
Introduction à l'apprentissage supervisé
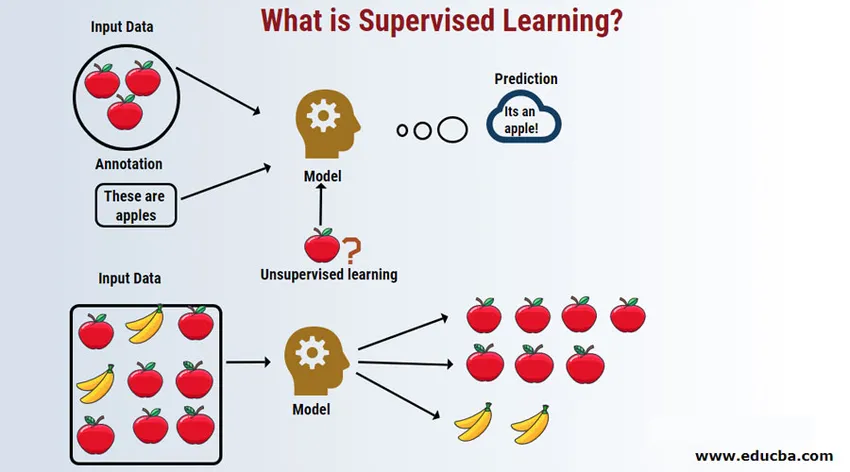
L'apprentissage supervisé est un domaine d'apprentissage automatique où nous travaillons sur la prévision des valeurs à l'aide d'ensembles de données étiquetés. Les ensembles de données d'entrée étiquetés sont appelés la variable indépendante tandis que les résultats prévus sont appelés la variable dépendante car ils dépendent de la variable indépendante pour leurs résultats. Par exemple, nous avons tous un dossier de spam dans notre compte de messagerie (par exemple Gmail) qui détecte automatiquement la plupart des courriers indésirables / fraude pour vous avec une précision supérieure à 95%. Il fonctionne sur la base d'un modèle d'apprentissage supervisé où nous avons un ensemble de formation de données étiquetées, qui dans ce cas est étiqueté comme courrier indésirable signalé par les utilisateurs. Ces ensembles de formation sont utilisés pour l'apprentissage qui sera utilisé ultérieurement pour la catégorisation des nouveaux e-mails en tant que spam s'ils correspondent à la catégorie.
Travailler sur l'apprentissage automatique supervisé
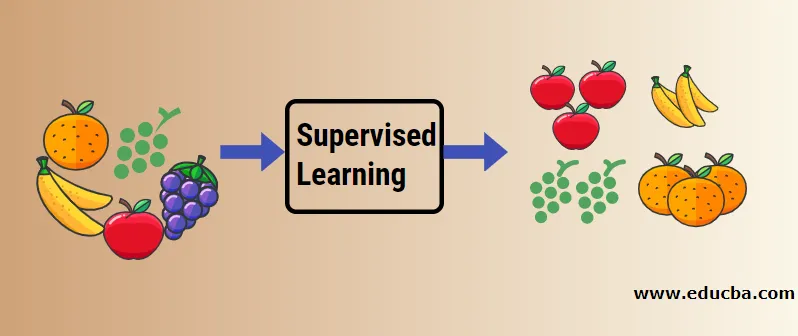
Comprenons l'apprentissage automatique supervisé à l'aide d'un exemple. Disons que nous avons une corbeille de fruits remplie de différentes espèces de fruits. Notre travail consiste à classer les fruits en fonction de leur catégorie.
Dans notre cas, nous avons considéré quatre types de fruits et ce sont les pommes, les bananes, les raisins et les oranges.
Maintenant, nous allons essayer de mentionner certaines des caractéristiques uniques de ces fruits qui les rendent uniques.
|
Non. | Taille | Couleur | Forme |
Prénom |
|
1 | Petit | vert | Rond à ovale, Bouquet cylindrique |
Grain de raisin |
|
2 | Gros | rouge | Forme arrondie avec une dépression en haut |
Pomme |
|
3 | Gros | Jaune | Cylindre courbé long |
banane |
| 4 | Gros | Orange | Forme arrondie |
Orange |
Maintenant, disons que vous avez ramassé un fruit de la corbeille de fruits, vous avez examiné ses caractéristiques, par exemple sa forme, sa taille et sa couleur par exemple, puis vous en déduisez que la couleur de ce fruit est rouge, la taille si grande, la forme est arrondie avec une dépression en haut, c'est donc une pomme.
- De même, vous faites de même pour tous les autres fruits restants.
- La colonne la plus à droite («Nom du fruit») est connue comme la variable de réponse.
- C'est ainsi que nous formulons un modèle d'apprentissage supervisé, maintenant il sera assez facile pour toute personne nouvelle (disons un robot ou un extraterrestre) avec des propriétés données de regrouper facilement le même type de fruits ensemble.
