

Qu'est-ce que la fonction ruche?
Comme nous le savons aujourd'hui, Hadoop est l'une des technologies polyvalentes du Big Data. Hadoop a la capacité de faire face à un grand ensemble de données, mais comme la croissance des données est proportionnelle, l'écriture de programmes de réduction de carte devient difficile. Pour effectuer des requêtes SQL, présente dans HDFS, une telle technologie a été introduite par Hadoop appelée apache Hive lancée par Facebook. Hive est très utilisé par l'analyste de données. Ils sont déployés pour trois fonctionnalités à savoir: la synthèse des données, l'analyse des données sur fichier distribué et la requête de données. Hive fournit des requêtes de type SQL appelées HQL - le langage de requête élevé prend en charge DML, les fonctions définies par l'utilisateur. Le compilateur Hive convertit en interne cette requête en travaux de réduction de carte, ce qui simplifie le travail de Hadoop dans l'écriture de programmes complexes. Nous pourrions trouver une ruche dans des applications comme l'entreposage de données, la visualisation de données et l'analyse ad hoc, Google Analytics. L'avantage principal est qu'ils utilisent les connaissances SQL, une compétence de base implémentée par les scientifiques des données et les professionnels des logiciels.
Différentes fonctions de ruche en détail
Hive prend en charge différents types de données qui ne se trouvent pas dans d'autres systèmes de base de données. il comprend une carte, un tableau et une structure. Hive a quelques fonctions intégrées pour effectuer plusieurs fonctions mathématiques et arithmétiques dans un but spécial. Les fonctions de la ruche peuvent être classées dans les types suivants. Ce sont des fonctions intégrées et des fonctions définies par l'utilisateur.
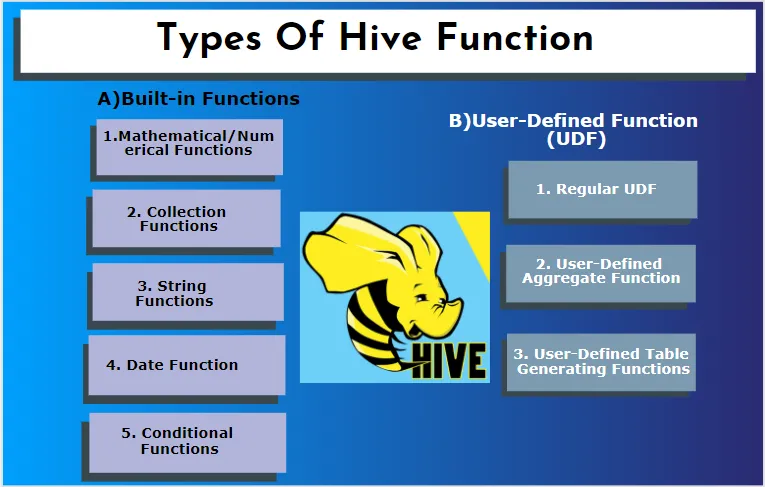
A) Fonctions intégrées
Ces fonctions extraient les données des tables de ruche et traitent les calculs. Certaines des fonctions intégrées sont:
1. Fonctions mathématiques / numériques
Ces fonctions sont principalement utilisées pour les calculs mathématiques. Ces fonctions sont utilisées dans les requêtes SQL.
| Nom de la fonction | Exemple | La description |
| ABS (double x) | Hive> sélectionnez ABS (-200) dans tmp; | Il renverra la valeur absolue d'un nombre. |
| CEIL (double x) | Hive> sélectionnez CEIL (8.5) dans tmp; | Il récupérera le plus petit entier supérieur ou égal à la valeur x. |
| Rand (), rand (int seed) | Hive> sélectionnez Rand () dans tmp;
Rand (0-9) | Il renvoie un nombre aléatoire, dépend de la valeur de départ, les nombres aléatoires générés seraient déterministes. |
| Pow (double x, double y) | Hive> sélectionnez Pow (5, 2) dans tmp; | Il renvoie la valeur x élevée à la puissance y. |
| ÉTAGE (double y) | Hive> sélectionnez FLOOR (11.8) dans tmp; | Il retourne un entier maximum inférieur ou égal pour donner la valeur y. |
| EXP (double a) | Hive> sélectionnez Exp (30) dans tmp; | Il renverra la valeur d'exposant de 30. les valeurs naturelles de l'algorithme. |
| PMOD (int a, int b) | Hive> sélectionnez PMOD (2, 4) dans tmp; | Il donne le module positif du nombre. |
2. Fonctions de collecte
Le vidage de tous les éléments et le renvoi d'éléments uniques dépendent du type de données inclus.
| Nom de la fonction | Exemple | La description |
| Map_values (Carte) | Hive> sélectionnez les valeurs de la carte ('hi', 45) | Il récupère les éléments de tableau non ordonnés. |
| Taille (carte) | Ruche> sélectionner la taille (carte) | Renvoie le nombre d'éléments dans la carte de type de données. |
| Array_contains (Array b) | Hive> select array_contains (a (10)) | Renvoie TRUE si le tableau contient la valeur. |
| Sort_array (Array a) | Hive> select sort_array ((10, 3, 6, 1, 7)) | Trie le tableau d'entrée par ordre croissant selon l'ordre naturel des éléments du tableau et renvoie la valeur. |
3. Fonctions de chaîne
L'utilisation des fonctions de chaîne permet d'analyser les données de manière optimale.
