
Qu'est-ce que la régression linéaire dans R?
La régression linéaire est l'algorithme le plus populaire et le plus utilisé dans le domaine des statistiques et de l'apprentissage automatique. La régression linéaire est une technique de modélisation pour comprendre la relation entre les variables d'entrée et de sortie. Ici, les variables doivent être numériques. La régression linéaire vient du fait que la variable de sortie est une combinaison linéaire de variables d'entrée. La sortie est généralement représentée par «y», tandis que l'entrée est représentée par «x».
La régression linéaire dans R peut être classée de deux manières
-
Régression linéaire si mple
Il s'agit de la régression où la variable de sortie est fonction d'une seule variable d'entrée. Représentation d'une régression linéaire simple:
y = c0 + c1 * x1
-
Régression linéaire multiple
Il s'agit de la régression où la variable de sortie est fonction d'une variable à entrées multiples.
y = c0 + c1 * x1 + c2 * x2
Dans les deux cas ci-dessus, c0, c1, c2 sont les coefficients qui représentent les poids de régression.
Régression linéaire en R
R est un outil statistique très puissant. Voyons donc comment la régression linéaire peut être effectuée dans R et comment ses valeurs de sortie peuvent être interprétées.
Préparons un ensemble de données pour effectuer et comprendre en profondeur la régression linéaire maintenant.
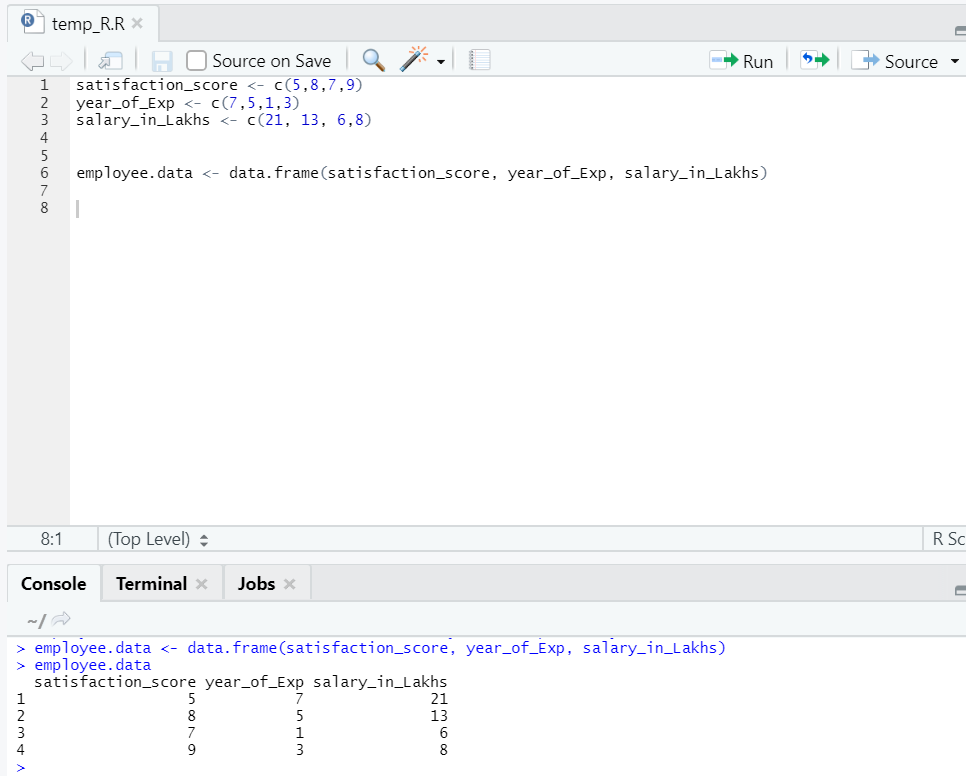
Nous avons maintenant un ensemble de données, où «satisfaction_score» et «year_of_Exp» sont la variable indépendante. «Salaire_dans_lakhs» est la variable de sortie.
En se référant à l'ensemble de données ci-dessus, le problème que nous voulons résoudre ici par régression linéaire est:
Estimation du salaire d'un salarié, basée sur son année d'expérience et son score de satisfaction dans son entreprise.
Code R de régression linéaire:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
La sortie du code ci-dessus sera:
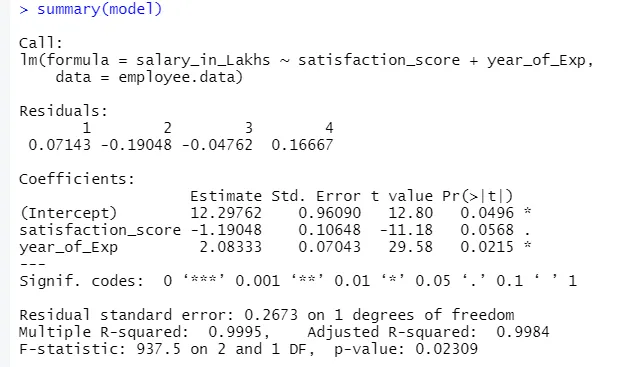
La formule de régression devient
Y = 12, 29-1, 19 * score_de satisfaction + 2, 08 × 2 * year_of_Exp
Dans le cas, on a plusieurs entrées dans le modèle.
