
Introduction à l'ensachage et au boosting
L'ensachage et le boosting sont les deux méthodes d'ensemble les plus populaires. Donc, avant de comprendre l'ensachage et le renforcement, ayons une idée de ce qu'est l'apprentissage collectif. C'est la technique qui consiste à utiliser plusieurs algorithmes d'apprentissage pour former des modèles avec le même ensemble de données afin d'obtenir une prédiction en apprentissage automatique. Après avoir obtenu la prédiction de chaque modèle, nous utiliserons des techniques de moyenne de modèle comme la moyenne pondérée, la variance ou le vote max pour obtenir la prédiction finale. Cette méthode vise à obtenir de meilleures prédictions que le modèle individuel. Il en résulte une meilleure précision évitant le sur-ajustement et réduit le biais et la co-variance. Deux méthodes d'ensemble populaires sont:
- Ensachage (Bootstrap Aggregating)
- Booster
Ensachage:
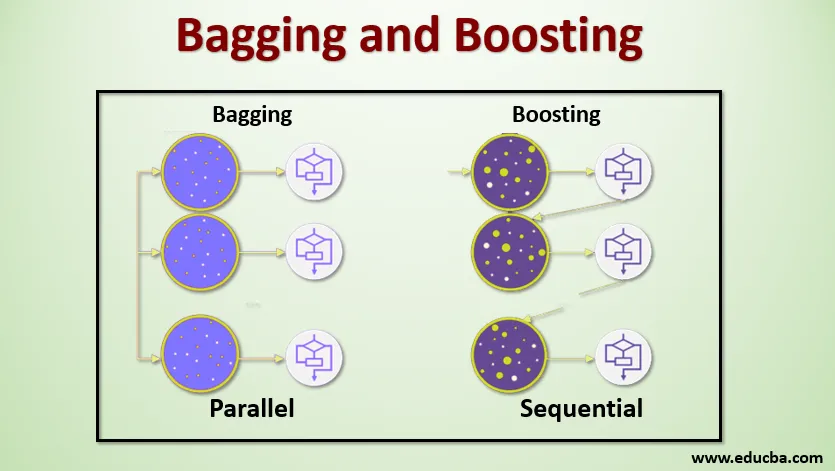
L'ensachage, également connu sous le nom de Bootstrap Aggregating, est utilisé pour améliorer la précision et rend le modèle plus généralisé en réduisant la variance, c'est-à-dire en évitant le sur-ajustement. Pour cela, nous prenons plusieurs sous-ensembles de l'ensemble de données d'apprentissage. Pour chaque sous-ensemble, nous prenons un modèle avec les mêmes algorithmes d'apprentissage comme l'arbre de décision, la régression logistique, etc. pour prédire la sortie pour le même ensemble de données de test. Une fois que nous avons une prédiction de chaque modèle, nous utilisons une technique de moyenne de modèle pour obtenir la sortie de prédiction finale. La forêt aléatoire est l'une des célèbres techniques utilisées dans l'ensachage . Dans la forêt aléatoire, nous utilisons plusieurs arbres de décision.
Boosting :
Le renforcement est principalement utilisé pour réduire le biais et la variance dans une technique d'apprentissage supervisé. Il fait référence à la famille d'un algorithme qui convertit les apprenants faibles (apprenant de base) en apprenants forts. L'apprenant faible est les classificateurs qui ne sont corrects que dans une faible mesure avec la classification réelle, tandis que les apprenants forts sont les classificateurs qui sont bien corrélés avec la classification réelle. Peu de techniques célèbres de Boosting sont AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Alors maintenant, nous savons ce que sont l'ensachage et le boosting et quels sont leurs rôles dans le Machine Learning.
Fonctionnement de l'ensachage et du boosting
Maintenant, comprenons comment fonctionne l'ensachage et le boost:
Ensachage
Pour comprendre le fonctionnement de l'ensachage, supposons que nous avons un nombre N de modèles et un ensemble de données D. Où m est le nombre de données et n est le nombre de fonctionnalités dans chaque donnée. Et nous sommes censés faire une classification binaire. Tout d'abord, nous allons diviser l'ensemble de données. Pour l'instant, nous allons diviser cet ensemble de données en ensemble de formation et de test uniquement. Appelons l'ensemble de données de formation comme où est le nombre total d'exemples de formation.