| Split (string s, string pat) | Hive> sélectionnez split ('educba ~ hive ~ Hadoop, ' ~ ') sortie: ("educba", "hive", "Hadoop") | Il divise la chaîne autour des expressions pat et renvoie un tableau. |
| load (string s, int Len, string pad) | Ruche> sélectionner la charge ('EDUCBA', 6, 'H') | Il renvoie des chaînes avec un remplissage à droite avec la longueur de la chaîne. (caractère pavé). |
| Longueur (chaîne str) | Ruche> sélectionner la longueur ('educba') | Cette fonction renvoie la longueur de la chaîne. |
| Rtrim (chaîne a) | Hive> sélectionnez rtrim ('TOPIC');
Sortie: «Sujet» | Il renvoie le résultat en réduisant les espaces à partir des extrémités droites. |
| Concat (chaîne m, chaîne n) | Hive> select concat ('data', 'ware') Résultat: Dataware | Il en résulte la chaîne en faisant la concaténation de deux chaînes, cela peut prendre n'importe quel nombre d'entrées. |
| Inverse (chaîne s) | Ruche> sélectionnez inverse ('Mobile') | Renvoie le résultat d'une chaîne inversée. |
4. Fonction de date
Il est nécessaire d'avoir un format de données dans la ruche pour éviter une erreur nulle dans la sortie. Il est nécessaire d'avoir une compatibilité de date pour aller avec les fonctions de date introduites par la ruche.
| Unix_timestamp (date de chaîne, modèle de chaîne) | Hive> sélectionnez l'horodatage Unix_ ('2019-06-08', 'yyyy-mm-dd'); Résultat: 124576 400 prise de temps: 0, 146 seconde | Cette fonction renvoie la date au format spécifique et renvoie les secondes entre la date et l'heure Unix. |
| Unix_timestamp (date de chaîne) | Hive> sélectionnez l'horodatage Unix_ ('2019-06-08 09:20:10', 'yyyy-mm-dd'); | Il renvoie la date au format 'aaaa-MM-jj HH: mm: ss' en horodatage Unix. |
| Heure (date de chaîne) | Ruche> sélectionnez l'heure ('2019-06-08 09:20:10'); Résultat: 09 heures | Il renvoie l'heure d'horodatage |
5. Fonctions conditionnelles
| If (test booléen, valeur T vrai, t faux) | Hive> sélectionnez IF (1 = 1, 'TRUE', 'FALSE') comme IF_CONDITION_TEST; | Il vérifie avec la condition si la valeur est true renvoie 1 et false renvoie 0. |
| N'est pas nul (b) | Hive> Select n'est pas null (null); | Cela récupère les instructions non nulles. si null renvoie false. |
| Coalesce (valeur1, valeur2) | Exemple: ruche> sélectionner fusion (Null, null, 4, null, 6). il renvoie 4. | Il récupère d'abord les valeurs non nulles de la liste de valeurs. |
B) Fonction définie par l'utilisateur (UDF)
Hive utilise des fonctions spécifiques à l'utilisateur selon les exigences du client, il est écrit en programmation java. Il est implémenté par deux interfaces à savoir l'API simple et l'API complexe. Ils sont invoqués à partir de la requête ruche. Trois types d'UDF:
1. UDF régulier
Il fonctionne sur une table avec une seule ligne. Il est créé en créant une classe java, puis en les empaquetant dans un fichier .jar, l'étape suivante consiste à vérifier avec un chemin de classe ruche. puis enfin les exécuter dans une requête ruche.
2. Fonction d'agrégation définie par l'utilisateur
Ils utilisent des fonctions d'agrégation comme avg / mean en implémentant cinq méthodes init (), iterate (), partial (), merge (), terminate ().
3. Fonctions de génération de tables définies par l'utilisateur
Il fonctionne avec une seule ligne dans un tableau et génère plusieurs lignes.
Conclusion
En conclusion, nous avons appris en détail à travailler dans la plate-forme ruche avec des fonctions intégrées et des fonctions définies par l'utilisateur grâce à cet article. La plupart des organisations ont un programmeur et un développeur SQL pour travailler sur le processus côté serveur, mais une ruche Apache est un outil puissant qui les aide à utiliser le framework Hadoop sans aucune connaissance préalable des programmes et de la réduction de carte. Hive aide les nouveaux utilisateurs à démarrer et à explorer l'analyse des données sans aucune barrière.
Articles recommandés
Ceci est un guide de la fonction ruche. Nous discutons ici du concept, de deux types différents de fonctions et sous-fonctions dans Hive. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Principales fonctions de chaîne dans Hive
- Questions d'entretiens chez Hive
- Qu'est-ce que RMAN Oracle?
- Qu'est-ce que le modèle Waterfall?
- Introduction à l'architecture ruche
- Ordre de ruche par