

Qu'est-ce qu'AWS Kinesis?
Kinesis est une plate-forme qui aide à collecter, traiter et analyser les données de streaming dans Amazon Web Services. Les données en streaming sont une grande quantité de données générées à partir de différentes sources telles que les médias sociaux, les capteurs IoT, les prévisions météorologiques, les soins de santé, etc. Ceux-ci sont utilisés dans la création d'applications en fonction des besoins de l'utilisateur. Certaines des applications courantes incluent l'analyse prédictive dans les mégadonnées, l'apprentissage automatique, etc. Dans cette rubrique, nous allons en savoir plus sur AWS Kinesis.
Services AWS Kinesis
Avant de passer aux services, comprenons d'abord quelques terminologies utilisées dans Kinesis.
Terminologie
| Terme | Définition |
| Enregistrement de données | Unité de données stockée dans le flux de données de Kinesis. Il se compose d'un blob de données, d'un numéro de séquence et d'une clé de partition |
| Tesson | Ensemble de la séquence d'enregistrements de données. Le nombre d'éclats peut être augmenté ou diminué si le débit de données est augmenté. |
| Durée de conservation | Période pendant laquelle les données sont accessibles après leur ajout au flux.
Période de rétention par défaut: 24 heures |
| Producteur | Il feds les enregistrements de données dans Kinesis Stream |
| Consommateur | Il obtient les enregistrements de Kinesis Stream et les traite. |
Kinesis fournit 3 services principaux. Elles sont:
1. Kinesis Streams
Kinesis Stream se compose d'un ensemble de séquences d'enregistrements de données appelés Shards. Ces fragments ont une capacité fixe qui peut fournir un taux de lecture maximum de 2 Mo / seconde et un taux d'écriture de 1 Mo / seconde. La capacité maximale d'un flux est la somme de la capacité de chaque fragment.
Fonctionnement de Kinesis:
- Les données produites par l'IoT et d'autres sources connues sous le nom de producteurs sont introduites dans les flux Kinesis pour être stockées dans Shards.
- Ces données seront disponibles dans Shard pendant 24 heures maximum.
- S'il doit être stocké plus longtemps que ce délai par défaut, l'utilisateur peut passer à une période de rétention de 7 jours.
- Une fois que les données ont atteint les fragments, les instances EC2 peuvent utiliser ces données à différentes fins.
- Les instances EC2 qui récupèrent des données sont appelées consommateurs.
- Après le traitement des données, elles sont introduites dans l'un des services Web d'Amazon tels que Simple Storage Service (S3), DynamoDB, Redshift, etc.
2. Kinesis Firehose
Kinesis Firehose est utile pour déplacer des données vers des services Web Amazon tels que Redshift, service de stockage simple, Elastic Search, etc. Il fait partie de la plate-forme de streaming qui ne gère aucune ressource. Les producteurs de données sont configurés de telle sorte que les données doivent être envoyées à Kinesis Firehose et il les envoie ensuite automatiquement à la destination correspondante.
Fonctionnement de Kinesis Firehose:
- Comme mentionné dans le travail d'AWS Kinesis Streams, Kinesis Firehose obtient également des données de producteurs tels que les téléphones mobiles, les ordinateurs portables, EC2, etc. Mais, cela n'a pas à prendre les données en fragments ou à augmenter les périodes de rétention comme Kinesis Streams. C'est parce que Kinesis Firehose le fait automatiquement.
- Les données sont ensuite analysées automatiquement et introduites dans Simple Storage Service
- Puisqu'il n'y a pas de période de conservation, les données doivent être analysées ou envoyées à n'importe quel stockage dépend des besoins de l'utilisateur.
- Si des données doivent être envoyées à Redshift, elles doivent d'abord être déplacées vers Simple Storage Service et doivent être copiées vers Redshift à partir de là.
- Mais, dans le cas d'Elastic Search, les données peuvent y être directement introduites, comme pour Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose permet d'exécuter les requêtes SQL dans les données présentes dans Kinesis Firehose. En utilisant ces requêtes SQL, les données peuvent être stockées dans Redshift, Simple Storage Service, ElasticSearch, etc.
