
Présentation de la modélisation de régression linéaire
Lorsque vous commencez à vous familiariser avec les algorithmes d'apprentissage automatique, vous commencez à vous familiariser avec différentes méthodes d'algorithmes ML, à savoir l'apprentissage supervisé, non supervisé, semi-supervisé et par renforcement. Dans cet article, nous traiterons de l'apprentissage supervisé et de l'un des algorithmes de base mais puissants: la régression linéaire.

Par conséquent, l'apprentissage supervisé est l'apprentissage dans lequel nous formons la machine à comprendre la relation entre les valeurs d'entrée et de sortie fournies dans l'ensemble de données d'apprentissage, puis utilisons le même modèle pour prédire les valeurs de sortie pour l'ensemble de données de test. Donc, fondamentalement, si nous avons la sortie ou l'étiquetage déjà fournis dans notre ensemble de données de formation et que nous sommes sûrs que la sortie fournie a un sens correspondant à l'entrée, alors nous utilisons l'apprentissage supervisé. Les algorithmes d'apprentissage supervisé sont classés en régression et classification.
Les algorithmes de régression sont utilisés lorsque vous remarquez que la sortie est une variable continue tandis que les algorithmes de classification sont utilisés lorsque la sortie est divisée en sections telles que réussite / échec, bonne / moyenne / mauvaise, etc. Nous avons différents algorithmes pour effectuer la régression ou la classification actions avec l'algorithme de régression linéaire étant l'algorithme de base dans la régression.
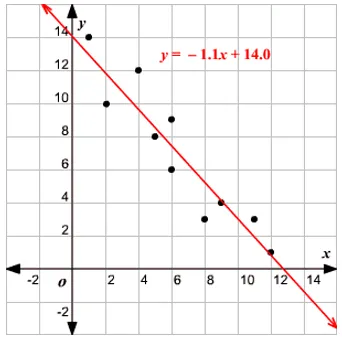
Venant à cette régression, avant d'entrer dans l'algorithme, permettez-moi de définir la base pour vous. À l'école, j'espère que vous vous souvenez du concept d'équation linéaire. Permettez-moi de vous en parler brièvement. On vous a donné deux points sur le plan XY, c'est-à-dire dire (x1, y1) et (x2, y2), où y1 est la sortie de x1 et y2 étant la sortie de x2, alors l'équation de ligne qui passe par les points est (y- y1) = m (x-x1) où m est la pente de la droite. Maintenant, après avoir trouvé l'équation de la ligne, si vous avez un point à dire (x3, y3), vous pourrez facilement prédire si le point se trouve sur la ligne ou la distance entre le point et la ligne. C'était la régression de base que j'avais faite en scolarité sans même réaliser que cela aurait une si grande importance dans le Machine Learning. Ce que nous faisons généralement dans ce cas, essayez d'identifier la ligne ou la courbe d'équation qui pourrait correspondre correctement à l'entrée et à la sortie de l'ensemble de données du train, puis utilisez la même équation pour prédire la valeur de sortie de l'ensemble de données de test. Il en résulterait une valeur souhaitée continue.
Définition de la régression linéaire
La régression linéaire existe depuis très longtemps (environ 200 ans). Il s'agit d'un modèle linéaire, c'est-à-dire qu'il suppose une relation linéaire entre les variables d'entrée (x) et une seule variable de sortie (y). Le y ici est calculé par la combinaison linéaire des variables d'entrée.
Nous avons deux types de régression linéaire
Régression linéaire simple
Lorsqu'il n'y a qu'une seule variable d'entrée, c'est-à-dire que l'équation de ligne est c
considéré comme y = mx + c, alors il s'agit de la régression linéaire simple.
Régression linéaire multiple
Lorsqu'il y a plusieurs variables d'entrée, c'est-à-dire que l'équation de ligne est considérée comme y = ax 1 + bx 2 +… nx n, alors c'est la régression linéaire multiple. Diverses techniques sont utilisées pour préparer ou entraîner l'équation de régression à partir de données et la plus courante d'entre elles est appelée les moindres carrés ordinaires. Le modèle construit à l'aide de la méthode mentionnée est appelé régression linéaire des moindres carrés ordinaires ou simplement régression des moindres carrés. Le modèle est utilisé lorsque les valeurs d'entrée et la valeur de sortie à déterminer sont des valeurs numériques. Lorsqu'il n'y a qu'une seule entrée et une seule sortie, l'équation formée est une équation linéaire
y = B0x+B1
où les coefficients de la ligne doivent être déterminés à l'aide de méthodes statistiques.
