

Introduction à l'algorithme DFS
DFS est connu sous le nom de Depth First Search Algorithm qui fournit les étapes pour parcourir chaque nœud d'un graphique sans répéter aucun nœud. Cet algorithme est identique à Depth First Traversal pour un arbre, mais diffère en maintenant un booléen pour vérifier si le nœud a déjà été visité ou non. Ceci est important pour la traversée du graphe car des cycles existent également dans le graphe. Une pile est conservée dans cet algorithme pour stocker les nœuds suspendus pendant la traversée. Il est nommé ainsi parce que nous voyageons d'abord à la profondeur de chaque nœud adjacent, puis continuons à traverser un autre nœud adjacent.
Expliquer l'algorithme DFS
Cet algorithme est contraire à l'algorithme BFS où tous les nœuds adjacents sont visités suivis des voisins des nœuds adjacents. Il commence à explorer le graphique à partir d'un nœud et explore sa profondeur avant de revenir en arrière. Deux choses sont considérées dans cet algorithme:
- Visite d'un sommet : sélection d'un sommet ou d'un nœud du graphe à parcourir.
- Exploration d'un sommet : parcourant tous les nœuds adjacents à ce sommet.
Pseudo-code pour la première recherche de profondeur :
proc DFS_implement(G, v):
let St be a stack
St.push(v)
while St has elements
v = St.pop()
if v is not labeled as visited:
label v as visited
for all edge v to w in G.adjacentEdges(v) do
St.push(w)
La traversée linéaire existe également pour DFS qui peut être implémentée de 3 manières:
- Pré-commander
- En ordre
- PostOrder
Le post-ordre inverse est un moyen très utile de parcourir et utilisé dans le tri topologique ainsi que dans diverses analyses. Une pile est également conservée pour stocker les nœuds dont l'exploration est toujours en attente.
Graphique Traverse dans DFS
Dans DFS, les étapes ci-dessous sont suivies pour parcourir le graphique. Par exemple, pour un graphe donné, commençons la traversée à partir de 1:
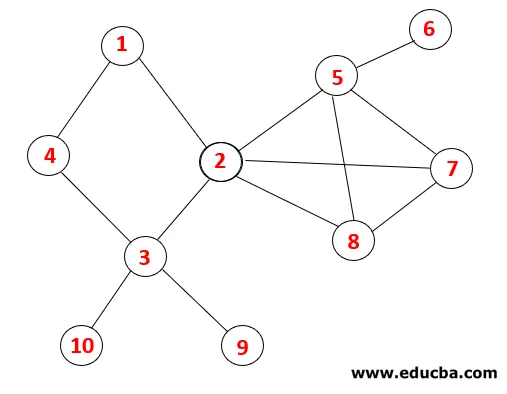
| Empiler | Séquence de traversée | Spanning Tree |
| 1 |  |
|
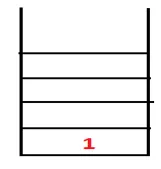 | 1, 4 |  |
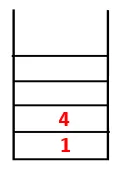 | 1, 4, 3 |  |
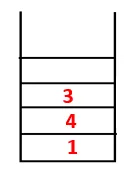 | 1, 4, 3, 10 | 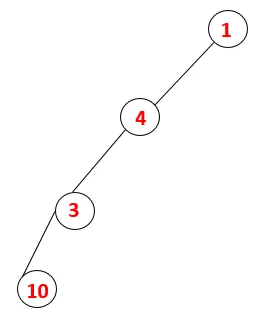 |
 | 1, 4, 3, 10, 9 | 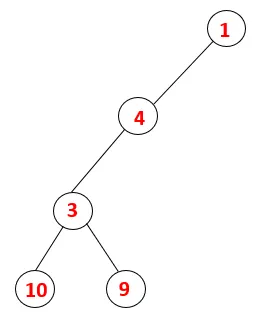 |
 | 1, 4, 3, 10, 9, 2 | 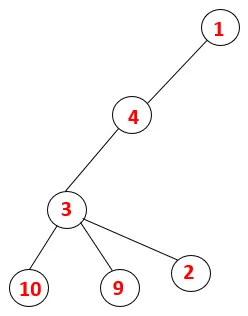 |
