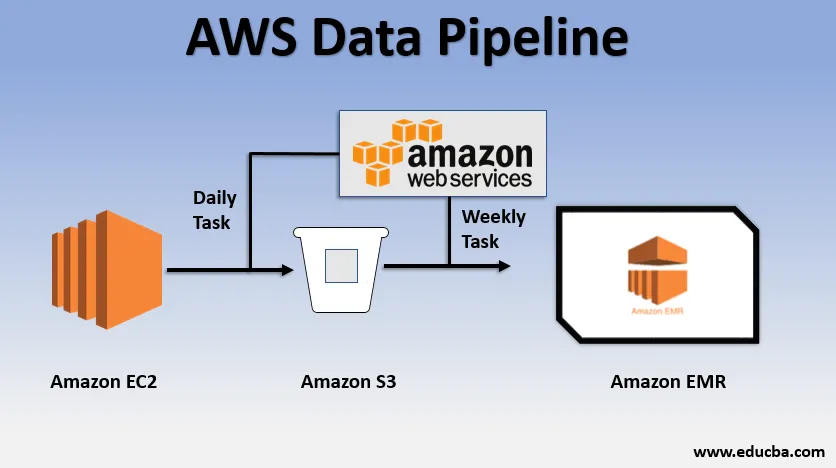
Exemple d'utilisation de base du pipeline de données
- Nous pourrions avoir un site Web déployé sur EC2 qui génère des journaux chaque jour.
- Une tâche quotidienne simple pourrait être la copie des fichiers journaux d'E2 et leur réalisation dans le compartiment S3.
- Une tâche hebdomadaire pourrait consister à traiter les données et à lancer l'analyse des données sur Amazon EMR pour générer des rapports hebdomadaires sur la base de toutes les données collectées.
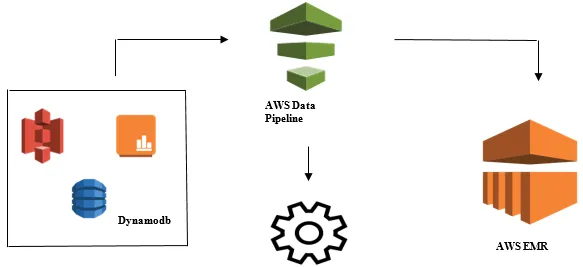
Lancement de l'analyse de données avec AWS Data Pipeline
- Collecte des données à partir de différentes sources de données telles que - S3, Dynamodb, sur site, données de capteur, etc.
- Effectuer la transformation, le traitement et l'analyse sur AWS EMR pour générer des rapports hebdomadaires.
- Rapport hebdomadaire enregistré dans Redshift, S3 ou une base de données sur site.
Avantages d'AWS Data Pipeline
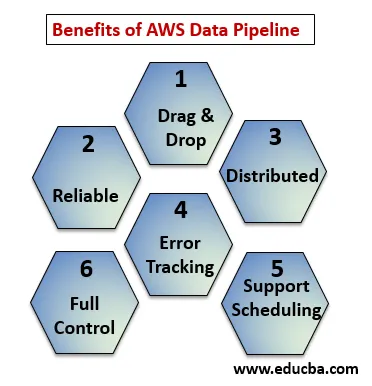
Les points ci-dessous expliquent les avantages d'AWS Data Pipeline:
- Console Drag and Drop facile à comprendre et à utiliser.
- Infrastructure distribuée et fiable: les pipelines de données fonctionnent sur des services évolutifs et sont fiables si une erreur ou une tâche échoue, il peut être configuré pour réessayer.
- Prise en charge de la planification et du suivi des erreurs: vous pouvez planifier vos tâches et suivre ce qui a échoué et réussi.
- Distribué: peut être exécuté en parallèle sur plusieurs machines ou de manière linéaire.
- Contrôle total sur les ressources de calcul comme EC2, les clusters EMR.
Composants AWS Data Pipeline
Voici les composants du pipeline de données AWS:
1. Définition du pipeline
Convertissez votre logique métier en AWS Data Pipeline.
- Noeuds de données : contient le nom, l'emplacement, le format de la source de données qu'il pourrait s'agir (S3, dynamodb, local)
- Activités : déplacer, transformer ou effectuer des requêtes sur vos données.
- Horaire : programmez vos activités quotidiennes ou hebdomadaires.
- Condition préalable : des conditions telles que le démarrage du planificateur vérifient la disponibilité des données à la source.
- Ressources : Calculer les ressources EC2, EMR.
- Actions : mise à jour sur le pipeline de données, envoi de notifications, alarme de déclenchement.
