
Qu'est-ce que Cassandra?
Cassandra est une base de données NoSQL qui est une base de données distribuée peer to peer. Il s'exécute sur un cluster qui a des nœuds homogènes. Il est conçu de manière à pouvoir traiter de gros volumes de données. La gestion de ces données devrait également être en mesure de fournir une capacité élevée. Cassandra fournit des performances élevées tout au long des opérations de lecture et d'écriture. L'architecture du cluster Cassandra n'a pas de maîtres, d'esclaves ou de leaders spécifiques. En utilisant cette méthode, il s'assure qu'il n'y a pas de point de défaillance unique. Jetons un œil à l'architecture en détail.
Architecture de Cassandra
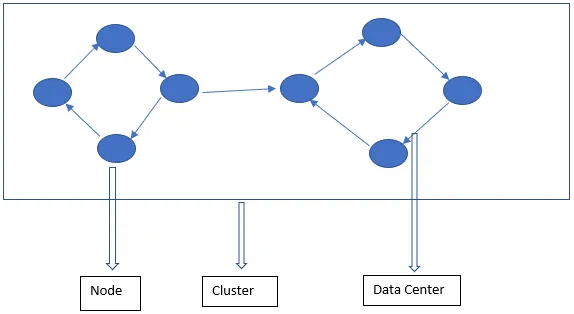
L'architecture Cassandra se compose principalement de nœuds, de clusters et de centres de données. En plus de ceux-ci, il existe également d'autres composants. Cassandra est une base de données stockée en ligne. Il permet aux utilisateurs autorisés de se connecter à n'importe quel nœud dans n'importe quel centre de données à l'aide du CQL.
Structures clés à Cassandra
Ce sont les structures clés suivantes à Cassandra:
- Node - C'est là que les données sont stockées. C'est le composant le plus élémentaire de Cassandra. Il peut être considéré comme un serveur unique dans un rack. Il garantit qu'il n'y a pas de point de défaillance unique.
- Centre de données - Un centre de données est une collection de nœuds. Cela peut être physique ou virtuel. Selon la charge de travail, les centres de données sont divisés et choisis. Le facteur de réplication est décidé sur la base du centre de données. En fonction de ce facteur de réplication, les données peuvent être écrites dans différents centres de données.
- Cluster - Le cluster comprend un ou plusieurs centres de données. Les clusters s'étendent généralement sur différents emplacements physiques.
En plus de ceux-ci, les autres composants qui jouent un rôle dans Cassandra sont comme ci-dessous.
1. Journal de validation
Les données qui sont engagées pour maintenir la durabilité des données sont stockées dans le journal de validation. Les données sont déplacées vers une table de chaînes triée (expliqué ci-dessous). Une fois ce mouvement effectué, le journal de validation peut être archivé, supprimé ou recyclé.
2. Table SS
Cette table, comme mentionné au point précédent, stocke le journal ou les tables de mémoire à intervalles réguliers. Il s'agit d'un fichier de données immuable. Les tables SS peuvent stocker fréquemment des données de manière séquentielle. Ils ajoutent des données et conservent des informations pour chaque table Cassandra.
3. Table CQL
La table Cassandra Query est une collection de colonnes ordonnées qui peuvent extraire une ligne de cette table. Il y a des colonnes stockées dans cette table où les données peuvent être récupérées en utilisant la clé primaire.
4. Filtre Bloom
Il s'agit d'un type simple de cache où des algorithmes non déterministes sont stockés pour les tests. Il vérifie si un élément est membre de l'ensemble ou non. Ces filtres sont généralement accessibles après chaque requête exécutée.
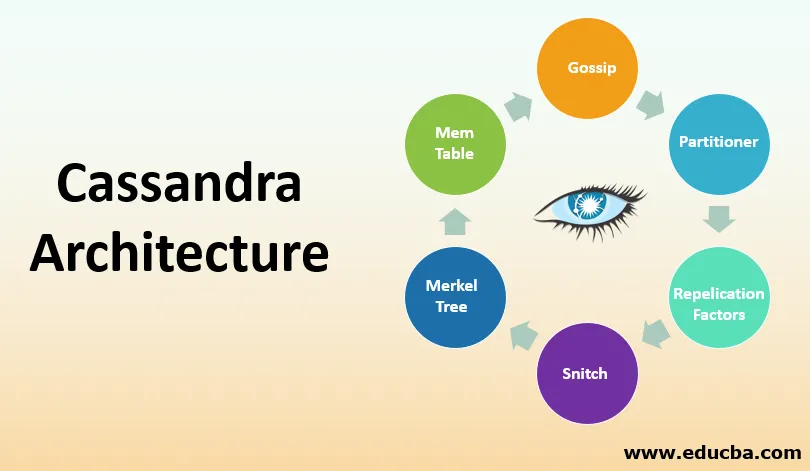
Composants clés pour configurer Cassandra
Cassandra contient les composants suivants:
1. Potins
- Comme son nom l'indique, il doit y avoir une communication entre pairs afin de découvrir et de partager l'emplacement et l'état des informations sur tous les nœuds.