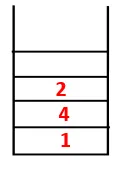 | 1, 4, 3, 10, 9, 2, 8 |  |
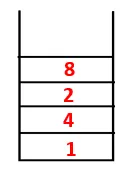 | 1, 4, 3, 10, 9, 2, 8, 7 | 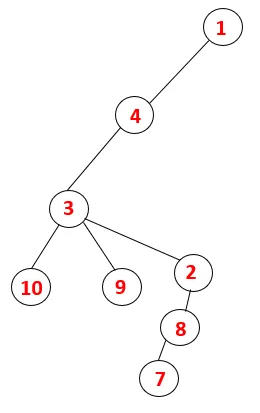 |
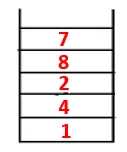 | 1, 4, 3, 10, 9, 2, 8, 7, 5 |  |
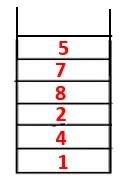 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 | 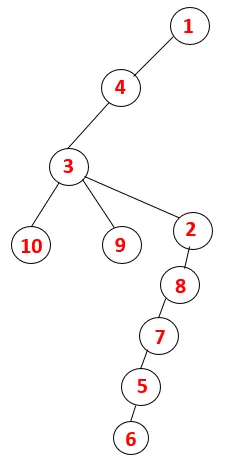 |
 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 | 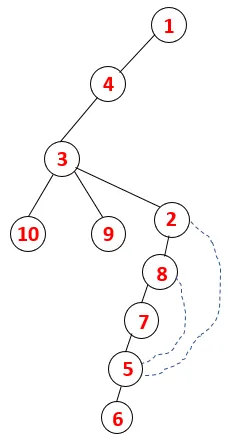 |
 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 |  |
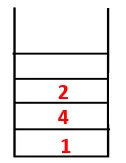 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 | 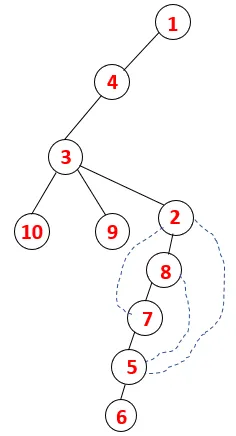 |
 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 |  |
 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 |  |
 | 1, 4, 3, 10, 9, 2, 8, 7, 5, 6 | 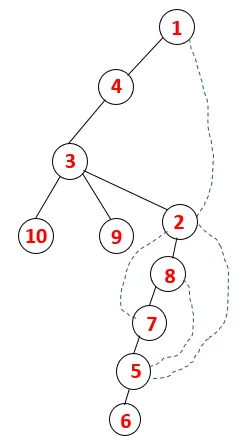 |
Explication de l'algorithme DFS
Voici les étapes de l'algorithme DFS avec des avantages et des inconvénients:
Étape 1 : le nœud 1 est visité et ajouté à la séquence ainsi qu'à l'arbre couvrant.
Étape 2: Les nœuds adjacents de 1 sont explorés, c'est-à-dire 4, donc 1 est poussé pour empiler et 4 est poussé dans la séquence ainsi que l'arbre couvrant.
Étape 3: L'un des nœuds adjacents de 4 est exploré et ainsi 4 est poussé vers la pile, et 3 entre dans la séquence et l'arbre couvrant.
Étape 4: les nœuds adjacents de 3 sont explorés en les poussant sur la pile et 10 entre dans la séquence. Comme il n'y a pas de nœud adjacent à 10, 3 est donc sorti de la pile.
Étape 5: Un autre nœud adjacent de 3 est exploré et 3 est poussé sur la pile et 9 est visité. Aucun nœud adjacent de 9 donc 3 n'est sorti et le dernier nœud adjacent de 3 c'est-à-dire 2 est visité.
Un processus similaire est suivi pour tous les nœuds jusqu'à ce que la pile devienne vide, ce qui indique la condition d'arrêt de l'algorithme de traversée. - -> les lignes pointillées dans l'arbre couvrant se réfèrent aux arêtes arrières présentes dans le graphique.
De cette façon, tous les nœuds du graphe sont parcourus sans répéter aucun des nœuds.
Avantages et inconvénients
- Avantages: La mémoire requise pour cet algorithme est très inférieure. Complexité spatiale et temporelle moindre que BFS.
- Inconvénients: La solution n'est pas garantie Applications. Tri topologique. Trouver des ponts de graphique.