Le code R peut alors être:
modèle <- lm (salaire_en_Lakhs ~., données = employé.données)
Cependant, si quelqu'un veut sélectionner une variable parmi plusieurs variables d'entrée, il existe plusieurs techniques telles que «Élimination vers l'arrière», «Sélection vers l'avant», etc. pour le faire également.
Interprétation de la régression linéaire dans R
Voici quelques interprétations de la régression linéaire dans r qui sont les suivantes:
1.Résidus
Il s'agit de la différence entre la réponse réelle et la réponse prévue du modèle. Donc, pour chaque point, il y aura une réponse réelle et une réponse prédite. Les résidus seront donc autant d'observations. Dans notre cas, nous avons quatre observations, donc quatre résidus.

2. coefficients
Pour aller plus loin, nous trouverons la section des coefficients, qui représente l'ordonnée à l'origine et la pente. Si l'on veut prédire le salaire d'un employé en fonction de son expérience et de son score de satisfaction, il faut développer une formule modèle basée sur la pente et l'interception. Cette formule vous aidera à prévoir le salaire. L'interception et la pente aident un analyste à trouver le meilleur modèle qui convient parfaitement aux points de données.
Pente: représente la pente de la ligne.
Interception: emplacement où la ligne coupe l'axe.
Voyons comment la formation des formules se fait en fonction de la pente et de l'ordonnée à l'origine.
Disons que l'ordonnée à l'origine est 3 et la pente est 5.
Donc, la formule est y = 3 + 5x . Cela signifie que si x augmente d'une unité, y est augmenté de 5.
a.Coefficient - Estimation
En cela, l'ordonnée à l'origine désigne la valeur moyenne de la variable de sortie, lorsque toutes les entrées deviennent nulles. Donc, dans notre cas, le salaire en lakhs sera de 12, 29 Lakhs en moyenne, compte tenu du score de satisfaction et de l'expérience nulle. Ici, la pente représente le changement de la variable de sortie avec un changement d'unité de la variable d'entrée.
b.Coefficient - Erreur standard
L'erreur standard est l'estimation de l'erreur, que nous pouvons obtenir lors du calcul de la différence entre la valeur réelle et prédite de notre variable de réponse. À son tour, cela indique la confiance pour relier les variables d'entrée et de sortie.
c.Coefficient - valeur t
Cette valeur donne la confiance nécessaire pour rejeter l'hypothèse nulle. Plus la valeur éloignée de zéro est élevée, plus la confiance pour rejeter l'hypothèse nulle est grande et établir la relation entre la variable de sortie et d'entrée. Dans notre cas, la valeur est également loin de zéro.
d.Coefficient - Pr (> t)
Cet acronyme représente essentiellement la valeur de p. Plus il est proche de zéro, plus il est facile de rejeter l'hypothèse nulle. La ligne que nous voyons dans notre cas, cette valeur est proche de zéro, nous pouvons dire qu'il existe une relation entre le salaire, le score de satisfaction et l'année d'expérience.

Erreur standard résiduelle
Cela illustre l'erreur dans la prédiction de la variable de réponse. Plus il est bas, plus la précision du modèle est élevée.
R-carré multiple, R-carré ajusté
Le R au carré est une mesure statistique très importante pour comprendre à quel point les données se sont ajustées dans le modèle. D'où, dans notre cas, dans quelle mesure notre modèle de régression linéaire représente l'ensemble de données.
La valeur R au carré se situe toujours entre 0 et 1. La formule est:

Plus la valeur est proche de 1, mieux le modèle décrit les ensembles de données et sa variance.
Cependant, lorsque plusieurs variables d'entrée apparaissent dans l'image, la valeur au carré R ajustée est préférée.
F-Statistic
C'est une mesure forte pour déterminer la relation entre la variable d'entrée et la variable de réponse. Plus la valeur est supérieure à 1, plus la confiance dans la relation entre la variable d'entrée et de sortie est élevée.
Dans notre cas, son «937, 5», qui est relativement plus grand compte tenu de la taille des données. Par conséquent, le rejet de l'hypothèse nulle devient plus facile.
