

Introduction aux techniques de science des données
Dans le monde actuel où les données sont le nouvel or, il existe différents types d'analyses disponibles pour une entreprise. Le résultat d'un projet de science des données varie considérablement en fonction du type de données disponibles et, par conséquent, l'impact est également variable. Puisqu'il existe de nombreux types d'analyses différents, il devient impératif de comprendre quelles techniques de base doivent être sélectionnées. L'objectif essentiel des techniques de science des données est non seulement de rechercher des informations pertinentes, mais également de détecter les maillons faibles qui tendent à rendre le modèle peu performant.
Qu'est-ce que la science des données?
La science des données est un domaine qui s'étend sur plusieurs disciplines. Il incorpore des méthodes, des processus, des algorithmes et des systèmes scientifiques pour recueillir des connaissances et travailler dessus. Ce domaine comprend une variété de genres et est une plate-forme commune pour l'unification des concepts de statistiques, d'analyse de données et d'apprentissage automatique. En cela, les connaissances théoriques des statistiques ainsi que les données et les techniques en temps réel en apprentissage automatique fonctionnent main dans la main pour obtenir des résultats fructueux pour l'entreprise. En utilisant différentes techniques employées dans la science des données, nous dans le monde d'aujourd'hui pouvons impliquer une meilleure prise de décision qui, autrement, pourrait manquer à l'œil et à l'esprit humains. N'oubliez pas que la machine n'oublie jamais! Pour maximiser les profits dans un monde axé sur les données, la magie de la science des données est un outil indispensable.
Différents types de techniques de science des données
Dans les quelques paragraphes suivants, nous examinerons les techniques courantes de science des données utilisées dans tous les autres projets. Bien que parfois la technique de la science des données puisse être spécifique à un problème commercial et ne pas tomber dans les catégories ci-dessous, il est parfaitement correct de les qualifier de types divers. À un niveau élevé, nous divisons les techniques en supervisé (nous connaissons l'impact cible) et non supervisé (nous ne connaissons pas la variable cible que nous essayons d'atteindre). Au niveau suivant, les techniques peuvent être divisées en termes de
- Le résultat que nous obtiendrions ou quelle est l'intention du problème commercial
- Type de données utilisées.
Voyons d'abord la ségrégation basée sur l'intention.
1. Apprentissage non supervisé
- Détection d'une anomalie
Dans ce type de technique, nous identifions toute occurrence inattendue dans l'ensemble de données. Étant donné que le comportement diffère de la réalité des données, les hypothèses sous-jacentes sont les suivantes:
- L'occurrence de ces instances est très faible.
- La différence de comportement est significative.
Les algorithmes d'anomalies sont expliqués, comme la forêt d'isolement, qui fournit un score pour chaque enregistrement d'un ensemble de données. Cet algorithme est un modèle arborescent. En utilisant ce type de technique de détection et sa popularité, ils sont utilisés dans divers cas commerciaux, par exemple, les pages Web, le taux de désabonnement, le revenu par clic, etc. Dans le graphique ci-dessous, nous pouvons expliquer à quoi ressemble une anomalie.
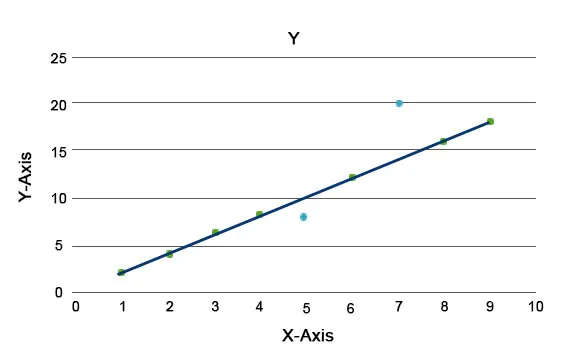
Ici, ceux en bleu représentent une anomalie dans l'ensemble de données. Ils varient de la ligne de tendance régulière et sont moins présents.
- Analyse de clustering
Grâce à cette analyse, la tâche principale consiste à séparer l'ensemble des données en groupes afin que la tendance ou les traits d'un point de données de groupe soient assez similaires les uns aux autres. Dans la terminologie de la science des données, nous les appelons le cluster. Par exemple, dans le commerce de détail, il est prévu de faire évoluer l'entreprise et il devient impératif de savoir comment les nouveaux clients se comporteraient dans une nouvelle région sur la base des données antérieures dont nous disposons. Il devient impossible de concevoir une stratégie pour chaque individu d'une population, mais il sera utile de regrouper la population en grappes afin que la stratégie soit efficace dans un groupe et évolutive.