Prenez un échantillon d'enregistrements de l'ensemble d'entraînement et utilisez-le pour former le premier modèle, par exemple m1. Pour le modèle suivant, m2 rééchantillonne l'ensemble d'apprentissage et prend un autre échantillon de l'ensemble d'apprentissage. Nous ferons la même chose pour le nombre N de modèles. Étant donné que nous rééchantillonnons le jeu de données d'apprentissage et que nous en prélevons des échantillons sans rien supprimer du jeu de données, il est possible que nous ayons deux enregistrements de données d'apprentissage ou plus communs à plusieurs échantillons. Cette technique de rééchantillonnage de l'ensemble de données d'apprentissage et de fourniture de l'échantillon au modèle est appelée échantillonnage de lignes avec remplacement. Supposons que nous avons formé chaque modèle et que nous voulons maintenant voir la prédiction sur les données de test. Étant donné que nous travaillons sur la classification binaire, la sortie peut être égale à 0 ou 1. L'ensemble de données de test est transmis à chaque modèle et nous obtenons une prédiction à partir de chaque modèle. Disons que sur N modèles plus que N / 2 modèles l'ont prédit comme étant 1, donc en utilisant la technique de calcul de moyenne de modèle comme le vote maximum, nous pouvons dire que la sortie prédite pour les données de test est 1.
Booster
En boostant, nous prenons des enregistrements de l'ensemble de données et les transmettons aux apprenants de base séquentiellement, ici les apprenants de base peuvent être n'importe quel modèle. Supposons que nous ayons m nombre d'enregistrements dans l'ensemble de données. Ensuite, nous passons quelques enregistrements pour baser l'apprenant BL1 et le former. Une fois que le BL1 est formé, nous passons tous les enregistrements de l'ensemble de données et voyons comment fonctionne l'apprenant de base. Pour tous les enregistrements qui sont classés incorrectement par l'apprenant de base, nous les prenons uniquement et les transmettons à un autre apprenant de base, par exemple BL2, et simultanément nous transmettons les enregistrements incorrects classés par BL2 pour former BL3. Cela se poursuivra à moins que et jusqu'à ce que nous spécifions un nombre spécifique de modèles d'apprenants de base dont nous avons besoin. Enfin, nous combinons les résultats de ces apprenants de base et créons un apprenant fort, ce qui améliore la puissance de prédiction du modèle. D'accord. Alors maintenant, nous savons comment fonctionne le Bagging and Boosting.
Avantages et inconvénients de l'ensachage et du boost
Vous trouverez ci-dessous les principaux avantages et inconvénients.
Avantages de l'ensachage
- Le plus grand avantage de l'ensachage est que plusieurs apprenants faibles peuvent mieux fonctionner qu'un seul apprenant fort.
- Il offre une stabilité et augmente la précision de l'algorithme d'apprentissage automatique utilisé dans la classification statistique et la régression.
- Il aide à réduire la variance, c'est-à-dire qu'il évite le sur-ajustement.
Inconvénients de l'ensachage
- Il peut entraîner un biais élevé s'il n'est pas modélisé correctement et peut donc entraîner un sous-ajustement.
- Comme nous devons utiliser plusieurs modèles, cela devient coûteux en calcul et peut ne pas convenir dans divers cas d'utilisation.
Avantages du boost
- C'est l'une des techniques les plus efficaces pour résoudre les problèmes de classification à deux classes.
- Il est bon pour gérer les données manquantes.
Inconvénients de la stimulation
- Le boosting est difficile à implémenter en temps réel en raison de la complexité accrue de l'algorithme.
- La grande flexibilité de ces techniques se traduit par un nombre multiple de paramètres qui ont un effet direct sur le comportement du modèle.
Conclusion
Le principal point à retenir est que l'ensachage et le renforcement sont un paradigme d'apprentissage automatique dans lequel nous utilisons plusieurs modèles pour résoudre le même problème et obtenir de meilleures performances.Et si nous combinons correctement les apprenants faibles, nous pouvons obtenir un modèle stable, précis et robuste. Dans cet article, j'ai donné un aperçu de base de l'ensachage et du boosting. Dans les prochains articles, vous apprendrez à connaître les différentes techniques utilisées dans les deux. Enfin, je conclurai en vous rappelant que l'ensachage et le boosting font partie des techniques d'apprentissage d'ensemble les plus utilisées. Le véritable art d'améliorer les performances réside dans votre compréhension du moment d'utiliser quel modèle et comment régler les hyperparamètres.
Articles recommandés
Ceci est un guide pour l'ensachage et le renforcement. Ici, nous discutons de l'introduction à l'ensachage et au renforcement et cela fonctionne avec les avantages et les inconvénients. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Introduction aux techniques d'ensemble
- Catégories d'algorithmes d'apprentissage automatique
- Algorithme de renforcement de dégradé avec exemple de code
- Qu'est-ce que l'algorithme de stimulation?
- Comment créer un arbre de décision?