

Introduction aux commandes Spark
Apache Spark est un framework construit au dessus de Hadoop pour des calculs rapides. Il étend le concept de MapReduce dans le scénario basé sur un cluster pour exécuter efficacement une tâche. La commande Spark est écrite en Scala.
Hadoop peut être utilisé par Spark des manières suivantes (voir ci-dessous):
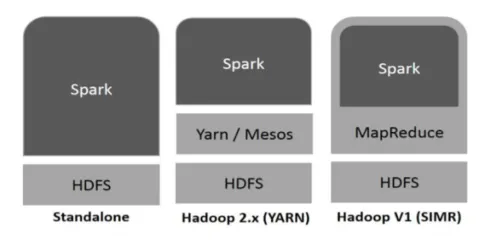
Fig. 1
https://www.tutorialspoint.com/
- Autonome: Spark déployé directement sur Hadoop. Les travaux Spark s'exécutent en parallèle sur Hadoop et Spark.
- Hadoop YARN: Spark fonctionne sur Yarn sans avoir besoin de pré-installation.
- Spark dans MapReduce (SIMR): Spark dans MapReduce est utilisé pour lancer un travail spark, en plus du déploiement autonome. Avec SIMR, on peut démarrer Spark et utiliser son shell sans aucun accès administratif.
Composants de Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Les jeux de données distribués résilients (RDD) sont considérés comme la structure de données fondamentale des commandes Spark. RDD est immuable et en lecture seule. Tous les types de calculs dans les commandes spark sont effectués via des transformations et des actions sur les RDD.
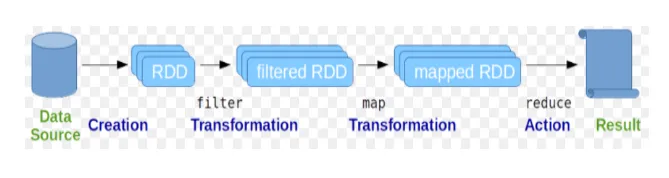
Fig 2
Google Image
Le shell Spark fournit aux utilisateurs un moyen d'interagir avec ses fonctionnalités. Les commandes Spark ont de nombreuses commandes différentes qui peuvent être utilisées pour traiter des données sur le shell interactif.
Commandes de base de l'étincelle
Jetons un coup d'œil à certaines des commandes Basic Spark qui sont données ci-dessous: -
-
Pour démarrer le shell Spark:

Fig 3
-
Lire le fichier du système local:

Ici, «sc» est le contexte de l'étincelle. Étant donné que «data.txt» se trouve dans le répertoire personnel, il est lu comme ceci, sinon il faut spécifier le chemin complet.
-
Créer un RDD en parallélisant

NewData est maintenant le RDD.
-
Compter les éléments dans RDD

-
Collecte
Cette fonction renvoie tout le contenu de RDD au programme du pilote. Cela est utile pour déboguer à différentes étapes du programme d'écriture.
-
Lire les 3 premiers éléments du RDD

-
Enregistrer les données de sortie / traitées dans le fichier texte

Ici, le dossier «sortie» est le chemin actuel.
Commandes d'étincelle intermédiaires
1. Filtrer sur RDD
Créons un nouveau RDD pour les éléments qui contiennent «oui».

Le filtre de transformation doit être appelé sur le RDD existant pour filtrer sur le mot «oui», ce qui créera un nouveau RDD avec la nouvelle liste d'éléments.
2. Fonctionnement de la chaîne

Ici, la transformation du filtre et l'action de comptage ont agi ensemble. C'est ce qu'on appelle le fonctionnement en chaîne.
3. Lisez le premier élément de RDD

4. Compter les partitions RDD
Comme nous le savons, RDD est composé de plusieurs partitions, il se produit la nécessité de compter le non. de partitions. Comme cela aide au réglage et au dépannage tout en travaillant avec les commandes Spark.

Par défaut, pas de minimum. la partition pf est 2.
5. rejoindre
Cette fonction joint deux tables (l'élément de table est en mode paire) basé sur la clé commune. Dans RDD par paire, le premier élément est la clé et le deuxième élément est la valeur.
6. Cachez un fichier
La mise en cache est une technique d'optimisation. La mise en cache du RDD signifie que le RDD résidera en mémoire et que tous les calculs futurs seront effectués sur ces RDD en mémoire. Il économise le temps de lecture du disque et améliore les performances. En bref, cela réduit le temps d'accès aux données.