Exemple pour implémenter l'algorithme DFS
Voici l'exemple pour implémenter l'algorithme DFS:
Code:
import java.util.Stack;
public class DepthFirstSearch (
static void depthFirstSearch(int()() matrix, int source)(
boolean() visited = new boolean (matrix.length);
visited(source-1) = true;
Stack stack = new Stack();
stack.push(source);
int i, x;
System.out.println("Depth of first order is");
System.out.println(source);
while(!stack.isEmpty())(
x= stack.pop();
for(i=0;i if(matrix(x-1)(i) == 1 && visited(i) == false)(
stack.push(x);
visited(i)=true;
System.out.println(i+1);
x=i+1;
i=-1;
)
)
)
)
public static void main(String() args)(
int vertices=5;
int()() mymatrix = new int(vertices)(vertices);
for(int i=0;i for(int j=0;j mymatrix(i)(j)= i+j;
)
)
depthFirstSearch(mymatrix, 5);
)
)import java.util.Stack;
public class DepthFirstSearch (
static void depthFirstSearch(int()() matrix, int source)(
boolean() visited = new boolean (matrix.length);
visited(source-1) = true;
Stack stack = new Stack();
stack.push(source);
int i, x;
System.out.println("Depth of first order is");
System.out.println(source);
while(!stack.isEmpty())(
x= stack.pop();
for(i=0;i if(matrix(x-1)(i) == 1 && visited(i) == false)(
stack.push(x);
visited(i)=true;
System.out.println(i+1);
x=i+1;
i=-1;
)
)
)
)
public static void main(String() args)(
int vertices=5;
int()() mymatrix = new int(vertices)(vertices);
for(int i=0;i for(int j=0;j mymatrix(i)(j)= i+j;
)
)
depthFirstSearch(mymatrix, 5);
)
)import java.util.Stack;
public class DepthFirstSearch (
static void depthFirstSearch(int()() matrix, int source)(
boolean() visited = new boolean (matrix.length);
visited(source-1) = true;
Stack stack = new Stack();
stack.push(source);
int i, x;
System.out.println("Depth of first order is");
System.out.println(source);
while(!stack.isEmpty())(
x= stack.pop();
for(i=0;i if(matrix(x-1)(i) == 1 && visited(i) == false)(
stack.push(x);
visited(i)=true;
System.out.println(i+1);
x=i+1;
i=-1;
)
)
)
)
public static void main(String() args)(
int vertices=5;
int()() mymatrix = new int(vertices)(vertices);
for(int i=0;i for(int j=0;j mymatrix(i)(j)= i+j;
)
)
depthFirstSearch(mymatrix, 5);
)
)import java.util.Stack;
public class DepthFirstSearch (
static void depthFirstSearch(int()() matrix, int source)(
boolean() visited = new boolean (matrix.length);
visited(source-1) = true;
Stack stack = new Stack();
stack.push(source);
int i, x;
System.out.println("Depth of first order is");
System.out.println(source);
while(!stack.isEmpty())(
x= stack.pop();
for(i=0;i if(matrix(x-1)(i) == 1 && visited(i) == false)(
stack.push(x);
visited(i)=true;
System.out.println(i+1);
x=i+1;
i=-1;
)
)
)
)
public static void main(String() args)(
int vertices=5;
int()() mymatrix = new int(vertices)(vertices);
for(int i=0;i for(int j=0;j mymatrix(i)(j)= i+j;
)
)
depthFirstSearch(mymatrix, 5);
)
)
Production:
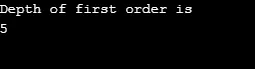
Explication du programme ci-dessus: Nous avons fait un graphique ayant 5 sommets (0, 1, 2, 3, 4) et utilisé le tableau visité pour garder une trace de tous les sommets visités. Ensuite, pour chaque nœud dont les nœuds adjacents existent, le même algorithme se répète jusqu'à ce que tous les nœuds soient visités. Ensuite, l'algorithme revient à appeler le sommet et le fait sauter de la pile.
Conclusion
Les besoins en mémoire de ce graphique sont inférieurs à ceux de BFS car une seule pile est nécessaire pour être maintenue. Un arbre couvrant DFS et une séquence de traversée sont générés en conséquence mais ne sont pas constants. La séquence de traversée multiple est possible selon le sommet de départ et le sommet d'exploration choisis.
Articles recommandés
Ceci est un guide de l'algorithme DFS. Ici, nous discutons de l'explication étape par étape, parcourons le graphique dans un format de tableau avec des avantages et des inconvénients. Vous pouvez également consulter nos autres articles connexes pour en savoir plus -
- Qu'est-ce que HDFS?
- Algorithmes d'apprentissage profond
- Commandes HDFS
- Algorithme SHA