

Qu'est-ce que le Big Data et Hadoop?
Les données augmentent de façon exponentielle chaque jour et avec une telle croissance des données, il faut utiliser ces données. Comme autrefois, nous avions des lecteurs de disquettes pour stocker les données et le transfert de données était également lent, mais de nos jours, ils sont insuffisants et le stockage dans le cloud est utilisé car nous avons des téraoctets de données. Dans le monde d'aujourd'hui, les médias sociaux contribuent le plus à la croissance des données. Il s'agit du comportement, de l'état d'esprit et de plusieurs autres aspects. On dit que chaque minute, 300 heures de vidéo sont téléchargées sur YouTube, plus de 20 millions de photos sont téléchargées sur Facebook et bien d'autres. De plus, il n'y a pas de structure appropriée des données téléchargées, ce qui constitue le plus grand défi pour le traitement de ces données.
Comme d'énormes données sont générées à grande vitesse, les systèmes SGBDR traditionnels n'étaient pas en mesure de gérer une croissance aussi rapide. De plus, ils ne sont pas non plus capables de gérer des données non structurées. Il est devenu très difficile de gérer une telle quantité de données hétérogènes en croissance rapide et de traiter ces données à une vitesse de traitement élevée. Ainsi, est né le besoin d'un tel système capable de gérer efficacement un grand ensemble de données. Par conséquent, pour résoudre le scénario Hadoop a vu le jour. HDFS est le composant de Hadoop qui a résolu le problème de stockage du grand ensemble de données en utilisant le stockage distribué tandis que YARN est le composant qui a résolu le problème de traitement en réduisant considérablement le temps de traitement.
Hadoop est une infrastructure logicielle open source pour le stockage et le traitement d'ensembles de données volumineux à l'aide d'un grand cluster distribué de matériel de base. Il a été développé par Doug Cutting et Michael J. Cafarella et sous licence Apache. Il est écrit en utilisant Java et a été développé sur la base du document écrit par Google sur le système MapReduce et il applique des concepts de programmation fonctionnelle. Il est fiable, économique, flexible et évolutif.
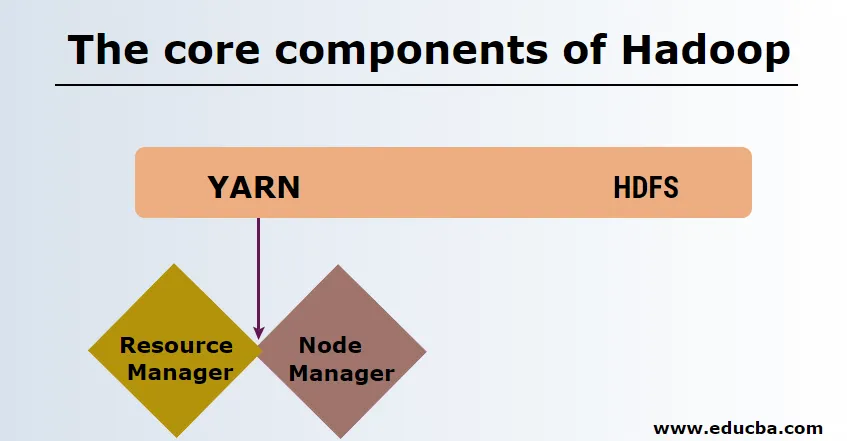
Les composants clés de Hadoop
Les composants principaux de Hadoop sont les suivants
-
HDFS
HDFS ou Hadoop Distributed File System ont Namenode et un nœud de données. Namenode est le nœud maître exécutant le démon maître et il gère les nœuds de données et garde une trace de toutes les opérations. Les nœuds de données sont les esclaves où les données sont réellement stockées.
-
FIL
YARN se compose de deux composants principaux:
1. ResourceManager: il s'exécute sur le nœud maître et gère toutes les ressources et planifie toutes les applications. Il a Scheduler & ApplicationManager.
2. NodeManager: il s'exécute sur chaque nœud esclave et est responsable de la gestion des conteneurs et de la surveillance de l'utilisation des ressources.
Plusieurs composants de Hadoop
Il y a plusieurs composants de Hadoop comme le porc, la ruche, le sqoop, le canal, le cornac, l'oozie, le gardien de zoo, HBase, etc.
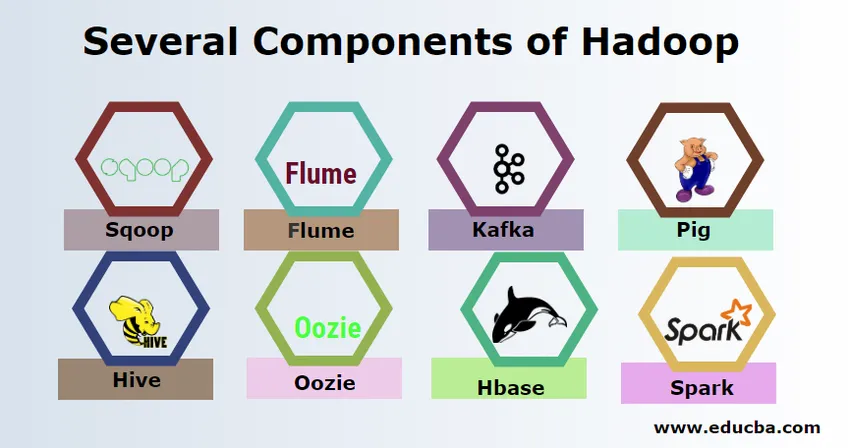
- Sqoop - Il est utilisé pour importer et exporter des données du SGBDR vers Hadoop et vice versa.