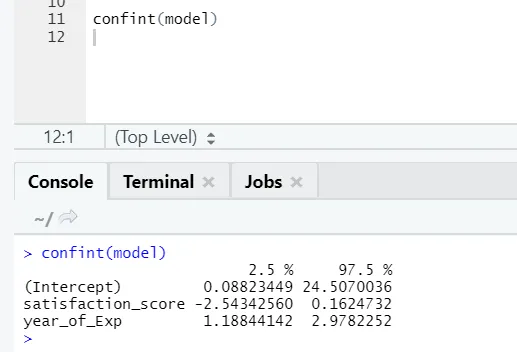
Si quelqu'un veut voir l'intervalle de confiance pour les coefficients du modèle, voici la façon de le faire: -
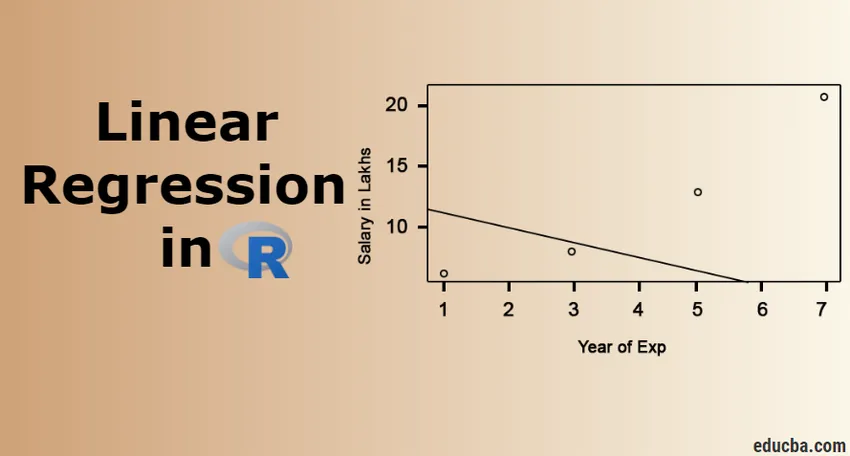
Visualisation de la régression
Code R:
plot (salaire_dans_Lakhs ~ satisfaction_score + année_de_Exp, données = employé.données)
abline (modèle)
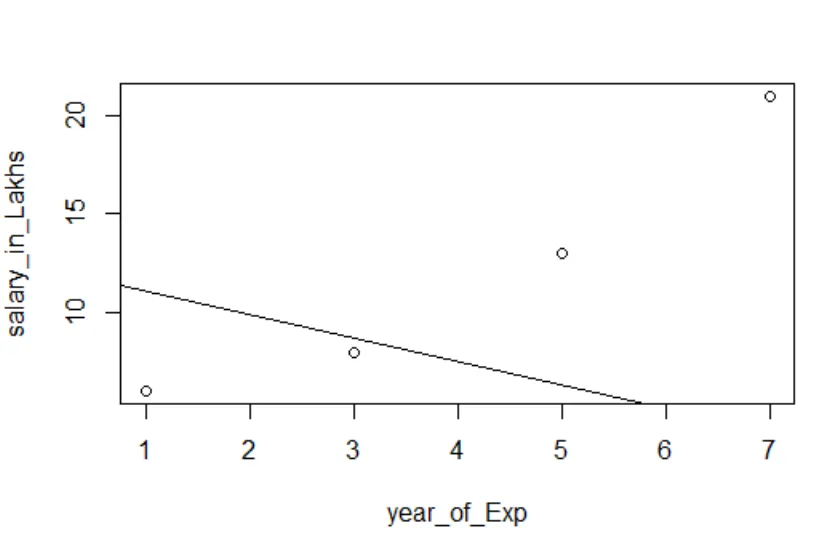
Il est toujours préférable de rassembler de plus en plus de points avant de s'adapter à un modèle.
Conclusion - Régression linéaire dans R
La régression linéaire est un modèle simple, facile à adapter, facile à comprendre mais très puissant. Nous avons vu comment la régression linéaire peut être effectuée sur R. Nous avons également essayé d'interpréter les résultats, ce qui peut vous aider dans l'optimisation du modèle. Une fois que l'on se familiarise avec la régression linéaire simple, il faut essayer la régression linéaire multiple. Parallèlement à cela, la régression linéaire étant sensible aux valeurs aberrantes, il faut l'examiner avant de sauter directement dans l'ajustement à la régression linéaire.
Articles recommandés
Ceci est un guide de régression linéaire dans R. Ici, nous avons discuté de ce qu'est la régression linéaire dans R? catégorisation, visualisation et interprétation de R. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Modélisation prédictive
- Régression logistique en R
- Arbre de décision en R
- Questions d'entretiens chez R
- Principales différences de régression vs classification
- Guide de l'arbre de décision dans l'apprentissage automatique
- Régression linéaire vs régression logistique | Principales différences