2. Pipelines
Ici, vous planifiez et exécutez les tâches pour effectuer des activités définies.
- Composants du pipeline : les composants du pipeline sont les mêmes que les composants de la définition du pipeline.
- Instances: lors de l' exécution des tâches, AWS compile tous les composants pour créer certaines instances exploitables. Ces instances contiennent toutes les informations sur des tâches spécifiques.
- Tentatives: nous avons déjà discuté de la fiabilité du pipeline de données avec ses mécanismes de nouvelle tentative. Vous définissez ici le nombre de fois que vous souhaitez réessayer la tâche en cas d'échec.
3. Task Runner
Demande ou interroge les tâches à partir du pipeline de données AWS, puis effectue ces tâches.
Tarification d'AWS Data Pipeline
Ci-dessous les points expliquent la tarification du pipeline de données AWS:
1. Niveau gratuit
Vous pouvez démarrer gratuitement avec AWS Data Pipeline dans le cadre du niveau d'utilisation gratuite d'AWS. Les nouveaux clients inscrits bénéficient chaque mois de quelques avantages gratuits pendant un an:
- 3 Conditions préalables de basse fréquence fonctionnant sur AWS sans aucun frais.
- 5 Activités de basse fréquence fonctionnant sur AWS sans aucun frais.
2. Basse fréquence
La basse fréquence est censée fonctionner une fois par jour ou moins. Le pipeline de données suit la même stratégie de facturation que les autres services Web AWS, c'est-à-dire facturé en fonction de votre utilisation. Il est facturé selon la fréquence à laquelle vos tâches, activités et conditions préalables s'exécutent chaque jour et où elles s'exécutent (AWS ou sur site). Les activités à haute fréquence doivent être exécutées plus d'une fois par jour.
Exemple: nous pouvons planifier une activité pour qu'elle s'exécute toutes les heures et traiter les journaux du site Web ou cela peut être toutes les 12 heures. Alors que les activités à basse fréquence sont celles qui se déroulent une fois par jour ou moins si les conditions préalables ne sont pas remplies. Les pipelines inactifs ont des états INACTIF, EN ATTENTE et FINI.
3. Prix d'AWS Data Pipeline indiqué par région
Région # 1: États-Unis Est (N.Virginia), États-Unis Ouest (Oregon), Asie-Pacifique (Sydney), UE (Irlande)
| Haute fréquence | Basse fréquence | |
| Activités ou conditions préalables exécutées sur AWS | 1, 00 $ par mois | 0, 06 $ par mois |
| Activités ou conditions préalables s'exécutant sur site | 2, 50 $ par mois | 1, 50 $ par mois |
| Pipelines inactifs: 1, 00 $ par mois |
Région # 2: Asie-Pacifique (Tokyo)
| Haute fréquence | Basse fréquence | |
| Activités ou conditions préalables exécutées sur AWS | 0, 95 $ 24 par mois | 0, 5715 $ par mois |
| Activités ou conditions préalables s'exécutant sur site | 2, 381 $ par mois | 1, 4286 $ par mois |
| Pipelines inactifs: 0, 9524 $ par mois |
Le pipeline qu'un travail quotidien, c'est-à-dire une activité basse fréquence sur AWS, pour déplacer des données de la table DynamoDB vers Amazon S3 coûterait 0, 60 $ par mois. Si nous ajoutons EC2 pour produire un rapport basé sur les données d'Amazon S3, le coût total du pipeline serait de 1, 20 $ par mois. Si nous exécutons cette activité toutes les 6 heures, cela coûterait 2, 00 $ par mois, car alors ce serait une activité à haute fréquence.
Conclusion
AWS Data Pipeline est une solution très pratique pour gérer les données à croissance exponentielle à moindre coût. Il est très fiable et évolutif en fonction de votre utilisation. Pour tout besoin commercial où il traite une grande quantité de données, AWS Data Pipeline est un très bon choix pour atteindre tous nos objectifs commerciaux.
Articles recommandés
Il s'agit d'un guide du AWS Data Pipeline. Nous discutons ici des besoins du pipeline de données, de ce qu'est le pipeline de données AWS, de ses détails sur les composants et les prix. Vous pouvez également consulter nos autres articles connexes pour en savoir plus -
- AWS EBS
- Bases de données AWS
- Qu'est-ce qu'AWS EC2?
- Avantages de la visualisation des données
- Les 7 meilleurs concurrents d'AWS avec des fonctionnalités
- Découvrez la liste des fonctionnalités d'Amazon Web Services