
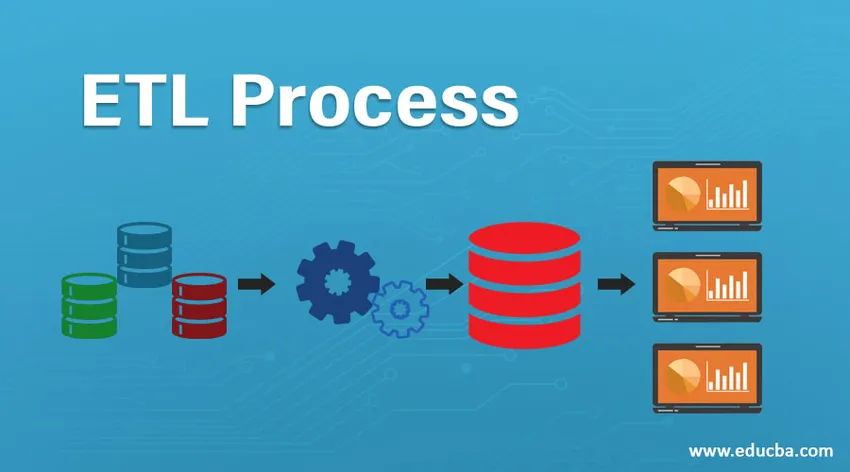
Introduction du processus ETL
ETL est l'un des processus importants requis par la Business Intelligence. La Business Intelligence s'appuie sur les données stockées dans des entrepôts de données à partir desquels de nombreuses analyses et rapports sont générés, ce qui aide à élaborer des stratégies plus efficaces et conduit à des informations tactiques et opérationnelles et à la prise de décision.
ETL fait référence au processus d'extraction, de transformation et de chargement. Il s'agit d'une sorte d'étape d'intégration de données où les données provenant de différentes sources sont extraites et envoyées aux entrepôts de données. Les données sont extraites de diverses ressources d'abord transformées pour les convertir dans un format spécifique en fonction des besoins de l'entreprise. Divers outils qui aident à effectuer ces tâches sont -
- IBM DataStage
- Abinitio
- Informatica
- Tableau
- Talend
Processus ETL
Comment ça marche?
Le processus ETL est un processus en 3 étapes qui commence par l'extraction des données de diverses sources de données, puis les données brutes subissent diverses transformations pour le rendre approprié pour le stockage dans l'entrepôt de données et le charger dans des entrepôts de données au format requis et le préparer pour une analyse.
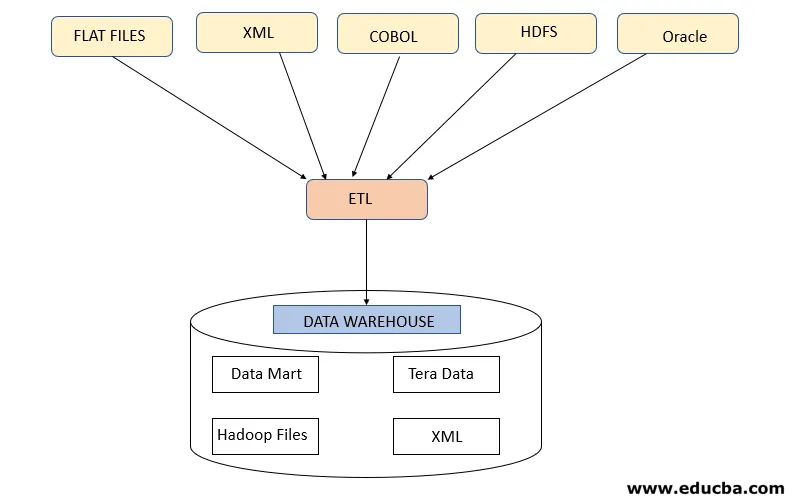
Étape 1: extraire
Cette étape consiste à récupérer les données requises à partir de diverses sources présentes dans différents formats tels que XML, fichiers Hadoop, fichiers plats, JSON, etc. Les données extraites sont stockées dans la zone de transfert où d'autres transformations sont effectuées. Ainsi, les données sont soigneusement vérifiées avant de les déplacer vers des entrepôts de données, sinon il deviendra difficile de revenir sur les modifications des entrepôts de données.
Une carte de données appropriée est requise entre la source et la cible avant que l'extraction des données ne se produise car le processus ETL doit interagir avec divers systèmes tels qu'Oracle, Hardware, Mainframe, des systèmes en temps réel tels que ATM, Hadoop, etc. tout en récupérant les données de ces systèmes .
Remarque - Mais il faut veiller à ce que ces systèmes ne doivent pas être affectés lors de l'extraction.
Stratégies d'extraction de données
- Extraction complète: ceci est suivi lorsque des données entières provenant de sources sont chargées dans les entrepôts de données qui montrent que l'entrepôt de données est rempli la première fois ou qu'aucune stratégie n'a été élaborée pour l'extraction des données.
