
Qu'est-ce que l'algorithme SVM?
SVM signifie Support Vector Machine. SVM est un algorithme d'apprentissage automatique supervisé qui est couramment utilisé pour les défis de classification et de régression. Les applications courantes de l'algorithme SVM sont le système de détection d'intrusion, la reconnaissance de l'écriture manuscrite, la prédiction de la structure des protéines, la détection de la stéganographie dans les images numériques, etc.
Dans l'algorithme SVM, chaque point est représenté comme un élément de données dans l'espace à n dimensions où la valeur de chaque entité est la valeur d'une coordonnée spécifique.
Après le traçage, la classification a été effectuée en trouvant un plan de battage qui différencie deux classes. Référez-vous à l'image ci-dessous pour comprendre ce concept.
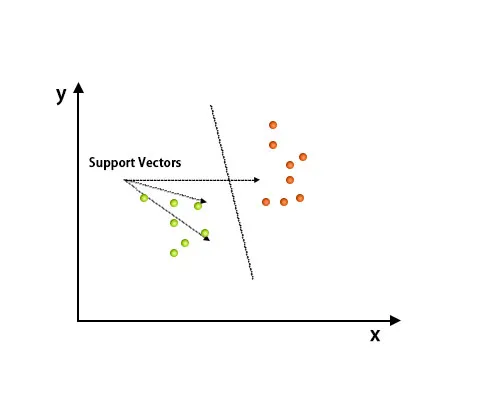
L'algorithme Support Vector Machine est principalement utilisé pour résoudre les problèmes de classification. Les vecteurs de support ne sont que les coordonnées de chaque élément de données. Support Vector Machine est une frontière qui différencie deux classes en utilisant l'hyperplan.
Comment fonctionne l'algorithme SVM?
Dans la section ci-dessus, nous avons discuté de la différenciation de deux classes en utilisant l'hyperplan. Maintenant, nous allons voir comment fonctionne réellement cet algorithme SVM.
Scénario 1: identifier l'hyperplan de droite
Ici, nous avons pris trois hyper-plans, c'est-à-dire A, B et C. Maintenant, nous devons identifier le bon hyper-plan pour classer l'étoile et le cercle.
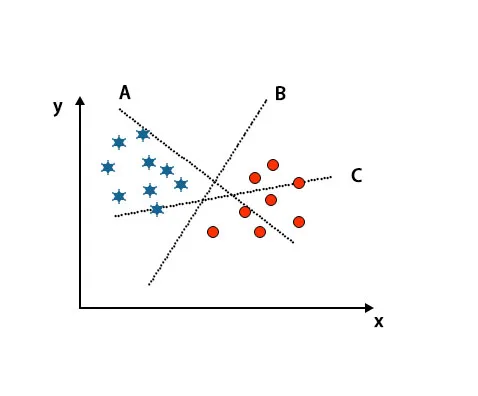
Pour identifier l'hyperplan droit, nous devons connaître la règle du pouce. Sélectionnez l'hyperplan qui différencie deux classes. Dans l'image mentionnée ci-dessus, l'hyperplan B différencie très bien deux classes.
Scénario 2: identifier l'hyperplan de droite
Ici, nous avons pris trois hyper-plans, c'est-à-dire A, B et C. Ces trois hyper-plans différencient déjà très bien les classes.
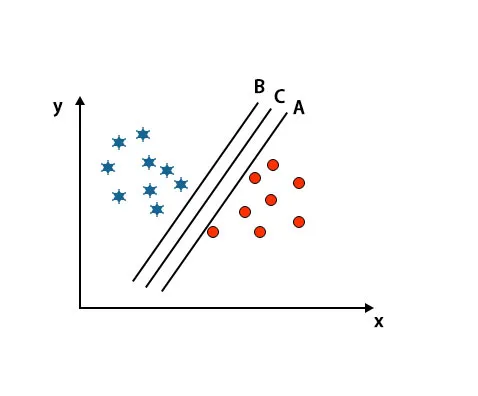
Dans ce scénario, pour identifier l'hyper-plan droit, nous augmentons la distance entre les points de données les plus proches. Cette distance n'est qu'une marge. Reportez-vous à l'image ci-dessous.
