
Introduction à la régression de Poisson dans R
La régression de Poisson est un type de régression similaire à la régression linéaire multiple, sauf que la réponse ou la variable dépendante (Y) est une variable de comptage. La variable dépendante suit la distribution de Poisson. Le prédicteur ou les variables indépendantes peuvent être de nature continue ou catégorique. D'une certaine manière, il est similaire à la régression logistique qui a également une variable de réponse discrète. Une compréhension préalable de la distribution de Poisson et de sa forme mathématique est très essentielle pour en tirer parti pour la prédiction. Dans R, la régression de Poisson peut être implémentée de manière très efficace. R propose un ensemble complet de fonctionnalités pour sa mise en œuvre.
Implémentation de la régression de Poisson
Nous allons maintenant comprendre comment le modèle est appliqué. La section suivante donne une procédure étape par étape pour le même. Pour cette démonstration, nous considérons l'ensemble de données «gala» du package «lointain». Elle concerne la diversité des espèces des îles Galapagos. Il y a au total 7 variables dans l'ensemble de données. Nous utiliserons la régression de Poisson pour définir une relation entre le nombre d'espèces végétales (espèces) avec d'autres variables dans l'ensemble de données.
1. Chargez d'abord le package «lointain». Dans le cas où le package n'est pas présent, téléchargez-le en utilisant la fonction install.packages ().
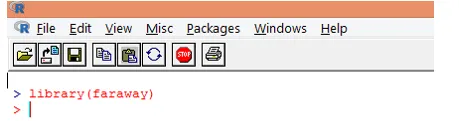
2. Une fois le package chargé, chargez le jeu de données «gala» dans R à l'aide de la fonction data () comme indiqué ci-dessous.
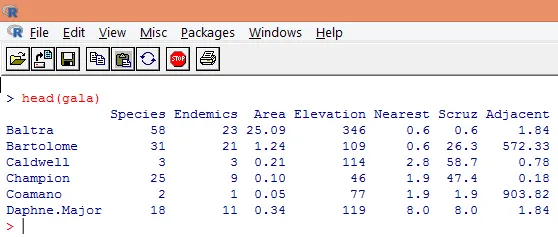
3. Les données chargées doivent être visualisées pour étudier la variable et vérifier s'il y a des écarts. Nous pouvons visualiser soit la totalité des données, soit uniquement les premières lignes à l'aide de la fonction head (), comme illustré dans la capture d'écran ci-dessous.
4. Pour obtenir plus d'informations sur l'ensemble de données, nous pouvons utiliser la fonctionnalité d'aide dans R comme ci-dessous. Il génère la documentation R comme indiqué dans la capture d'écran à la suite de la capture d'écran ci-dessous.


5. Si nous étudions l'ensemble de données comme mentionné dans les étapes précédentes, alors nous pouvons trouver que l'espèce est une variable de réponse. Nous allons maintenant étudier un résumé de base des variables prédictives.
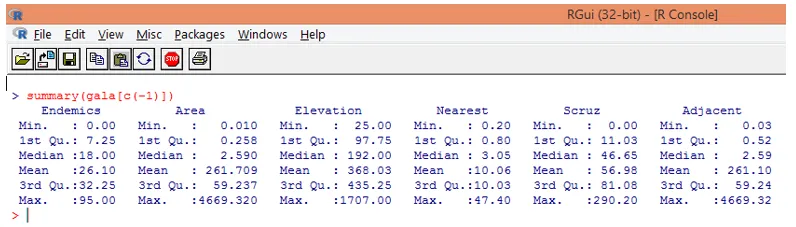
Notez, comme on peut le voir ci-dessus, nous avons exclu la variable Espèce. La fonction de résumé nous donne des informations de base. Observez simplement les valeurs médianes pour chacune de ces variables, et nous pouvons constater qu'une énorme différence, en termes de plage de valeurs, existe entre la première moitié et la seconde moitié, par exemple pour la valeur médiane variable de la zone est de 2, 59, mais le maximum la valeur est 4669, 320.