- Extraction partielle (avec notification de mise à jour): cette stratégie est également connue sous le nom de delta, où seules les données en cours de modification sont extraites et mettent à jour les entrepôts de données
- Extraction partielle (sans notification de mise à jour): cette stratégie fait référence à l'extraction de données spécifiques requises à partir de sources en fonction de la charge dans les entrepôts de données au lieu d'extraire des données entières.
Étape 2: transformer
Cette étape est l'étape la plus importante d'ETL. Dans cette étape, de nombreuses transformations sont effectuées pour préparer les données au chargement dans les entrepôts de données en appliquant les transformations ci-dessous: -
A. Transformations de base: ces transformations sont appliquées dans tous les scénarios, car elles sont indispensables lors du chargement des données extraites de diverses sources, dans les entrepôts de données
- Nettoyage ou enrichissement des données: il s'agit de nettoyer les données indésirables de la zone de transfert afin que les données incorrectes ne soient pas chargées à partir des entrepôts de données.
- Filtrage: Ici, nous filtrons les données requises sur une grande quantité de données présentes selon les besoins de l'entreprise. Par exemple, pour générer des rapports de vente, il suffit d'avoir des enregistrements de ventes pour cette année spécifique.
- Consolidation: Les données extraites sont consolidées dans le format requis avant de les charger dans les entrepôts de données.
- Normalisations: les champs de données sont transformés pour les mettre dans le même format requis, par exemple, le champ de données doit être spécifié comme MM / JJ / AAAA.
B. Transformations avancées: ces types de transformations sont spécifiques aux besoins de l'entreprise.
- Jointure: dans cette opération, les données de 2 sources ou plus sont combinées pour générer des données avec uniquement les colonnes souhaitées avec des lignes liées les unes aux autres
- Contrôle de validation du seuil de données: Les valeurs présentes dans les différents champs sont vérifiées si elles sont correctes ou non telles que le numéro de compte bancaire non nul en cas de données bancaires.
- Utiliser des recherches pour fusionner des données: divers fichiers plats ou autres fichiers sont utilisés pour extraire les informations spécifiques en effectuant une opération de recherche à ce sujet.
- Utilisation de toute validation de données complexes: de nombreuses validations complexes sont appliquées pour extraire des données valides uniquement à partir des systèmes source.
- Valeurs calculées et dérivées: divers calculs sont appliqués pour transformer les données en certaines informations requises
- Duplication: les données en double provenant des systèmes source sont analysées et supprimées avant de les charger dans les entrepôts de données.
- Restructuration des clés: dans le cas de la capture de données à évolution lente, différentes clés de substitution doivent être générées pour structurer les données dans le format requis.
Remarque - Le traitement parallèle massif MPP est parfois utilisé pour effectuer certaines opérations de base telles que le filtrage ou le nettoyage des données dans la zone de transfert afin de traiter plus rapidement une grande quantité de données.
Étape 3: charger
Cette étape fait référence au chargement des données transformées dans l'entrepôt de données d'où elles peuvent être utilisées pour générer de nombreuses décisions analytiques ainsi que des rapports.
1. Chargement initial: ce type de chargement se produit lors du premier chargement des données dans des entrepôts de données.
2. Charge incrémentielle: c'est le type de charge qui est effectué pour mettre à jour l'entrepôt de données sur une base périodique avec des changements se produisant dans les données du système source.
3. Rafraîchissement complet: ce type de chargement fait référence à la situation où les données complètes de la table sont supprimées et chargées avec de nouvelles données.
L'entrepôt de données autorise alors les fonctionnalités OLAP ou OLTP.
Inconvénients du processus ETL
- Augmentation des données - Il existe une limite de données extraites de diverses sources par l'outil ETL et transmises aux entrepôts de données. Ainsi, avec l'augmentation des données, le travail avec l'outil ETL et les entrepôts de données deviennent encombrants.
- Personnalisation - Il s'agit des solutions ou des réponses rapides et efficaces aux données générées par les systèmes sources. Mais l'utilisation de l'outil ETL ici ralentit ce processus.
- Cher - L'utilisation d'un entrepôt de données pour stocker une quantité croissante de données générées périodiquement est un coût élevé qu'une organisation doit payer.
Conclusion - Processus ETL
L'outil ETL comprend des processus d'extraction, de transformation et de chargement où il aide à générer des informations à partir des données recueillies à partir de divers systèmes sources. Les données du système source peuvent venir dans tous les formats et peuvent être chargées dans n'importe quel format souhaité dans les entrepôts de données, l'outil ETL doit donc prendre en charge la connectivité à tous les types de ces formats.
Articles recommandés
Ceci est un guide pour un processus ETL. Nous discutons ici de l'introduction, Comment ça marche?, ETL Tools et ses inconvénients. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus–
- Outils Informatica ETL
- Outils de test ETL
- Qu'est-ce que l'ETL?
- Qu'est-ce que le test ETL?