Cependant, les données ne seront pas mises en cache si vous exécutez la fonction ci-dessus. Cela peut être prouvé en visitant la page Web:
http: // localhost: 4040 / stockage
RDD sera mis en cache, une fois l'action terminée. Par exemple:

Une fonction de plus qui fonctionne de manière similaire à cache () est persist (). Persist donne aux utilisateurs la flexibilité de donner l'argument, ce qui peut aider les données à être mises en cache dans la mémoire, le disque ou la mémoire hors tas. Persister sans aucun argument fonctionne de la même manière que cache ().
Commandes avancées d'étincelle
Jetons un coup d'œil à certaines des commandes avancées de Spark qui sont données ci-dessous: -
-
Diffuser une variable
La variable de diffusion aide le programmeur à continuer de lire la seule variable mise en cache sur chaque machine du cluster, plutôt que d'envoyer une copie de cette variable avec des tâches. Cela aide à réduire les coûts de communication.
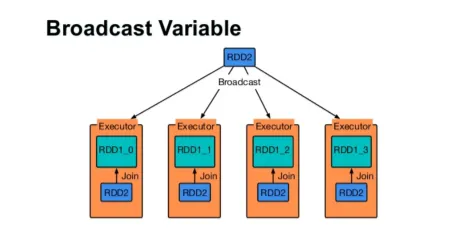
Fig 4
Google Image
En bref, il existe trois caractéristiques principales de la variable Broadcasted:
- Immuable
- Tenir en mémoire
- Distribué sur le cluster
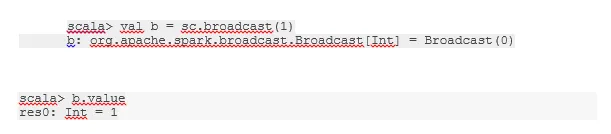
-
Accumulateurs
Les accumulateurs sont les variables qui s'ajoutent aux opérations associées. Il existe de nombreuses utilisations pour les accumulateurs comme les compteurs, les sommes, etc.

Le nom de l'accumulateur dans le code peut également être vu dans l'interface utilisateur de Spark.
-
Carte
La fonction de carte aide à itérer sur chaque ligne du RDD. La fonction utilisée dans la carte est appliquée à chaque élément de RDD.
Par exemple, dans RDD (1, 2, 3, 4, 6) si nous appliquons "rdd.map (x => x + 2)", nous obtiendrons le résultat sous la forme (3, 4, 5, 6, 8).
-
Flatmap
Flatmap fonctionne de manière similaire à la carte, mais map ne renvoie qu'un seul élément tandis que la flatmap peut renvoyer la liste des éléments. Par conséquent, la division des phrases en mots nécessitera une carte plate.
-
Se fondre
Cette fonction permet d'éviter le brassage des données. Ceci est appliqué dans la partition existante afin que moins de données soient mélangées. De cette façon, nous pouvons restreindre l'utilisation des nœuds dans le cluster.
Trucs et astuces pour utiliser les commandes spark
Voici les différents trucs et astuces des commandes Spark: -
- Les débutants de Spark peuvent utiliser Spark-shell. Comme les commandes Spark sont construites sur Scala, il est donc très utile d'utiliser shell scala spark. Cependant, le shell python spark est également disponible, donc même quelque chose que l'on peut utiliser, qui connaît bien python.
- Le shell Spark possède de nombreuses options pour gérer les ressources du cluster. La commande ci-dessous peut vous aider:

- Dans Spark, travailler avec de longs ensembles de données est la chose habituelle. Mais les choses tournent mal en cas de mauvaise saisie. C'est toujours une bonne idée de supprimer les mauvaises lignes en utilisant la fonction de filtre de Spark. Le bon ensemble d'entrées sera un excellent choix.
- Spark choisit une bonne partition par elle-même pour vos données. Mais c'est toujours une bonne pratique de garder un œil sur les partitions avant de commencer votre travail. Essayer différentes partitions vous aidera à paralléliser votre travail.
Conclusion - Commandes Spark:
La commande Spark est un moteur de Big Data révolutionnaire et polyvalent, qui peut fonctionner pour le traitement par lots, le traitement en temps réel, la mise en cache des données, etc. applications rapides.
Articles recommandés
Cela a été un guide pour les commandes Spark. Ici, nous avons discuté des commandes Spark de base et avancées et de certaines commandes Spark immédiates. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Commandes Adobe Photoshop
- Commandes VBA importantes
- Commandes Tableau
- Aide-mémoire SQL (commandes, conseils gratuits et astuces)
- Types de jointures dans Spark SQL (exemples)
- Composants Spark | Présentation et 6 principaux composants