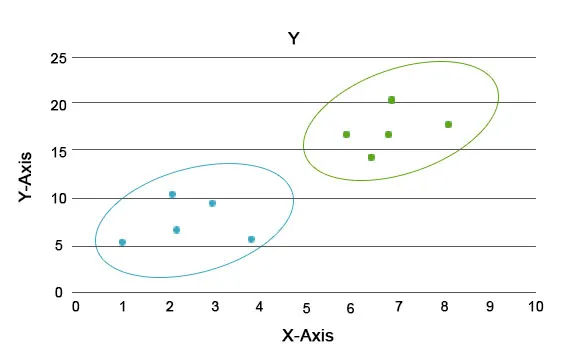
Ici, les couleurs bleues et oranges sont différentes grappes ayant en elles-mêmes des traits uniques.
- Analyse d'association
Cette analyse nous aide à établir des relations intéressantes entre les éléments d'un ensemble de données. Cette analyse découvre les relations cachées et aide à représenter les éléments d'ensemble de données sous la forme de règles d'association ou d'ensembles d'éléments fréquents. La règle d'association se décompose en 2 étapes:
- Génération fréquente d'éléments: Dans ce cas, un ensemble est généré dans lequel les éléments fréquents sont configurés ensemble.
- Génération de règles: l'ensemble construit ci-dessus passe à travers différentes couches de formation de règles pour établir une relation cachée entre elles. Par exemple, l'ensemble peut tomber dans des problèmes conceptuels ou d'implémentation ou dans des problèmes d'application. Ceux-ci sont ensuite ramifiés dans des arborescences respectives pour construire les règles d'association.
Par exemple, APRIORI est un algorithme de construction de règles d'association.
2. Apprentissage supervisé
- Analyse de régression
Dans l'analyse de régression, nous définissons la variable dépendante / cible et les variables restantes comme des variables indépendantes et finalement émettons l'hypothèse comment une ou plusieurs variables indépendantes influencent la variable cible. La régression avec une variable indépendante est appelée univariée et avec plus d'une est appelée multivariée. Entendons-nous en utilisant univariée puis l'échelle pour multivariée.
Par exemple, y est la variable cible et x 1 est la variable indépendante. Donc, à partir de la connaissance de la droite, nous pouvons écrire l'équation comme y = mx 1 + c. Ici, «m» détermine à quel point y est influencé par x 1 . Si «m» est très proche de zéro, cela signifie qu'avec un changement de x 1, y n'est pas fortement affecté. Avec un nombre supérieur à 1, l'impact devient plus fort et un petit changement de x 1 entraîne une grande variation de y. Semblable à univarié, en multivarié peut s'écrire y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Ici l'impact de chaque variable indépendante est déterminé par son «m» correspondant.
- Analyse de classification
Comme pour l'analyse de clustering, les algorithmes de classification sont construits avec la variable cible sous forme de classes. La différence entre le clustering et la classification réside dans le fait que dans le clustering, nous ne savons pas à quel groupe les points de données appartiennent, tandis que dans la classification, nous savons à quel groupe il appartient. Et il diffère de la régression du point de vue que le nombre de groupes doit être un nombre fixe contrairement à la régression, il est continu. Il existe un tas d'algorithmes dans l'analyse de classification, par exemple, les machines à vecteurs de support, la régression logistique, les arbres de décision, etc.
Conclusion
En conclusion, nous comprenons que chaque type d'analyse est vaste en soi, mais ici nous pouvons apporter une petite saveur à différentes techniques. Dans les prochaines notes, nous prendrions chacune d'elles séparément et entrerons dans les détails des différentes sous-techniques utilisées dans les techniques de chaque parent.
Article recommandé
Ceci est un guide des techniques de science des données. Nous discutons ici de l'introduction et des différents types de techniques en science des données. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Outils de science des données | Les 12 meilleurs outils
- Algorithmes de science des données avec types
- Introduction à la carrière en science des données
- Science des données vs visualisation des données
- Exemples de régression multivariée
- Créer un arbre de décision avec des avantages
- Bref aperçu du cycle de vie de la science des données