

Introduction à la déclaration de cas dans Tableau
L'instruction CASE ou la fonction CASE dans Tableau fait partie des fonctions logiques. Elle est similaire à l'instruction IF d'une manière qui continue à vérifier la condition une par une. Cependant, la différence entre les deux réside dans le fait qu'une déclaration CASE considère les conditions comme des cas et donc le nom. L'élément central de la fonction CASE est l'expression que la fonction doit évaluer. De plus, la fonction compare l'expression à une séquence de valeurs une par une. Lorsque l'expression correspond à une valeur, la valeur correspondante est renvoyée comme résultat.
Utilisation de l'instruction CASE - Une approche pas à pas
La syntaxe de la fonction CASE dans Tableau est la suivante.
CASE
WHEN THEN
WHEN THEN
WHEN THEN
ELSE
END
La syntaxe ci-dessus est la syntaxe standard et ici, le retour par défaut signifie une valeur qui devrait être retournée si aucune correspondance n'est trouvée. N'oubliez pas que les valeurs appropriées doivent être renvoyées, en fonction du contexte, en cas de non-correspondance.
Illustration
Nous allons maintenant montrer l'utilisation de la fonction CASE à travers une illustration. L'ensemble de données contient le volume de distribution par unités de distribution. Ici, les dimensions importantes sont la région et l'unité de distribution et le volume de distribution est une mesure. Notre objectif est de classer les unités de distribution en fonction du volume de distribution. Pour faciliter notre analyse, nous allons créer un champ unique qui combine les noms de régions et d'unités de distribution. Continuons avec les étapes.
- Chargez les données dans Tableau. Pour cela, cliquez sur «Nouvelle source de données» dans le menu Données ou cliquez sur «Se connecter aux données».
2. Dans «Connecter», sélectionnez le type de source de données requis. Dans ce cas, le type de source de données est Microsoft Excel.
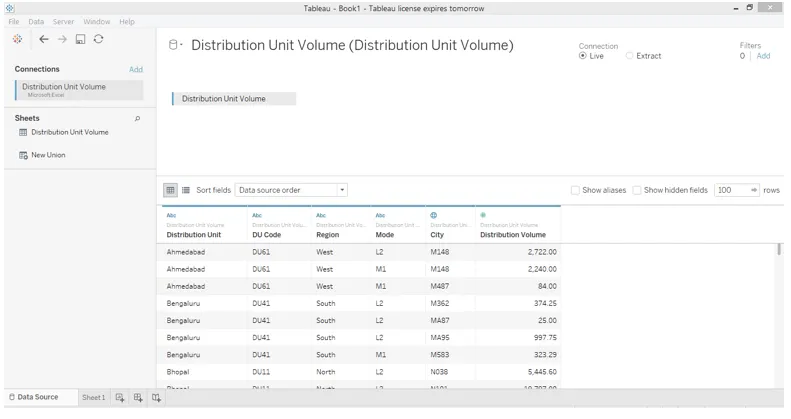
3. Les données sont chargées et peuvent être consultées dans l'onglet «Source de données» comme indiqué ci-dessous.
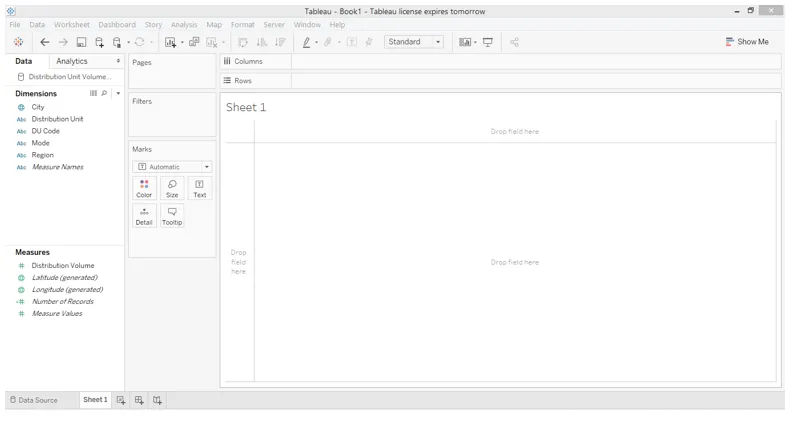
4. En passant à l'onglet de la feuille, nous pouvons trouver les dimensions et la mesure dans l'ensemble de données présent dans les sections respectives.
