

Introduction à la technique d'apprentissage profond
La technique d'apprentissage en profondeur est basée sur des réseaux de neurones artificiels qui agissent comme un cerveau humain. Il imite la façon dont le cerveau humain pense et fonctionne. Dans ce modèle, le système apprend et effectue une classification à partir d'images, de texte ou de son. Les modèles d'apprentissage profond sont formés par de grandes données étiquetées et multicouches pour atteindre une précision élevée dans le résultat encore plus qu'au niveau humain. La voiture sans conducteur applique cette technologie pour identifier les panneaux d'arrêt, les piétons, etc. en locomotion. Les gadgets électroniques tels que les mobiles, les haut-parleurs, la télévision, les ordinateurs, etc. ont une fonction de commande vocale en raison du Deep Learning. Cette technique est nouvelle et efficace pour les consommateurs et les organisations.
Fonctionnement du Deep Learning
Les méthodes d'apprentissage en profondeur utilisent des réseaux de neurones. Ainsi, ils sont souvent appelés réseaux de neurones profonds. Les réseaux de neurones profonds ou cachés ont plusieurs couches cachées de réseaux profonds. Le Deep Learning forme l'IA à prédire la sortie à l'aide de certaines entrées ou couches réseau cachées. Ces réseaux sont formés par de grands ensembles de données étiquetés et apprennent les caractéristiques des données elles-mêmes. L'apprentissage supervisé et non supervisé fonctionne dans la formation des données et la génération de fonctionnalités.
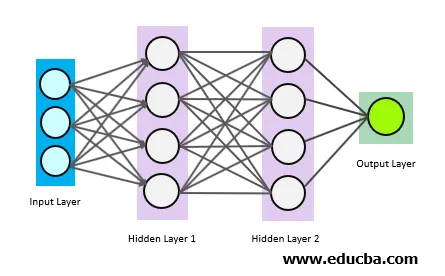
Les cercles ci-dessus sont des neurones interconnectés. Il existe 3 types de neurones:
- Couche d'entrée
- Couche (s) cachée (s)
- Couche de sortie
La couche d'entrée obtient les données d'entrée et transmet l'entrée à la première couche masquée. Les calculs mathématiques sont effectués sur les données d'entrée. Enfin, la couche de sortie donne les résultats.
CNN ou réseaux neuronaux conventionnels, l'un des réseaux neuronaux les plus populaires, convertit les fonctionnalités apprises des données d'entrée et utilise des couches convolutives 2D pour le rendre adapté au traitement de données 2D comme des images. Ainsi, CNN réduit l'utilisation de l'extraction manuelle des fonctionnalités dans ce cas. Il extrait directement les caractéristiques requises des images pour la classification. En raison de cette fonctionnalité d'automatisation, CNN est un algorithme principalement précis et fiable dans l'apprentissage automatique. Chaque CNN apprend les caractéristiques des images de la couche cachée et ces couches cachées augmentent la complexité des images apprises.
La partie importante est de former l'IA ou les réseaux de neurones. Pour ce faire, nous donnons une entrée à partir de l'ensemble de données et faisons finalement une comparaison des sorties à l'aide de la sortie de l'ensemble de données. Si l'IA n'est pas formée, la sortie peut être incorrecte.
Pour savoir à quel point la sortie de l'IA est incorrecte par rapport à la sortie réelle, nous avons besoin d'une fonction de calcul. La fonction est appelée fonction de coût. Si la fonction de coût est nulle, la sortie de l'IA et la sortie réelle sont identiques. Pour réduire la valeur de la fonction de coût, nous modifions les poids entre les neurones. Pour une approche pratique, une technique appelée descente de gradient peut être utilisée. GD réduit le poids des neurones au minimum après chaque itération. Ce processus se fait automatiquement.
Technique d'apprentissage profond
Les algorithmes de Deep Learning traversent plusieurs couches des couches cachées ou des réseaux de neurones. Ainsi, ils apprennent profondément sur les images pour une prédiction précise. Chaque calque apprend et détecte les entités de bas niveau comme les arêtes et par la suite, la nouvelle couche fusionne avec les entités de la couche précédente pour une meilleure représentation. Par exemple, un calque intermédiaire peut détecter n'importe quel bord de l'objet tandis que le calque caché détectera l'objet ou l'image complète.