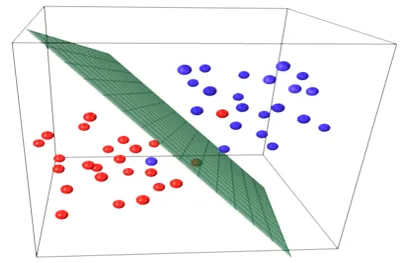
Les modèles de régression linéaire simple sont très rares en ML, car généralement, nous aurons divers facteurs d'entrée pour déterminer le résultat. Lorsqu'il y a plusieurs valeurs d'entrée et une valeur de sortie, l'équation formée est celle d'un plan ou d'un hyperplan.
y = ax 1 +bx 2 +…nx n
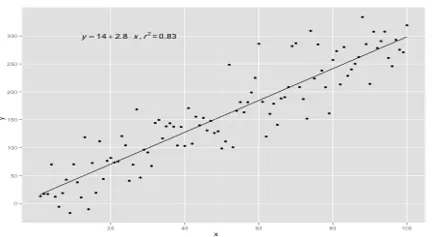
L'idée centrale du modèle de régression est d'obtenir une équation linéaire qui correspond le mieux aux données. La ligne la mieux ajustée est celle où l'erreur de prédiction totale pour tous les points de données est considérée aussi petite que possible. L'erreur est la distance entre le point de l'avion et la ligne de régression.
Exemple
Commençons par un exemple de régression linéaire simple.

La relation entre la taille et le poids d'une personne est directement proportionnelle. Une étude a été réalisée sur les volontaires pour déterminer la taille et le poids idéal de la personne et les valeurs ont été enregistrées. Cela sera considéré comme notre ensemble de données de formation. En utilisant les données d'apprentissage, une équation de ligne de régression est calculée, ce qui donnera une erreur minimale. Cette équation linéaire est ensuite utilisée pour faire des prédictions sur de nouvelles données. Autrement dit, si nous donnons la taille de la personne, alors le poids correspondant doit être prédit par le modèle développé par nous avec une erreur minimale ou nulle.
Y(pred) = b0 + b1*x
Les valeurs b0 et b1 doivent être choisies de manière à minimiser l'erreur. Si la somme des erreurs quadratiques est considérée comme une métrique pour évaluer le modèle, alors l'objectif est d'obtenir une ligne qui réduit le mieux l'erreur.
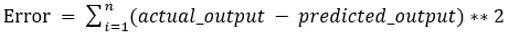
Nous corrigeons l'erreur afin que les valeurs positives et négatives ne s'annulent pas. Pour le modèle avec un prédicteur:
Le calcul de l'ordonnée à l'origine (b0) dans l'équation linéaire se fait par:
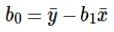
Le calcul du coefficient de la valeur d'entrée x se fait par:
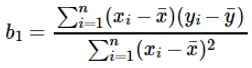
Comprendre le coefficient b 1 :
- Si b 1 > 0, alors x (entrée) et y (sortie) sont directement proportionnels. C'est-à-dire qu'une augmentation de x augmentera y comme des augmentations de taille, des augmentations de poids.
- Si b 1 <0, alors x (prédicteur) et y (cible) sont inversement proportionnels. C'est-à-dire qu'une augmentation de x diminuera y comme la vitesse d'une augmentation de véhicule, le temps est pris diminue.
Comprendre le coefficient b 0 :
- B 0 reprend la valeur résiduelle du modèle et garantit que la prédiction n'est pas biaisée. Si nous n'avons pas de terme B 0, alors l'équation de la ligne (y = B 1 x) est forcée de passer par l'origine, c'est-à-dire que les valeurs d'entrée et de sortie mises dans le modèle donnent 0. Mais ce ne sera jamais le cas si nous avons 0 en entrée, alors B 0 sera la moyenne de toutes les valeurs prédites lorsque x = 0. Définir toutes les valeurs du prédicteur à 0 dans le cas de x = 0 entraînera une perte de données et est souvent impossible.
Outre les coefficients mentionnés ci-dessus, ce modèle peut également être calculé à l'aide d'équations normales. Je discuterai davantage de l'utilisation des équations normales et de la conception d'un modèle de régression simple / multilinéaire dans mon prochain article.
Articles recommandés
Ceci est un guide de modélisation de régression linéaire. Ici, nous discutons de la définition, des types de régression linéaire qui comprend la régression linéaire simple et multiple avec quelques exemples. Vous pouvez également consulter les articles suivants pour en savoir plus–
- Régression linéaire en R
- Régression linéaire dans Excel
- Modélisation prédictive
- Comment créer GLM dans R?
- Comparaison de la régression linéaire et de la régression logistique