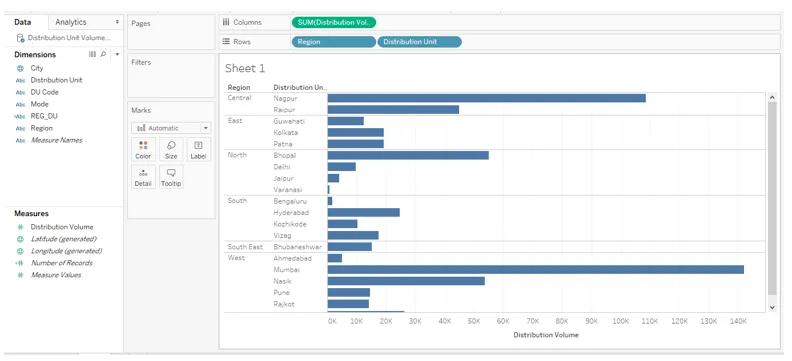
5. Pour commencer, faites simplement glisser les dimensions Région et Unités de distribution dans la région Lignes et mesurez le Volume de distribution dans la région Colonnes. Nous obtenons un graphique à barres horizontales comme on peut le voir dans la capture d'écran suivante. Si le type de graphique par défaut n'est pas un graphique à barres, sélectionnez-le dans Show Me. Les étapes suivantes créeront un champ combiné à l'aide de l'instruction CASE qui combinera les noms de région et d'unité de distribution.
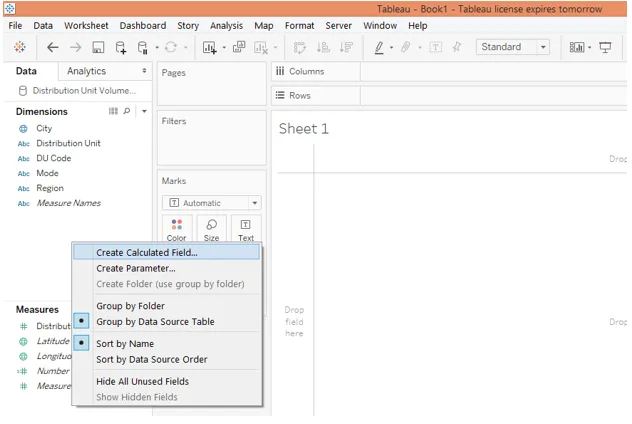
6. Pour créer un champ combiné, cliquez avec le bouton droit n'importe où dans l'espace vide de la section Données et cliquez sur l'option «Créer un champ calculé…» comme indiqué ci-dessous.
7. Le champ calculé que nous avons créé ressemble à la capture d'écran ci-dessous. Comme on peut le voir, le champ combiné a été créé à l'aide de la fonction CASE. Ici, l'expression utilisée est la dimension Région. En fonction du nom de la région, le champ combiné sera créé en combinant les trois premières lettres du nom de la région avec les trois premières lettres du nom de l'unité de distribution. Afin d'extraire les trois premières lettres de l'unité de distribution, nous avons utilisé la fonction LEFT. Toutes les lettres de l'unité de distribution ne sont pas en majuscules, donc pour les convertir en majuscules, nous avons passé le résultat à la fonction UPPER. La fonction CASE nous a donc proposé une approche systématique pour créer un champ combiné.

8. Le champ REG_DU nouvellement créé peut être vu dans la section Dimensions comme ci-dessous.
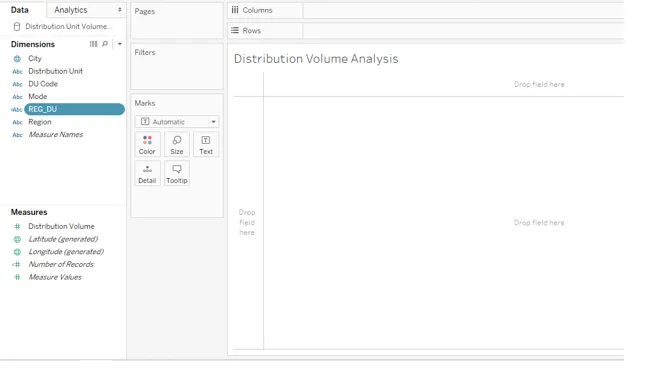
9. Maintenant, faites simplement glisser le champ nouvellement créé REG_DU dans la région des lignes et le volume de distribution dans la région des colonnes comme indiqué ci-dessous.
