

Introduction à l'algorithme AdaBoost
L'algorithme AdaBoost peut être utilisé pour augmenter les performances de tout algorithme d'apprentissage automatique. L'apprentissage automatique est devenu un outil puissant qui peut faire des prédictions basées sur une grande quantité de données. Il est devenu si populaire ces derniers temps que l'application de l'apprentissage automatique peut être trouvée dans nos activités quotidiennes. Un exemple courant consiste à obtenir des suggestions de produits lors de vos achats en ligne en fonction des anciens articles achetés par le client. L'apprentissage automatique, souvent appelé analyse prédictive ou modélisation prédictive, peut être défini comme la capacité des ordinateurs à apprendre sans être programmé explicitement. Il utilise des algorithmes programmés pour analyser les données d'entrée afin de prédire la sortie dans une plage acceptable.
Qu'est-ce que l'algorithme AdaBoost?
Dans l'apprentissage automatique, le boosting est né de la question de savoir si un ensemble de classificateurs faibles pouvait être converti en un classificateur puissant. Un apprenant faible ou un classificateur est un apprenant qui est meilleur que la supposition aléatoire et cela sera robuste en sur-ajustement comme dans un grand ensemble de classificateurs faibles, chaque classificateur faible étant meilleur que aléatoire. En tant que classificateur faible, un seuil simple sur une seule caractéristique est généralement utilisé. Si la caractéristique est supérieure au seuil prévu, elle appartient au positif, sinon au négatif.
AdaBoost signifie «Adaptive Boosting» qui transforme les apprenants faibles ou les prédicteurs en prédicteurs forts afin de résoudre les problèmes de classification.
Pour la classification, l'équation finale peut être mise comme ci-dessous: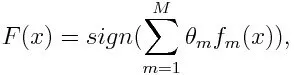
Ici f m désigne le m ème classificateur faible et m représente son poids correspondant.
Comment fonctionne l'algorithme AdaBoost?
AdaBoost peut être utilisé pour améliorer les performances des algorithmes d'apprentissage automatique. Il est mieux utilisé avec les apprenants faibles et ces modèles atteignent une grande précision au-dessus du hasard sur un problème de classification. Les algorithmes courants avec AdaBoost utilisés sont des arbres de décision de niveau un. Un apprenant faible est un classificateur ou un prédicteur dont les performances sont relativement médiocres en termes de précision. En outre, il peut être sous-entendu que les apprenants faibles sont simples à calculer et que de nombreuses instances d'algorithmes sont combinées pour créer un classificateur solide grâce à la stimulation.
Si nous prenons un ensemble de données contenant n nombre de points, et considérons ce qui suit
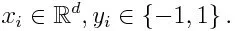
-1 représente la classe négative et 1 indique positif. Il est initialisé comme ci-dessous, le poids pour chaque point de données étant:
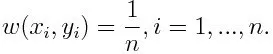
Si nous considérons l'itération de 1 à M pour m, nous obtiendrons l'expression ci-dessous:
Tout d'abord, nous devons sélectionner le classificateur faible avec l'erreur de classification pondérée la plus faible en adaptant les classificateurs faibles à l'ensemble de données.
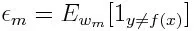
Calculer ensuite le poids du m ème classificateur faible comme ci-dessous:
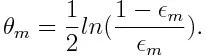
Le poids est positif pour tout classificateur avec une précision supérieure à 50%. Le poids devient plus grand si le classificateur est plus précis et il devient négatif si le classificateur a une précision inférieure à 50%. La prédiction peut être combinée en inversant le signe. En inversant le signe de la prédiction, un classificateur avec une précision de 40% peut être converti en une précision de 60%. Ainsi, le classificateur contribue à la prédiction finale, même s'il est moins performant qu'une estimation aléatoire. Cependant, la prédiction finale n'aura aucune contribution ou n'obtiendra pas d'informations du classificateur avec une précision de 50%. Le terme exponentiel dans le numérateur est toujours supérieur à 1 pour un cas mal classé du classificateur pondéré positif. Après l'itération, les cas mal classés sont mis à jour avec des poids plus importants. Les classificateurs pondérés négatifs se comportent de la même manière. Mais il y a une différence qu'après que le signe est inversé; les classifications correctes se convertiraient à l'origine en une mauvaise classification. La prédiction finale peut être calculée en prenant en compte chaque classificateur puis en effectuant la somme de leur prédiction pondérée.
Mise à jour du poids pour chaque point de données comme ci-dessous:
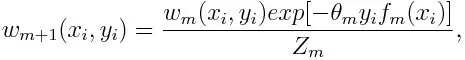
Z m est ici le facteur de normalisation. Il s'assure que la somme totale de tous les poids d'instance devient égale à 1.
À quoi sert l'algorithme AdaBoost?
AdaBoost peut être utilisé pour la détection des visages car il semble être l'algorithme standard pour la détection des visages dans les images. Il utilise une cascade de rejet composée de plusieurs couches de classificateurs. Lorsque la fenêtre de détection n'est reconnue sur aucun calque comme un visage, elle est rejetée. Le premier classificateur de la fenêtre rejette la fenêtre négative en maintenant le coût de calcul au minimum. Bien qu'AdaBoost combine les classificateurs faibles, les principes d'AdaBoost sont également utilisés pour trouver les meilleures fonctionnalités à utiliser dans chaque couche de la cascade.
Avantages et inconvénients de l'algorithme AdaBoost
L'un des nombreux avantages de l'algorithme AdaBoost est qu'il est rapide, simple et facile à programmer. En outre, il a la flexibilité d'être combiné avec n'importe quel algorithme d'apprentissage automatique et il n'est pas nécessaire de régler les paramètres sauf pour T. Il a été étendu aux problèmes d'apprentissage au-delà de la classification binaire et il est polyvalent car il peut être utilisé avec du texte ou du numérique Les données.
AdaBoost présente également peu d'inconvénients tels qu'il provient de preuves empiriques et est particulièrement vulnérable au bruit uniforme. Des classificateurs faibles étant trop faibles peuvent entraîner de faibles marges et un sur-ajustement.
Exemple d'algorithme AdaBoost
Nous pouvons considérer un exemple d'admission d'étudiants dans une université où ils seront admis ou refusés. Ici, les données quantitatives et qualitatives peuvent être trouvées sous différents aspects. Par exemple, le résultat de l'admission qui pourrait être oui / non peut être quantitatif alors que tout autre domaine comme les compétences ou les passe-temps des étudiants peut être qualitatif. Nous pouvons trouver facilement la classification correcte des données de formation au mieux que la chance pour des conditions comme si l'étudiant est bon dans un sujet particulier, alors il / elle est admis. Mais il est difficile de trouver des prévisions très précises et les apprenants faibles entrent en jeu.
Conclusion
AdaBoost aide à choisir l'ensemble de formation pour chaque nouveau classificateur qui est formé en fonction des résultats du classificateur précédent. Aussi en combinant les résultats; il détermine le poids à accorder à la réponse proposée par chaque classificateur. Il combine les apprenants faibles pour en créer un fort pour corriger les erreurs de classification, qui est également le premier algorithme de stimulation réussi pour les problèmes de classification binaire.
Articles recommandés
Cela a été un guide pour l'algorithme AdaBoost. Ici, nous avons discuté du concept, des utilisations, du travail, des avantages et des inconvénients avec l'exemple. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Algorithme Naive Bayes
- Questions d'entretiens chez Social Media Marketing
- Stratégies de création de liens
- Plateforme de marketing des médias sociaux