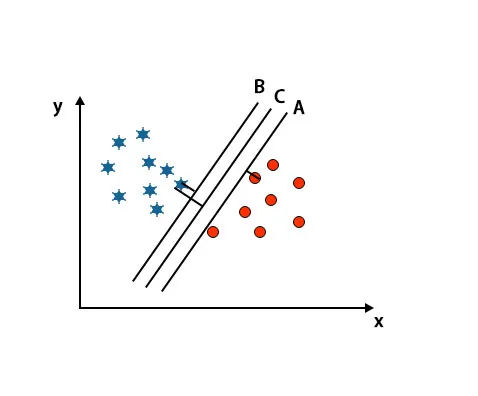
Dans l'image mentionnée ci-dessus, la marge de l'hyperplan C est plus élevée que l'hyperplan A et l'hyperplan B. Donc, dans ce scénario, C est l'hyperplan droit. Si nous choisissons l'hyperplan avec une marge minimale, cela peut conduire à une mauvaise classification. Nous avons donc choisi l'hyperplan C avec une marge maximale en raison de la robustesse.
Scénario 3: identifier l'hyperplan de droite
Remarque: pour identifier l'hyperplan, suivez les mêmes règles que celles mentionnées dans les sections précédentes.
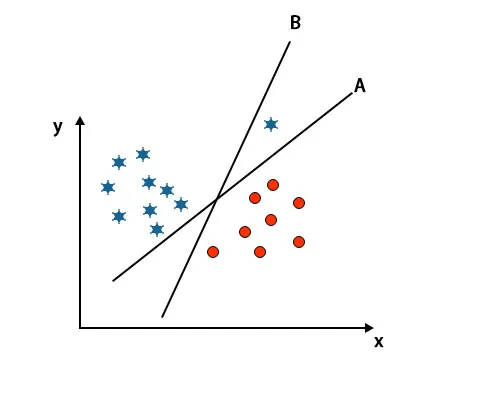
Comme vous pouvez le voir sur l'image mentionnée ci-dessus, la marge de l'hyperplan B est plus élevée que la marge de l'hyperplan A, c'est pourquoi certains sélectionneront l'hyperplan B comme droite. Mais dans l'algorithme SVM, il sélectionne cet hyperplan qui classe les classes précises avant de maximiser la marge. Dans ce scénario, l'hyper-plan A a tout classé avec précision et il y a une erreur avec la classification de l'hyper-plan B. Par conséquent, A est l'hyper-avion droit.
Scénario 4: classer deux classes
Comme vous pouvez le voir dans l'image ci-dessous, nous ne sommes pas en mesure de différencier deux classes en utilisant une ligne droite car une étoile se trouve comme une valeur aberrante dans l'autre classe de cercle.
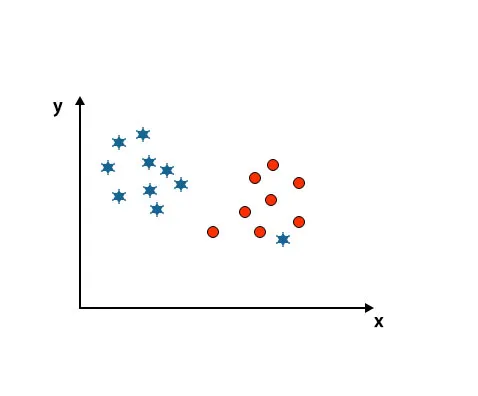
Ici, une étoile est dans une autre classe. Pour la classe d'étoile, cette étoile est la valeur aberrante. En raison de la propriété de robustesse de l'algorithme SVM, il trouvera l'hyperplan droit avec une marge plus élevée ignorant une valeur aberrante.
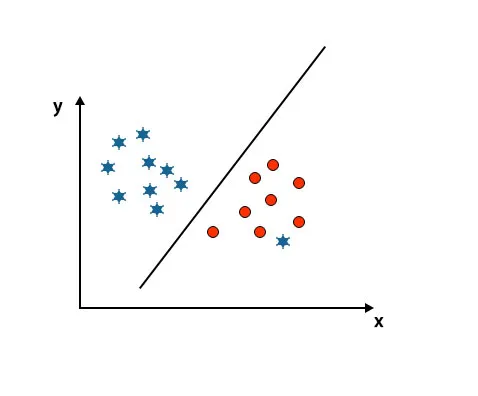
Scénario 5: Hyper-plan fin pour différencier les classes
Jusqu'à présent, nous avons regardé l'hyperplan linéaire. Dans l'image ci-dessous, nous n'avons pas d'hyperplan linéaire entre les classes.