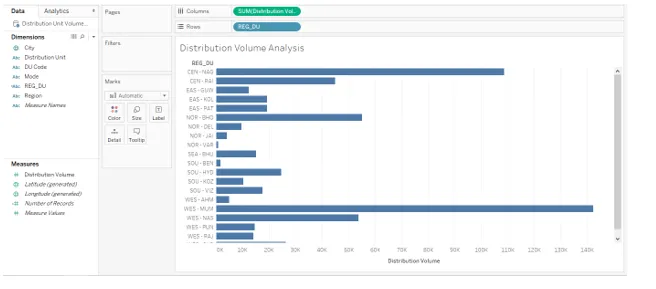
10. Examinons de plus près la visualisation. Nous pouvons voir les noms des régions et des unités de distribution combinées. Cela vous aidera à analyser rapidement et à capturer facilement les informations. Cependant, l'analyse est incomplète jusqu'à ce que nous classions les unités de distribution en fonction du volume de distribution. Pour atteindre l'objectif, nous suivrons les étapes illustrées par les captures d'écran suivantes à la suivante.
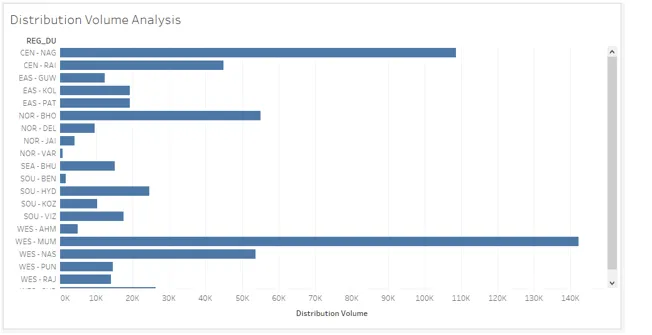
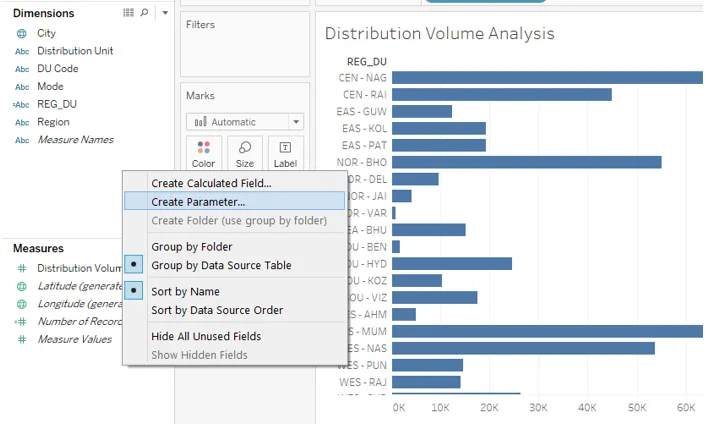
- Nous allons créer deux paramètres représentant le volume moyen et le volume élevé. Le volume moyen pour toutes les unités de distribution est de 30000 et nous considérons un volume élevé comme 90000. Pour créer un paramètre, cliquez avec le bouton droit n'importe où dans l'espace vide de la section Données et cliquez sur «Créer un paramètre…».
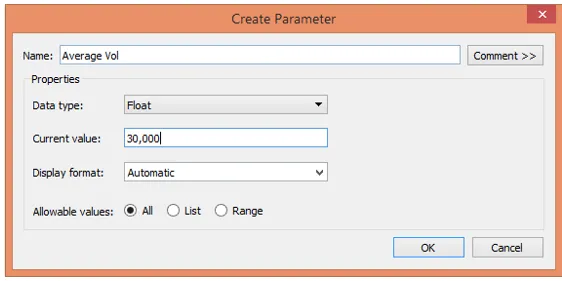
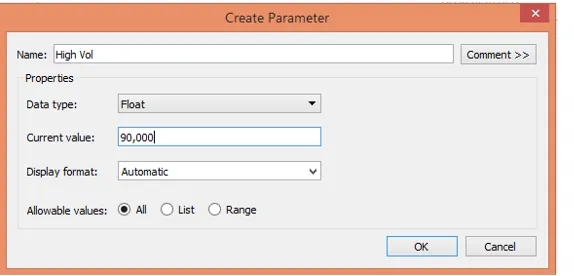
12. Créez les paramètres avec les noms appropriés et les valeurs mentionnées, comme illustré par les deux captures d'écran suivantes.