Cette technique est efficace avec des données volumineuses et complexes. Si les données sont petites ou incomplètes, DL devient incapable de travailler avec de nouvelles données.
Il existe des réseaux d'apprentissage en profondeur comme suit:
- Réseau pré-formé non supervisé : C'est un modèle de base avec 3 couches: couche d'entrée, couche cachée et couche de sortie. Le réseau est formé pour reconstruire l'entrée, puis les couches cachées apprennent des entrées pour recueillir des informations et enfin, les caractéristiques sont extraites de l'image.
- Réseau neuronal conventionnel : En tant que réseau neuronal standard, il possède une convolution à l'intérieur pour la détection des bords et la reconnaissance précise des objets.
- Réseau neuronal récurrent : Dans cette technique, la sortie de l'étape précédente est utilisée comme entrée pour l'étape suivante ou actuelle. RNN stocke les informations dans des nœuds de contexte pour apprendre les données d'entrée et produire la sortie. Par exemple, pour terminer une phrase, nous avons besoin de mots. c'est-à-dire que pour prédire le mot suivant, il faut des mots précédents dont il faut se souvenir. RNN résout essentiellement ce type de problème.
- Réseaux de neurones récursifs : il s'agit d'un modèle hiérarchique où l'entrée est une structure arborescente. Ce type de réseau est créé en appliquant le même ensemble de poids sur l'assemblage des entrées.
Le Deep Learning a une variété d'applications dans les domaines financiers, la vision par ordinateur, la reconnaissance audio et vocale, l'analyse d'images médicales, les techniques de conception de médicaments, etc.
Comment créer des modèles d'apprentissage en profondeur?
Les algorithmes d'apprentissage profond sont créés en connectant des couches entre eux. La première étape ci-dessus est le calque d'entrée suivi du ou des calques masqués et du calque de sortie. Chaque couche est composée de neurones interconnectés. Le réseau consomme une grande quantité de données d'entrée pour les exploiter à travers plusieurs couches.
Pour créer un modèle Deep Learning, les étapes suivantes sont nécessaires:
- Comprendre le problème
- Identifier les données
- Sélectionnez l'algorithme
- Former le modèle
- Testez le modèle
L'apprentissage se déroule en deux phases
- Appliquez une transformation non linéaire des données d'entrée et créez un modèle statistique en sortie.
- Le modèle est amélioré avec une méthode dérivée.
Ces deux phases d'opérations sont appelées itération. Les réseaux de neurones répètent les deux étapes jusqu'à ce que la sortie et la précision souhaitées soient générées.
1. Formation des réseaux: Pour former un réseau de données, nous collectons un grand nombre de données et concevons un modèle qui apprendra les fonctionnalités. Mais le processus est plus lent en cas de très grand nombre de données.
2. Transfert d'apprentissage: Le transfert d'apprentissage modifie fondamentalement un modèle pré-formé et une nouvelle tâche est effectuée par la suite. Dans ce processus, le temps de calcul diminue.
3. Extraction d' entités : Une fois que toutes les couches ont été formées sur les entités de l'objet, les entités en sont extraites et la sortie est prédite avec précision.
Conclusion
Le Deep Learning est un sous-ensemble de ML et ML est un sous-ensemble d'IA. Les trois technologies et modèles ont un impact énorme sur la vie réelle. Entités commerciales, les géants commerciaux mettent en œuvre des modèles de Deep Learning pour des résultats supérieurs et comparables pour une automatisation inspirée du cerveau humain.
Articles recommandés
Ceci est un guide de Deep Learning Technique. Ici, nous discutons Comment créer des modèles d'apprentissage en profondeur avec les deux phases de fonctionnement. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Qu'est-ce que le Deep Learning
- Carrières en apprentissage profond
- 13 Questions et réponses utiles pour l'entretien approfondi
- Apprentissage automatique hyperparamètre