6. Maintenant que nous avons terminé l'analyse de base, nous allons générer un histogramme pour les espèces afin de vérifier si la variable suit la distribution de Poisson. Ceci est illustré ci-dessous.

Le code ci-dessus génère un histogramme pour la variable Espèce avec une courbe de densité superposée dessus.
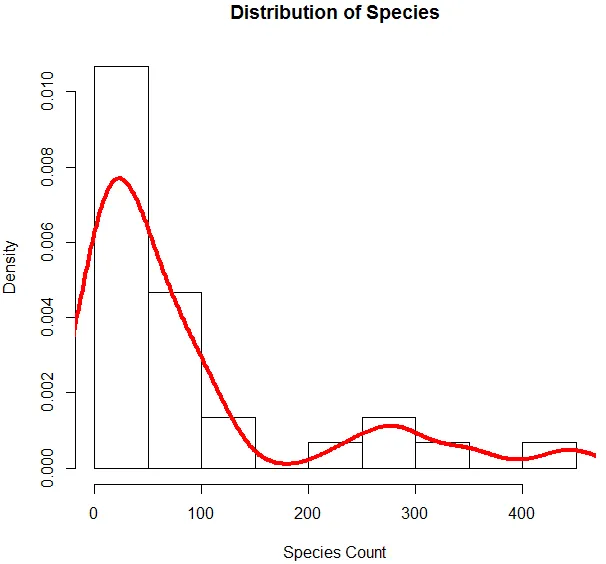
La visualisation ci-dessus montre que l'espèce suit une distribution de Poisson, car les données sont asymétriques à droite. Nous pouvons également générer un boxplot, pour obtenir plus d'informations sur le modèle de distribution, comme indiqué ci-dessous.
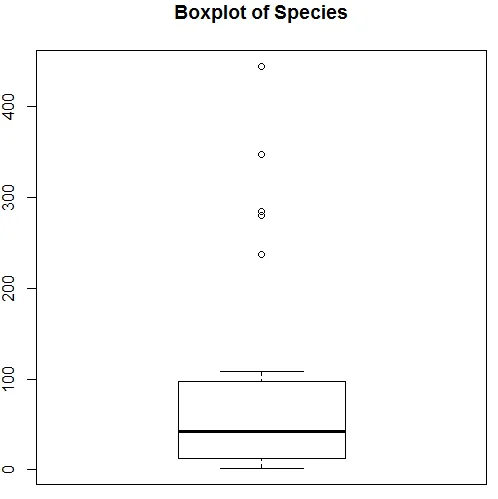
7. Après avoir fait l'analyse préliminaire, nous allons maintenant appliquer la régression de Poisson comme indiqué ci-dessous
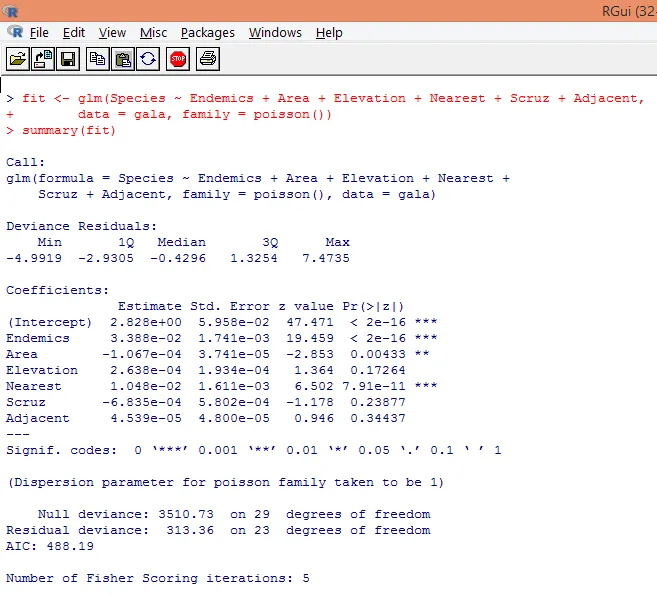
Sur la base de l'analyse ci-dessus, nous constatons que les variables Endemics, Area et Nearest sont significatives et seule leur inclusion est suffisante pour construire le bon modèle de régression de Poisson.