Types d'algorithme d'apprentissage automatique supervisé
Voyons différents types d'algorithmes d'apprentissage automatique:
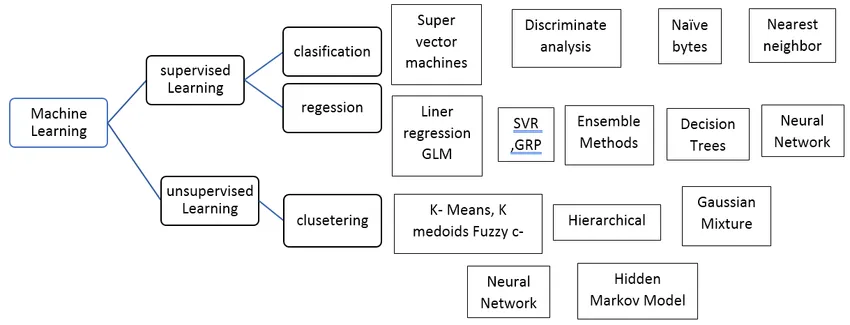
Régression:
La régression est utilisée pour prédire la sortie d'une valeur unique à l'aide de l'ensemble de données d'apprentissage. La valeur de sortie est toujours appelée comme variable dépendante tandis que les entrées sont appelées variable indépendante. Nous avons différents types de régression dans l'apprentissage supervisé, par exemple,
- Régression linéaire - Ici, nous n'avons qu'une seule variable indépendante qui est utilisée pour prédire la sortie, c'est-à-dire la variable dépendante.
- Régression multiple - Ici, nous avons plus d'une variable indépendante qui est utilisée pour prédire la sortie, c'est-à-dire la variable dépendante.
- Régression polynomiale - Ici, le graphique entre les variables dépendantes et indépendantes suit une fonction polynomiale. Par exemple, au début, la mémoire augmente avec l'âge, puis elle atteint un seuil à un certain âge, puis elle commence à diminuer à mesure que nous vieillissons.
Classification:
La classification des algorithmes d'apprentissage supervisé est utilisée pour regrouper des objets similaires en classes uniques.
- Classification binaire - Si l'algorithme essaie de regrouper 2 groupes distincts de classes, alors il est appelé classification binaire.
- Classification multiclasse - Si l'algorithme essaie de regrouper des objets en plus de 2 groupes, il est alors appelé classification multiclasse.
- Force - Les algorithmes de classification fonctionnent généralement très bien.
- Inconvénients - Sujette au sur-ajustement et peut être sans contrainte. Par exemple - Classificateur de courrier électronique indésirable
- Régression / classification logistique - Lorsque la variable Y est une catégorie binaire (c.-à-d. 0 ou 1), nous utilisons la régression logistique pour la prédiction. Par exemple - Prédire si une transaction par carte de crédit donnée est une fraude ou non.
- Naïve Bayes Classifiers - Le Naïve Bayes Classifier est basé sur le théorème bayésien. Cet algorithme est généralement mieux adapté lorsque la dimensionnalité des entrées est élevée. Il se compose de graphiques acycliques qui ont un nœud parent et plusieurs nœuds enfants. Les nœuds enfants sont indépendants les uns des autres.
- Arbres de décision - Un arbre de décision est une structure arborescente qui se compose d'un nœud interne (test sur attribut), branche qui dénote le résultat du test et les nœuds feuilles qui représentent la distribution des classes. Le nœud racine est le nœud le plus haut. Il s'agit d'une technique très largement utilisée qui est utilisée pour la classification.
- Machine à vecteur de support - Une machine à vecteur de support est ou un SVM fait le travail de classification en trouvant l'hyperplan qui devrait maximiser la marge entre 2 classes. Ces machines SVM sont connectées aux fonctions du noyau. Les domaines, où les SVM sont largement utilisés, sont la biométrie, la reconnaissance de formes, etc.
Les avantages
Voici certains des avantages des modèles d'apprentissage automatique supervisé:
- Les performances des modèles peuvent être optimisées par l'expérience utilisateur.
- L'apprentissage supervisé produit des résultats en utilisant l'expérience précédente et vous permet également de collecter des données.
- Les algorithmes d'apprentissage automatique supervisé peuvent être utilisés pour mettre en œuvre un certain nombre de problèmes du monde réel.
Désavantages
Les inconvénients de l'apprentissage supervisé sont les suivants:
- L'effort de formation des modèles d'apprentissage automatique supervisé peut prendre beaucoup de temps si l'ensemble de données est plus volumineux.
- La classification des mégadonnées pose parfois un défi plus important.
- Il faudra peut-être faire face aux problèmes de sur-ajustement.
- Nous avons besoin de nombreux bons exemples si nous voulons que le modèle fonctionne bien pendant que nous formons le classificateur.
Bonnes pratiques lors de la construction de modèles d'apprentissage
C'est une bonne pratique lors de la construction d'un modèle de machine d'apprentissage supervisé: -
- Avant de construire un bon modèle d'apprentissage automatique, le processus de prétraitement des données doit être effectué.
- Il faut décider de l'algorithme qui convient le mieux à un problème donné.
- Nous devons décider quel type de données sera utilisé pour l'ensemble de formation.
- Doit décider de la structure de l'algorithme et de la fonction.
Conclusion
Dans notre article, nous avons appris ce qu'est l'apprentissage supervisé et nous avons vu qu'ici nous formons le modèle à l'aide de données étiquetées. Nous sommes ensuite entrés dans le travail des modèles et de leurs différents types. Nous avons enfin vu les avantages et les inconvénients de ces algorithmes d'apprentissage automatique supervisé.
Articles recommandés
Ceci est un guide sur ce qu'est l'apprentissage supervisé?. Nous discutons ici des concepts, de son fonctionnement, des types, des avantages et des inconvénients de l'apprentissage supervisé. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Qu'est-ce que le Deep Learning
- Apprentissage supervisé vs apprentissage en profondeur
- Qu'est-ce que la synchronisation en Java?
- Qu'est-ce que l'hébergement Web?
- Façons de créer un arbre de décision avec des avantages
- Régression polynomiale | Utilisations et fonctionnalités