- Ces informations doivent persister en local afin que chaque nœud puisse utiliser les informations dès qu'un nœud doit redémarrer. Les nœuds découvrent des informations sur d'autres nœuds en échangeant des informations.
- Cela peut être fait pour un maximum de trois nœuds. Les informations ne sont pas partagées avec tous les nœuds présents dans le cluster ou le centre de données. Les informations sont partagées avec quelques nœuds, mais finalement les informations d'état traversent tout le cluster.
2. Partitionneur
- Le partitionneur décide quel nœud doit recevoir la première réplique de toutes les données. Il est également responsable de la distribution de ces répliques.
- Il déterminera quel nœud doit avoir quelle réplication dans le cluster. Chaque ligne de données doit être identifiée de manière unique. Cela peut être fait en utilisant une clé primaire ou une clé de partition.
- Le partitionneur est une fonction de hachage qui permet d'obtenir un jeton à partir d'une clé primaire de n'importe quelle ligne. Chaque nœud possède une valeur num_token qui peut être définie comme partitionneur.
- La valeur de jeton générée permet de déterminer quel nœud reçoit la réplique des lignes.
3. Facteur de réplication
- Ce facteur détermine le nombre total de répliques présentes dans le cluster. Si le facteur de réplication est 1, il n'y a qu'une seule copie de chaque ligne sur un nœud.
- De même, si le facteur de réplication est de deux, deux copies seront conservées là où chaque copie est présente sur un nœud différent. Comme mentionné précédemment, il n'y a pas d'architecture maître-esclave dans Cassandra, chaque copie est importante.
- Le facteur de réplication est défini pour chaque centre de données. Ce facteur doit être supérieur à un mais pas supérieur au nombre de nœuds présents dans le cluster.
4. Vif d'or
- La stratégie de réplication qui permet d'obtenir l'emplacement où les répliques doivent être placées pour un groupe de machines dans le centre de données et le rack est connue sous le nom de Snitch.
- Il existe une couche dynamique qui facilite la surveillance et les performances et aide à choisir la meilleure réplique à partir de laquelle les données peuvent être lues. Les snitches doivent être configurés uniquement lors de la création d'un cluster.
- Il a des valeurs par défaut activées pour la plupart des déploiements. Les modifications de configuration peuvent être effectuées dans le fichier Cassandra.yml où le seuil de snitch dynamique pour chaque nœud est présent.
5. Merkle Tree
- Il peut y avoir des différences dans les blocs de données. Afin de trouver facilement les différences, l'arbre Merkle est un arbre de hachage qui aide à le faire.
- Les nœuds feuilles de l'arbre de hachage contiennent des hachages de blocs de données séparés et les nœuds parents ont les informations ou stockent également les hachages de leurs enfants.
- En utilisant cette technique, il est plus facile de trouver des différences entre les nœuds présents.
6. Tableau Mem
- Cette table contient des informations sur le cache dont les données ne sont pas encore vidées et résident dans la mémoire.
Conclusion
Cassandra est une base de données NoSQL qui est utile pour traiter d'énormes quantités de données. Il n'a pas une architecture maître-esclave typique et tous les nœuds sont donc également importants. Les nœuds ont des répliques à travers le cluster selon le facteur de réplication. Cela garantit la cohérence et la durabilité des données. Avec toutes ces fonctionnalités, il est clair que Cassandra est très utile pour les mégadonnées. Cassandra est donc durable, rapide car distribuée et fiable.
Articles recommandés
Ceci est un guide de l'architecture Cassandra. Nous discutons ici de l'introduction, de l'architecture Cassandra, de la structure des clés et des composants clés de Cassandra. Vous pouvez également consulter nos autres articles suggérés -
- Présentation de l'architecture Kubernetes
- Qu'est-ce que l'architecture Big Data?
- Fonctionnalités ajoutées à l'architecture AutoCAD
- Architecture informatique en nuage