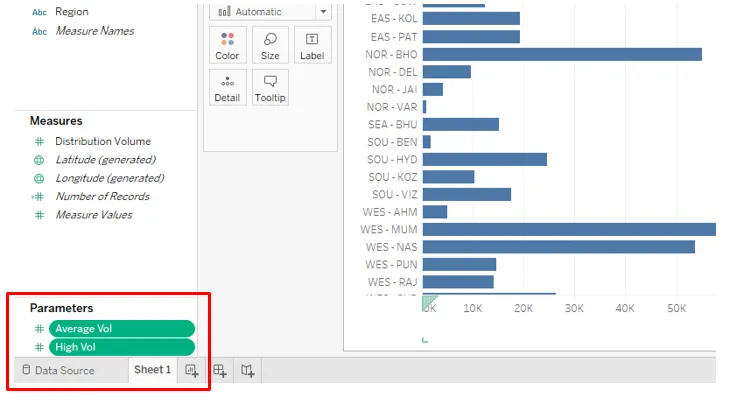
13. Les deux paramètres peuvent être vus dans la section «Paramètres» ci-dessous.
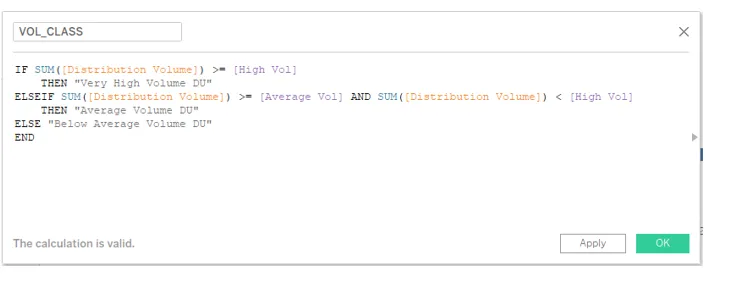
14. Ensuite, créez un champ calculé pour la classification. Nous l'avons nommé VOL_CLASS. En parcourant le code sur le terrain, on peut voir que les unités de distribution ayant un volume supérieur ou égal à 90000 ont été classées comme "DU très haut volume", celles dont le volume est compris entre 30000 et 90000 sont "DU moyen volume", et le reste correspond à des UD «inférieures à la moyenne».
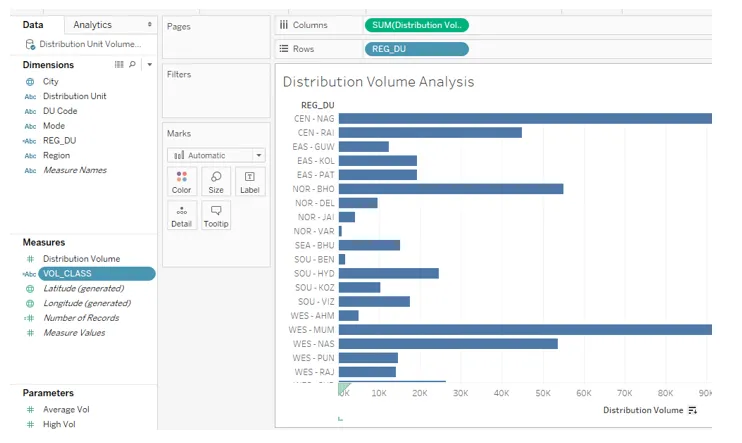
15. Le champ nouvellement créé peut être vu dans la section des mesures comme on peut le voir dans la capture d'écran ci-dessous. N'oubliez pas que ce champ utilise le volume de distribution des mesures et est donc automatiquement classé comme mesure.
16. Faites maintenant glisser le champ REG_DU dans la région Lignes et mesurez le volume de distribution dans la région Colonnes. Faites glisser le champ VOL_CLASS sur la carte Couleur dans les marques. Nous obtenons la visualisation suivante, où nous pouvons voir les unités de distribution classées dans différentes catégories de volume.
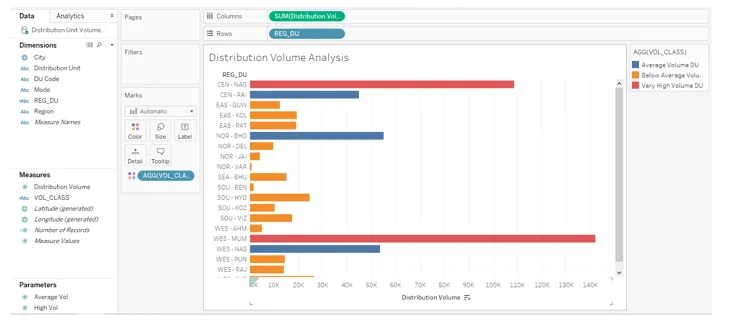
17. La capture d'écran suivante offre un examen plus approfondi de l'analyse. Ici, nous avons organisé la légende dans le bon ordre par rapport à ce qu'elle était dans la capture d'écran précédente. De plus, des couleurs appropriées ont été attribuées aux catégories, les résultats étant classés par ordre décroissant.