8. Nous allons construire un modèle de régression de Poisson modifié en prenant en considération seulement trois variables à savoir. Endémies, zone et plus proche. Voyons quels résultats nous obtenons.
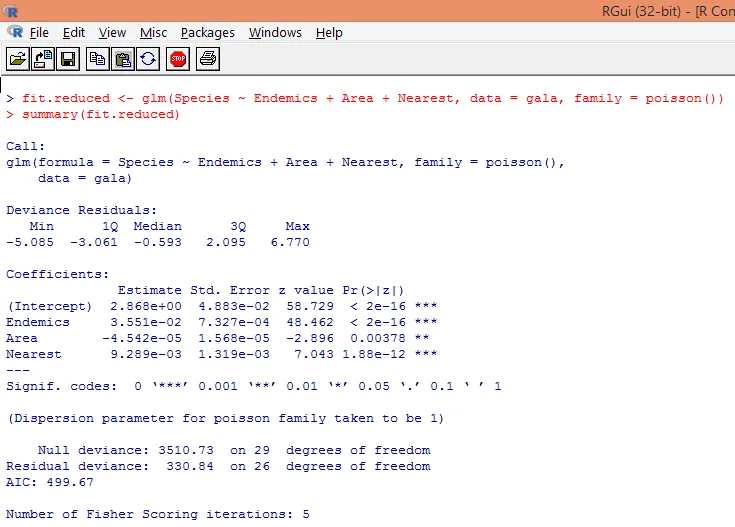
La sortie produit des écarts, des paramètres de régression et des erreurs standard. Nous pouvons voir que chacun des paramètres est significatif au niveau p <0, 05.
9. L'étape suivante consiste à interpréter les paramètres du modèle. Les coefficients du modèle peuvent être obtenus soit en examinant les coefficients dans la sortie ci-dessus, soit en utilisant la fonction coef ().
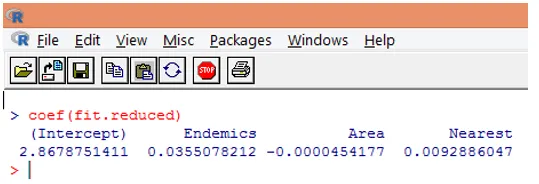
Dans la régression de Poisson, la variable dépendante est modélisée comme le log de la moyenne conditionnelle loge (l). Le paramètre de régression de 0, 0355 pour Endemics indique qu'une augmentation d'une unité de la variable est associée à une augmentation de 0, 04 du nombre moyen de log d'espèces, en maintenant les autres variables constantes. L'ordonnée à l'origine est un nombre moyen de log d'espèces lorsque chacun des prédicteurs est égal à zéro.
10. Cependant, il est beaucoup plus facile d'interpréter les coefficients de régression dans l'échelle d'origine de la variable dépendante (nombre d'espèces plutôt que nombre de logarithmes d'espèces). L'exponentiation des coefficients permettra une interprétation facile. Cela se fait comme suit.
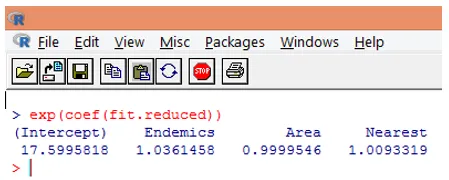
D'après les résultats ci-dessus, nous pouvons dire qu'une augmentation d'unité de la zone multiplie le nombre d'espèces attendu par 0, 9999, et une augmentation unitaire du nombre d'espèces endémiques représentées par Endemics multiplie le nombre d'espèces par 1, 0361. L'aspect le plus important de la régression de Poisson est que les paramètres exponentiels ont un effet multiplicatif plutôt qu'additif sur la variable de réponse.
11. En utilisant les étapes ci-dessus, nous avons obtenu un modèle de régression de Poisson pour prédire le nombre d'espèces végétales sur les îles Galapagos. Cependant, il est très important de vérifier la surdispersion. Dans la régression de Poisson, la variance et les moyennes sont égales.
