
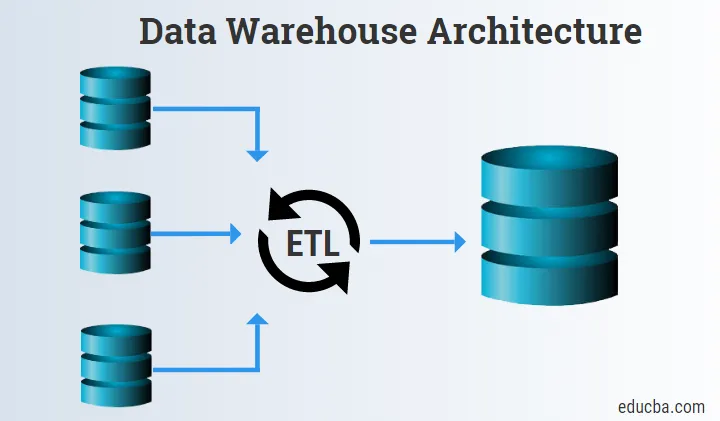
Introduction à l'architecture d'entrepôt de données
- Un entrepôt de données est un lieu de stockage contenant des collections de différents types de données acquises à partir de plusieurs types de sources.
- L'ensemble du processus, où des sources externes de données sont acquises, traitées, stockées et analysées en informations utilisables, se déroule au sein d'un ensemble de systèmes qui sont unifiés par un schéma unique appelé Data Warehouse Architecture.
Architecture d'entrepôt de données

L'architecture de l'entrepôt de données comprend généralement trois niveaux.
- Haut niveau
- Niveau intermédiaire
- Niveau inférieur
Haut niveau
- Le niveau supérieur se compose de l'extrémité avant côté client de l'architecture.
- Les informations transformées et appliquées logiques stockées dans l'entrepôt de données seront utilisées et acquises à des fins commerciales dans ce niveau.
- Plusieurs outils de génération et d'analyse de rapports sont présents pour la génération des informations souhaitées.
- L'exploration de données qui est devenue une grande tendance ces jours-ci se fait ici.
- Tous les documents d'analyse des exigences, les coûts et toutes les fonctionnalités qui déterminent une transaction commerciale basée sur les bénéfices sont basés sur ces outils qui utilisent les informations de l'entrepôt de données.
Niveau intermédiaire
- Le niveau intermédiaire se compose des serveurs OLAP
- OLAP est un serveur de traitement analytique en ligne
- OLAP est utilisé pour fournir des informations aux analystes commerciaux et aux gestionnaires
- Comme il est situé dans le niveau intermédiaire, il interagit à juste titre avec les informations présentes dans le niveau inférieur et transmet les informations aux outils de niveau supérieur qui traitent les informations disponibles.
- La plupart du temps OLAP relationnel ou multidimensionnel est utilisé dans l'architecture d'entrepôt de données.
Niveau inférieur
Le niveau inférieur se compose principalement des sources de données, de l'outil ETL et de l'entrepôt de données.
1. Sources de données
Les sources de données se composent des données sources qui sont acquises et fournies aux outils de transfert et ETL pour un processus ultérieur.
2. Outils ETL
- Les outils ETL sont très importants car ils aident à combiner la logique, les données brutes et le schéma en un seul et chargent les informations dans l'entrepôt de données ou les magasins de données.
- Parfois, ETL charge les données dans les Data Marts, puis les informations sont stockées dans Data Warehouse. Cette approche est connue sous le nom d'approche ascendante.
- L'approche par laquelle ETL charge directement les informations dans l'entrepôt de données est connue sous le nom d'approche descendante.
Différence entre l'approche descendante et l'approche ascendante
| Approche descendante | Une approche en profondeur |
| Fournit une vue précise et cohérente des informations car les informations de l'entrepôt de données sont utilisées pour créer des Data Marts | Les rapports peuvent être générés facilement car les Data Marts sont créés en premier et il est relativement facile d'interagir avec les Data Marts. |
| Modèle solide et donc préféré par les grandes entreprises | Pas aussi solide mais l'entrepôt de données peut être étendu et le nombre de magasins de données peut être créé |
| Le temps, le coût et la maintenance sont élevés | Le temps, le coût et la maintenance sont faibles. |
Datamarts
- Data Mart est également un composant de stockage utilisé pour stocker des données d'une fonction spécifique ou d'une partie liée à une entreprise par une autorité individuelle.
- Data mart rassemble les informations de Data Warehouse et nous pouvons donc dire que data mart stocke le sous-ensemble d'informations dans Data Warehouse.
- Les Data Marts sont flexibles et de petite taille.
3. Entrepôt de données
- Data Warehouse est le composant central de toute l'architecture Data Warehouse.
- Il agit comme un référentiel pour stocker des informations.
- De grandes quantités de données sont stockées dans l'entrepôt de données.
- Ces informations sont utilisées par plusieurs technologies comme le Big Data qui nécessitent d'analyser de grands sous-ensembles d'informations.
- Data Mart est également un modèle de Data Warehouse.