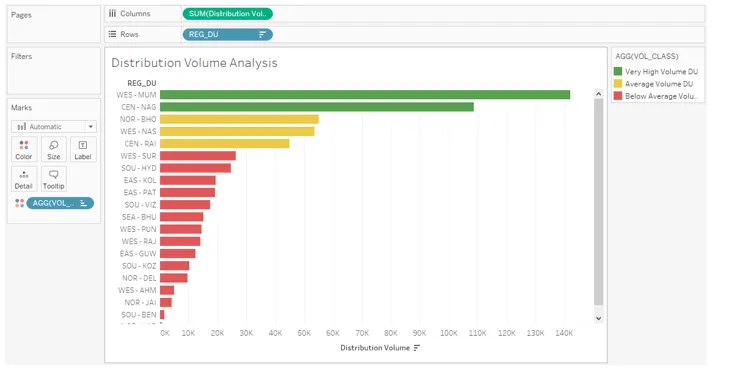
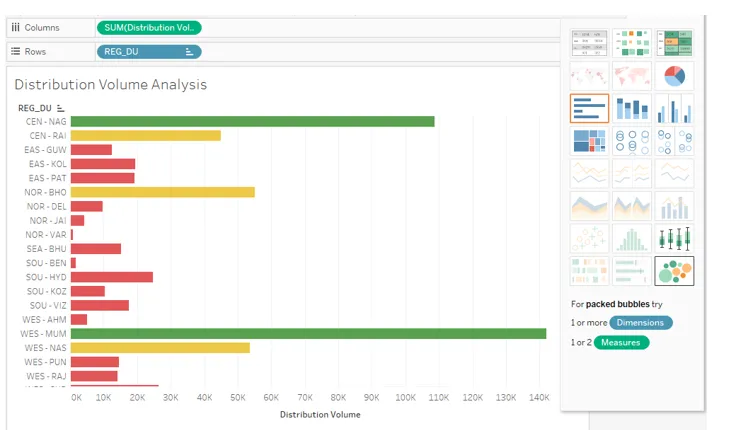
18. Tout en analysant la contribution en volume des unités de distribution, le graphique ci-dessus donne un bon aperçu. Cependant, un graphique à bulles est plus perspicace dans une telle analyse. Alors, ensuite, triez le résultat dans l'ordre alphabétique des noms REG_DU et cliquez sur «bulles emballées» dans Show Me comme on peut le voir ci-dessous.
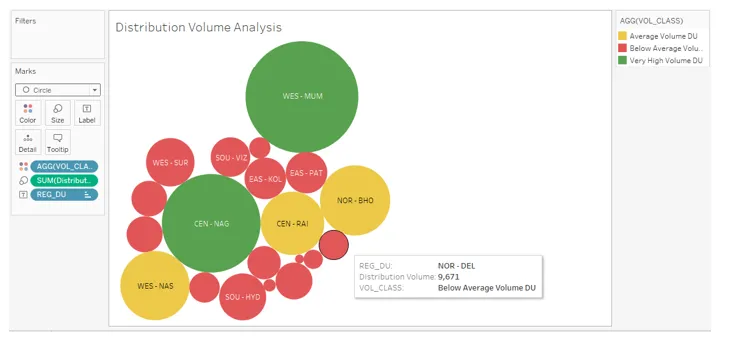
19. Comme on peut le voir ci-dessous, nous obtenons un graphique à bulles qui s'avère être le bon outil pour notre tâche car il représente les catégories par des combinaisons de couleurs et de tailles.
Conclusion - Déclaration de cas dans Tableau
Tableau étant un outil d'analyse visuelle typique, il utilise toutes les fonctionnalités pour proposer une analyse interactive et perspicace à travers des visualisations. La fonction CASE dans Tableau est utilisée pour gérer les situations conditionnelles dont le résultat obtenu est utilisé en fonction du contexte et affecte la sortie visuelle.
Articles recommandés
Ceci est un guide de la déclaration de cas dans Tableau. Nous discutons ici de l'introduction de l'instruction Case dans Tableau, Utilisation de l'instruction Case avec Illustration. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Avantages de la visualisation des données
- Visualisation de Tableau
- Fonction de classement dans Tableau
- Qu'est-ce que Tableau?
- Bases de données AWS
- Pivot dans Tableau
- Filtre de contexte Tableau
- Tableau à puces Tableau
- Introduction aux fonctionnalités et attributs de Tableau