Une surdispersion se produit lorsque la variance observée de la variable de réponse est plus grande que ce qui serait prévu par la distribution de Poisson. L'analyse de la surdispersion devient importante car elle est courante avec les données de comptage et peut avoir un impact négatif sur les résultats finaux. Dans R, la surdispersion peut être analysée à l'aide du package «qcc». L'analyse est illustrée ci-dessous.
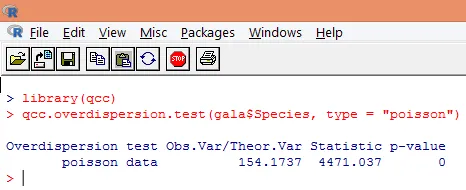
Le test significatif ci-dessus montre que la valeur de p est inférieure à 0, 05, ce qui suggère fortement la présence d'une surdispersion. Nous allons essayer d'ajuster un modèle en utilisant la fonction glm (), en remplaçant family = "Poisson" par family = "quasipoisson". Ceci est illustré ci-dessous.
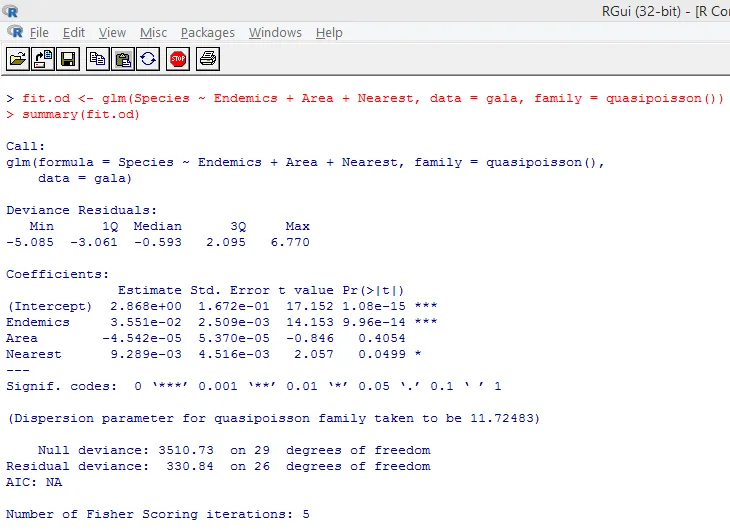
En étudiant de près la sortie ci-dessus, nous pouvons voir que les estimations des paramètres dans l'approche quasi-Poisson sont identiques à celles produites par l'approche Poisson, bien que les erreurs standard soient différentes pour les deux approches. De plus, dans ce cas, pour Area, la valeur de p est supérieure à 0, 05, ce qui est dû à une erreur standard plus importante.
Importance de la régression de Poisson
- La régression de Poisson dans R est utile pour des prédictions correctes de la variable discrète / comptée.
- Il nous aide à identifier les variables explicatives qui ont un effet statistiquement significatif sur la variable de réponse.
- La régression de Poisson dans R convient mieux aux événements de nature «rare» car ils ont tendance à suivre une distribution de Poisson par rapport aux événements courants qui suivent généralement une distribution normale.
- Il convient à l'application dans les cas où la variable de réponse est un petit entier.
- Il a de nombreuses applications, car la prédiction de variables discrètes est cruciale dans de nombreuses situations. En médecine, il peut être utilisé pour prédire l'impact du médicament sur la santé. Il est largement utilisé dans l'analyse de survie comme la mort d'organismes biologiques, la défaillance de systèmes mécaniques, etc.
Conclusion
La régression de Poisson est basée sur le concept de distribution de Poisson. Il s'agit d'une autre catégorie appartenant à l'ensemble des techniques de régression qui combine les propriétés des régressions linéaires et logistiques. Cependant, contrairement à la régression logistique qui génère uniquement une sortie binaire, elle est utilisée pour prédire une variable discrète.
Articles recommandés
Ceci est un guide de régression de Poisson dans R. Ici, nous discutons de l'introduction de la régression de Poisson et de l'importance de la régression de Poisson. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus–
- GLM dans R
- Générateur de nombres aléatoires en R
- Formule de régression
- Régression logistique en R
- Régression linéaire vs régression logistique | Principales différences