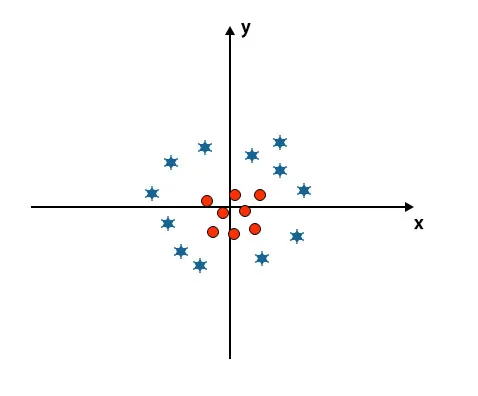
Pour classer ces classes, SVM introduit quelques fonctionnalités supplémentaires. Dans ce scénario, nous allons utiliser cette nouvelle fonctionnalité z = x 2 + y 2.
Trace tous les points de données sur les axes x et z.

Remarque
- Toutes les valeurs sur l'axe z doivent être positives car z est égal à la somme de x au carré et de y au carré.
- Dans le graphique mentionné ci-dessus, les cercles rouges sont fermés à l'origine de l'axe des x et de l'axe des y, menant la valeur de z vers le bas et l'étoile est exactement l'opposé du cercle, elle est éloignée de l'origine de l'axe des x et l'axe des y, menant la valeur de z à haut.
Dans l'algorithme SVM, il est facile de classer en utilisant un hyperplan linéaire entre deux classes. Mais la question se pose ici est de savoir si nous devons ajouter cette fonctionnalité de SVM pour identifier l'hyperplan. Donc, la réponse est non, pour résoudre ce problème, SVM a une technique communément appelée astuce du noyau.
L'astuce du noyau est la fonction qui transforme les données sous une forme appropriée. Il existe différents types de fonctions de noyau utilisées dans l'algorithme SVM, c'est-à-dire polynomiales, linéaires, non linéaires, fonction de base radiale, etc.
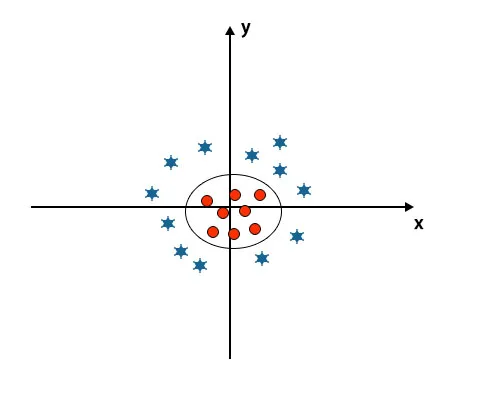
Lorsque nous regardons l'hyperplan l'origine de l'axe et de l'axe y, il ressemble à un cercle. Reportez-vous à l'image ci-dessous.
Avantages de l'algorithme SVM
- Même si les données d'entrée sont non linéaires et non séparables, les SVM génèrent des résultats de classification précis en raison de leur robustesse.
- Dans la fonction de décision, il utilise un sous-ensemble de points d'apprentissage appelés vecteurs de support, il est donc efficace en mémoire.
- Il est utile de résoudre tout problème complexe avec une fonction de noyau appropriée.
- En pratique, les modèles SVM sont généralisés, avec moins de risque de sur-ajustement dans SVM.
- Les SVM fonctionnent très bien pour la classification de texte et pour trouver le meilleur séparateur linéaire.
Inconvénients de l'algorithme SVM
- Il faut un long temps de formation lorsque vous travaillez avec de grands ensembles de données.
- Il est difficile de comprendre le modèle final et l'impact individuel.
Conclusion
Il a été guidé pour prendre en charge l'algorithme de machine vectorielle qui est un algorithme d'apprentissage automatique. Dans cet article, nous avons discuté en détail de l'algorithme SVM, de son fonctionnement et de ses avantages.
Articles recommandés
Cela a été un guide pour l'algorithme SVM. Nous discutons ici de son fonctionnement avec un scénario, les avantages et les inconvénients de l'algorithme SVM. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Algorithmes d'exploration de données
- Techniques d'exploration de données
- Qu'est-ce que l'apprentissage automatique?
- Outils d'apprentissage machine
- Exemples d'algorithme C ++