- Flume - Il est utilisé pour extraire des données en temps réel dans Hadoop.
- Kafka - Il s'agit d'un système de messagerie utilisé pour acheminer des données en temps réel vers Hadoop.
- Pig - Il est utilisé comme langage de script pour le traitement des données.
- Hive - Il s'agit d'un cadre d'entreposage de données construit sur HDFS afin que les utilisateurs familiarisés avec SQL puissent exécuter des requêtes pour obtenir les données. Ces requêtes sont appelées HiveQL.
- Oozie - Il est utilisé pour planifier le flux de travail des travaux à exécuter sur des événements ou une heure spécifiés.
- Hbase - Il s'agit de la base de données non SQL fournie dans le cadre d'Apache Hadoop.
- Spark - Il est utilisé pour effectuer un traitement en mémoire beaucoup plus rapide que la réduction de la carte Hadoop.
Fournisseurs Hadoop
Il existe de nombreuses sociétés proposant des distributions Hadoop. Voici les quelques meilleurs fournisseurs pour Hadoop:
- Cloudera
- Hortonworks
- MapR
Il y a peu de pré-requis pour apprendre Hadoop. Une expérience préalable en Java et en langage de script est nécessaire. Bien que Hadoop possède déjà ses propres langages de programmation de haut niveau comme pig et hive qui génèrent le code backend pour un traitement ultérieur, il est toujours possible de créer son propre programme de réduction de carte dans n'importe quel langage de programmation comme Ruby, Python, Perl et même la programmation C.
Bigdata et Hadoop sont en forte demande sur le marché actuel. Cela va encore augmenter dans les prochains jours. Beaucoup d'organisation ont déjà emménagé à Hadoop et ceux qui ne l'ont pas vont bientôt déménager. Un rapport actuel indique que les grandes entreprises ont commencé à investir dans l'analyse des mégadonnées. Les prévisions de marketing de Big Data sont toujours dans une tendance à la hausse et ce n'est pas du tout un état de courte durée. En dehors de tout cela, les emplois dans Hadoop et les mégadonnées offrent toujours un salaire élevé par rapport à d'autres technologies.
Meilleures entreprises de Big Data et Hadoop
Vous trouverez ci-dessous quelques entreprises de premier plan employant le plus grand nombre de ressources Hadoop.
- Yahoo
- Amazone
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
De nombreuses entreprises utilisent des applications de Big Data. Ceux-ci sont:
-
Nokia
Il utilise des composants Cloudera et Hadoop comme HDFS, HBase, Sqoop, Scribe pour l'application. Il a utilisé efficacement les données des utilisateurs pour comprendre et améliorer l'expérience de l'utilisateur. Il utilise le traitement des données et des analyses complexes pour construire la carte avec un trafic prédictif et des modèles d'altitude en couches.
-
SAS
Il a collaboré avec Hadoop pour aider les scientifiques des données à mieux comprendre en fournissant un environnement qui offre une expérience visuelle et interactive aidant ainsi à explorer de nouvelles tendances. Les programmes analytiques extraient des informations significatives des données et la technologie en mémoire permet un accès plus rapide aux données.
Il existe également de nombreuses autres entreprises utilisant des plateformes de Big Data pour diverses analyses. Ce sont l'analyse des données de vols de la boîte noire dans l'industrie aéronautique, les différentes analyses en part de marché, etc.
Avantages de Haddop
Voici quelques-uns des avantages de Hadoop
- Évolutif - Contrairement au SGBDR traditionnel, il s'agit d'une plate-forme hautement évolutive car elle peut stocker de grands ensembles de données dans des clusters distribués sur du matériel de base fonctionnant en parallèle.
- Rentable - Le coût était trop élevé pour le SGBDR pour stocker des données qui ont été supprimées dans Hadoop.
- Rapide et flexible - Il offre des données accessibles rapidement sur son système de fichiers distribué. Il propose également de tirer des informations commerciales à partir de données semi-structurées et non structurées.
- Tolérant aux pannes - Chaque fois que des données sont envoyées à un nœud, les mêmes données sont répliquées dans d'autres nœuds accessibles en cas de défaillance du premier nœud.
Conclusion - qu'est-ce que le Big Data et Hadoop
Les données ne cessent de croître et, par conséquent, le Big Data et Hadoop auront toujours besoin de donner un sens à ces données. Pour cette raison, les professionnels ayant des compétences Hadoop trouveront toujours de nombreuses opportunités dans les prochains jours et peuvent être un atout vital pour une organisation qui stimule l'entreprise et sa carrière.
Articles recommandés
Cela a été un guide sur ce qu'est le Big Data et Hadoop. Ici, nous avons discuté des concepts de base et des composants du Big Data et de Hadoop. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Exemples d'analyse de Big Data
- Utilisations de Hadoop
- Guide de visualisation des données
- Qu'est-ce que l'analyse Big Data?