

Introduction à l'ANOVA en R
L'article suivant ANOVA dans R fournit un aperçu pour comparer la valeur moyenne de différents groupes. Une analyse de variance (ANOVA) est une technique très courante utilisée pour comparer la valeur moyenne de différents groupes. Le modèle ANOVA est utilisé pour les tests d'hypothèse, où certaines hypothèses ou paramètres sont générés pour une population et la méthode statistique est utilisée pour déterminer si l'hypothèse est vraie ou fausse.
L'hypothèse est dérivée de l'hypothèse de l'investigateur et des informations disponibles sur la population. L'ANOVA est appelée une analyse de la variance et utilisée pour les tests d'hypothèse où les moyennes d'une variable dans plusieurs groupes indépendants doivent être mesurées.
Par exemple, dans un laboratoire pour étudier ou inventer un nouveau médicament contre l'obésité, les chercheurs compareront le résultat d'un traitement expérimental et standard. Dans une étude sur l'obésité, des résultats précieux peuvent être obtenus lorsque le taux moyen d'obésité de la population peut être comparé dans différents groupes d'âge. Dans ce cas, on aimerait observer le taux moyen d'obésité parmi différents groupes d'âge tels que l'âge (5 à 18 ans), (19, 35 ans) et (36 à 50 ans). La méthode ANOVA est appliquée car il existe plus de deux groupes indépendants. La méthode ANOVA est utilisée pour comparer l'obésité moyenne des groupes indépendants. La fonction aov () est utilisée et la syntaxe est aov (formule, données = trame de données) Dans cet article, nous allons en apprendre davantage sur le modèle ANOVA et discuter plus en détail du modèle ANOVA unidirectionnel et bidirectionnel avec des exemples.
Pourquoi l'ANOVA?
- Cette technique est utilisée pour répondre à l'hypothèse lors de l'analyse de plusieurs groupes de données. Il existe plusieurs approches statistiques, cependant, l'ANOVA dans R est appliquée lorsque la comparaison doit être effectuée sur plus de deux groupes indépendants, comme dans notre exemple précédent, trois groupes d'âge différents.
- La technique ANOVA mesure la moyenne des groupes indépendants pour fournir aux chercheurs le résultat de l'hypothèse. Afin d'obtenir des résultats précis, les moyennes des échantillons, la taille de l'échantillon et l'écart type de chaque groupe individuel doivent être pris en compte.
- Il est possible d'observer la moyenne individuellement pour chacun des trois groupes à des fins de comparaison. Cependant, cette approche a des limites et peut s'avérer incorrecte car ces trois comparaisons ne prennent pas en compte les données totales et peuvent donc conduire à une erreur de type 1. R nous donne la fonction de mener l'analyse ANOVA pour examiner la variabilité parmi les groupes de données indépendants. L'analyse de l'ANOVA se déroule en cinq étapes. Dans la première étape, les données sont organisées au format csv et la colonne est générée pour chaque variable. L'une des colonnes serait une variable dépendante et les autres sont la variable indépendante. Dans la deuxième étape, les données sont lues dans R studio et nommées de manière appropriée. Dans la troisième étape, un ensemble de données est attaché à des variables individuelles et lu par la mémoire. Enfin, l'ANOVA dans R est définie et analysée. Dans les sections ci-dessous, j'ai fourni quelques exemples d'études de cas dans lesquels les techniques ANOVA doivent être utilisées.
- Six insecticides ont été testés sur 12 champs chacun, et les chercheurs ont compté le nombre de bogues qui restaient dans chaque champ. Maintenant, les agriculteurs doivent savoir si les insecticides font une différence et, dans l'affirmative, lequel utiliser le mieux. Vous répondez à cette question en utilisant la fonction aov () pour effectuer une ANOVA.
- Cinquante patients ont reçu l'un des cinq traitements médicamenteux réduisant le cholestérol (trt). Trois des conditions de traitement impliquaient le même médicament administré à 20 mg une fois par jour (1 fois) 10 mg deux fois par jour (2 fois) 5 mg quatre fois par jour (4 fois). Les deux conditions restantes (drugD et drugE) représentaient des médicaments concurrents. Quel traitement médicamenteux a produit la plus grande réduction (réponse) du cholestérol?
ANOVA à sens unique
- La méthode à sens unique est l'une des techniques de base de l'ANOVA dans laquelle l'analyse de la variance est appliquée et la valeur moyenne de plusieurs groupes de population est comparée.