Différentes couches d'architecture d'entrepôt de données
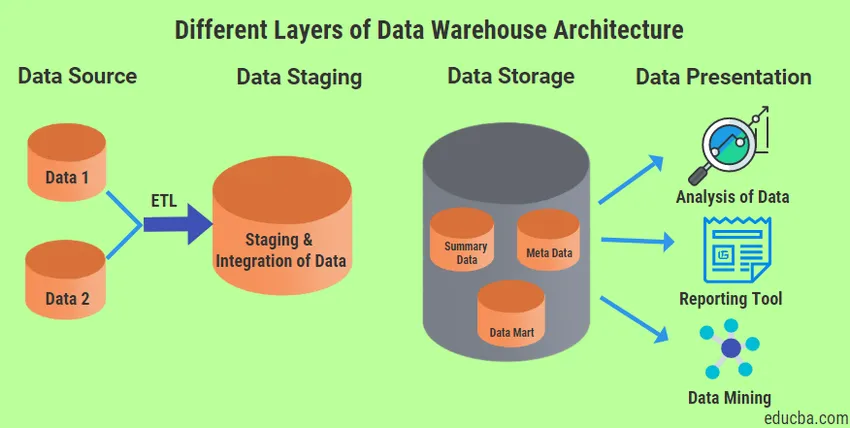
Il existe quatre types de couches différents qui seront toujours présents dans l'architecture de l'entrepôt de données.
1. Couche de source de données
- La couche de source de données est la couche où les données de la source sont rencontrées et envoyées par la suite aux autres couches pour les opérations souhaitées.
- Les données peuvent être de tout type.
- Les données source peuvent être une base de données, une feuille de calcul ou tout autre type de fichier texte.
- Les données source peuvent être de n'importe quel format. Nous ne pouvons pas nous attendre à obtenir des données avec le même format étant donné que les sources sont très différentes.
- Dans la vie réelle, certains exemples de données source peuvent être
- Fichiers journaux de chaque application ou emploi spécifique ou entrée d'employeurs dans une entreprise.
- Données d'enquête, données boursières, etc.
- Données du navigateur Web et bien d'autres.
2. Couche de transfert de données
Les étapes suivantes ont lieu dans Data Staging Layer.
1. Extraction de données
Les données reçues par la couche source sont introduites dans la couche intermédiaire où le premier processus qui a lieu avec les données acquises est l'extraction.
2. Base de données des atterrissages
- Les données extraites sont temporairement stockées dans une base de données d'atterrissage.
- Il récupère les données une fois les données extraites.
3. Zone de rassemblement
- La base de données Data in Landing est prise et plusieurs contrôles de qualité et opérations de mise en scène sont effectués dans la zone de mise en attente.
- La structure et le schéma sont également identifiés et des ajustements sont apportés aux données qui ne sont pas ordonnées, essayant ainsi de créer un point commun entre les données qui ont été acquises.
- Avoir un emplacement ou une configuration pour les données juste avant la transformation et les modifications est un avantage supplémentaire qui rend le processus de transfert très important.
- Cela facilite le traitement des données.
4. ETL
- Il s'agit d'une extraction, d'une transformation et d'une charge.
- Les outils ETL sont utilisés pour l'intégration et le traitement de données où la logique est appliquée à des données plutôt brutes mais quelque peu ordonnées.
- Ces données sont extraites selon la nature analytique requise et transformées en données jugées aptes à être stockées dans l'entrepôt de données.
- Après Transformation, les données ou plutôt une information sont finalement chargées dans l'entrepôt de données.
- Quelques exemples d'outils ETL sont Informatica, SSIS, etc.
3. Couche de stockage des données
- Les données traitées sont stockées dans l'entrepôt de données.
- Ces données sont nettoyées, transformées et préparées avec une structure définie et offrent ainsi aux employeurs la possibilité d'utiliser les données requises par l'entreprise.
- Selon l'approche de l'architecture, les données seront stockées dans l'entrepôt de données ainsi que dans les Data Marts. Les Data Marts seront discutés dans les étapes ultérieures.
- Certains incluent également un magasin de données opérationnelles.
4. Couche de présentation des données
- Cette couche où les utilisateurs peuvent interagir avec les données stockées dans l'entrepôt de données.
- Des requêtes et plusieurs outils seront utilisés pour obtenir différents types d'informations en fonction des données.
- Les informations parviennent à l'utilisateur via la représentation graphique des données.
- Les outils de génération de rapports sont utilisés pour obtenir des données métiers et la logique métier est également appliquée pour collecter plusieurs types d'informations.
- Les informations sur les métadonnées et les opérations et performances du système sont également conservées et affichées dans cette couche.
Conclusion
Un point important à propos de Data Warehouse est son efficacité. Pour créer un entrepôt de données efficace, nous construisons un framework connu sous le nom de Business Analysis Framework. Il existe quatre types de vues en ce qui concerne la conception d'un entrepôt de données.
1. Vue descendante: cette vue permet de sélectionner uniquement les informations spécifiques nécessaires pour un entrepôt de données.
2. Vue de la source de données : Cette vue affiche toutes les informations de la source de données sur la façon dont elles sont transformées et stockées.
3. Vue de l'entrepôt de données: cette vue affiche les informations présentes dans l'entrepôt de données via des tables de faits et des tables de dimensions.
4. Business Query View: il s'agit d'une vue qui montre les données du point de vue de l'utilisateur.
Articles recommandés
Cela a été un guide pour l'architecture d'entrepôt de données. Ici, nous avons discuté des différents types de vues, de couches et de niveaux de l'architecture d'entrepôt de données. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Carrière en entreposage de données
- Fonctionnement de JavaScript
- Questions d'entretiens chez Data warehouse
- Qu'est-ce que les pandas