Architecture AWS Kinesis
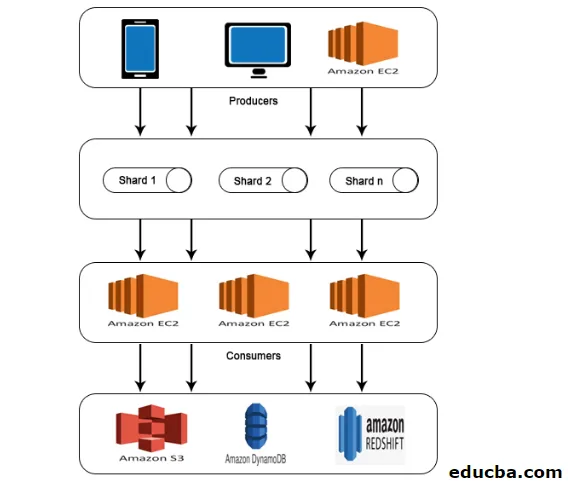
L'AWS Kinesis Architecture se compose de
- Producteurs
- Fragments
- Les consommateurs
- Espace de rangement
Comme pour le travail expliqué dans AWS Kinesis Data Stream, les données des producteurs sont introduites dans Shards où les données sont traitées et analysées. Les données analysées sont ensuite déplacées vers des instances EC2 pour effectuer certaines applications. Enfin, les données seront stockées dans l'un des services Web d'Amazon tels que S3, Redshift, etc.
Comment utiliser AWS kinesis?
Pour travailler avec AWS Kinesis, les deux étapes suivantes doivent être effectuées.
1. Installez l'interface de ligne de commande AWS (CLI).
L'installation de l'interface de ligne de commande est différente pour différents systèmes d'exploitation. Installez donc CLI en fonction de votre système d'exploitation.
Pour les utilisateurs Linux, utilisez la commande sudo pip install AWS CLI
Assurez-vous que vous disposez d'une version python 2.6.5 ou supérieure. Après le téléchargement, configurez-le à l'aide de la commande AWS configure. Ensuite, les détails suivants seront demandés comme indiqué ci-dessous.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Pour les utilisateurs de Windows, téléchargez le programme d'installation MSI approprié et exécutez-le.
2. Effectuer des opérations Kinesis à l'aide de CLI
Veuillez noter que les flux de données Kinesis ne sont pas disponibles pour le niveau gratuit AWS. Ainsi, les flux Kinesis créés seront facturés.
Voyons maintenant quelques opérations kinesis en CLI.
- Créer un flux
Créez un flux KStream avec Shard count 2 à l'aide de la commande suivante.
aws kinesis create-stream --stream-name KStream --shard-count 2
Vérifiez si le flux a été créé.
aws kinesis describe-stream --stream-name KStream
S'il est créé, une sortie similaire à l'exemple suivant apparaîtra.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Mettre un record
Maintenant, un enregistrement de données peut être inséré à l'aide de la commande put-record. Ici, un enregistrement contenant un test de données est inséré dans le flux.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Si l'insertion réussit, la sortie sera affichée comme indiqué ci-dessous.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Get Record
Tout d'abord, l'utilisateur doit obtenir l'itérateur de fragment qui représente la position du flux pour le fragment.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Ensuite, exécutez la commande à l'aide de l'itérateur de fragment obtenu.
aws kinesis get-records --shard-iterator ###########
Un exemple de sortie sera obtenu comme indiqué ci-dessous.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Nettoyer
Pour éviter les frais, le flux créé peut être supprimé à l'aide de la commande ci-dessous.
aws kinesis delete-stream --stream-name KStream
Conclusion
AWS Kinesis est une plate-forme qui collecte, traite et analyse les données de streaming pour plusieurs applications comme l'apprentissage automatique, l'analyse prédictive, etc. Les données en streaming peuvent être de n'importe quel format tel que audio, vidéo, données de capteur, etc.
Articles recommandés
Ceci est un guide d'AWS Kinesis. Nous discutons ici comment utiliser AWS Kinesis et également son service avec le travail et l'architecture. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Architecture AWS
- Qu'est-ce qu'AWS Lambda?
- Technologies Big Data
- Architecture d'exploration de données
- Services de stockage AWS
- Guide des concurrents d'AWS avec fonctionnalités