- L'ANOVA unidirectionnelle tire son nom de la disponibilité de données classifiées unidirectionnelles. Dans une ANOVA unidirectionnelle, une variable dépendante unique et une ou plusieurs variables indépendantes peuvent être disponibles.
- Par exemple, nous effectuerons la technique ANOVA sur un ensemble de données sur le cholestérol. L'ensemble de données se compose de deux variables trt (qui sont des traitements à 5 niveaux différents) et des variables de réponse. Variable indépendante - groupes de traitement médicamenteux, variable dépendante - moyenne de 2 groupes ou plus ANOVA. À partir de ces résultats, vous pouvez confirmer que la prise de 5 mg 4 fois par jour était meilleure que la prise de 20 mg une fois par jour. Le médicament D a de meilleurs effets par rapport à ce médicament E
Le médicament D donne de meilleurs résultats s'il est pris à des doses de 20 mg par rapport au médicament E
Utilise le jeu de données sur le cholestérol dans le package multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Le test ANOVA F pour le traitement (trt) est significatif (p <.0001), ce qui prouve que les cinq traitements
# ne sont pas tous aussi efficaces.
résumé (aov_model)
détacher (cholestérol)

La fonction plotmeans () dans le package gplots peut être utilisée pour produire un graphique des moyennes de groupe et de leurs intervalles de confiance Cela montre clairement les différences de traitementinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
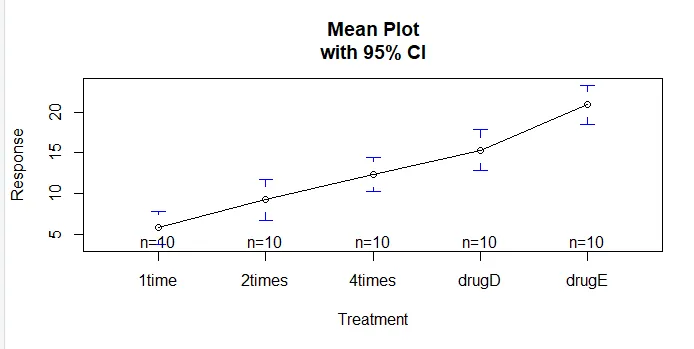
Examinons la sortie de TukeyHSD () pour les différences par paires entre les moyennes de groupe
TukeyHSD (aov_model)
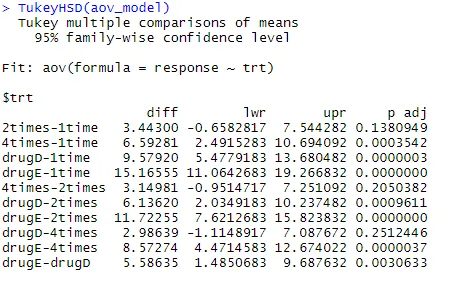
Les réductions moyennes de cholestérol pour 1 fois et 2 fois ne sont pas significativement différentes les unes des autres (p = 0, 138), tandis que la différence entre 1 fois et 4 fois est significativement différente (p <0, 001).
par (mar = c (5, 8, 4, 2)) # augmentation du tracé de la marge gauche (TukeyHSD (aov_model), las = 2)
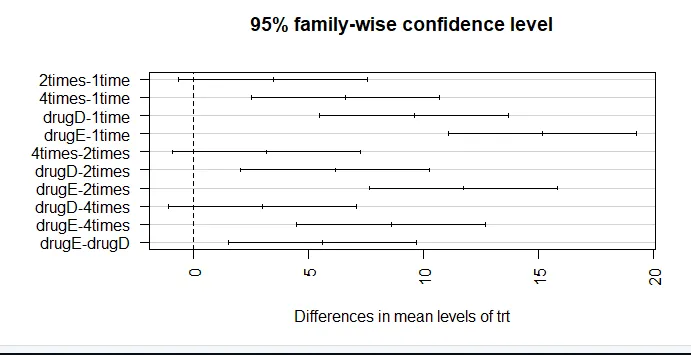
La confiance dans les résultats dépend du degré auquel vos données satisfont aux hypothèses sous-jacentes aux tests statistiques. Dans une ANOVA unidirectionnelle, la variable dépendante est supposée être distribuée normalement et présente une variance égale dans chaque groupe. Vous pouvez utiliser un tracé QQ pour évaluer la bibliothèque d'hypothèses de normalité (voiture).
Graphique QQ (lm (réponse ~ trt, données = cholestérol), simuler = VRAI, principal = "Graphique QQ", étiquettes = FAUX)
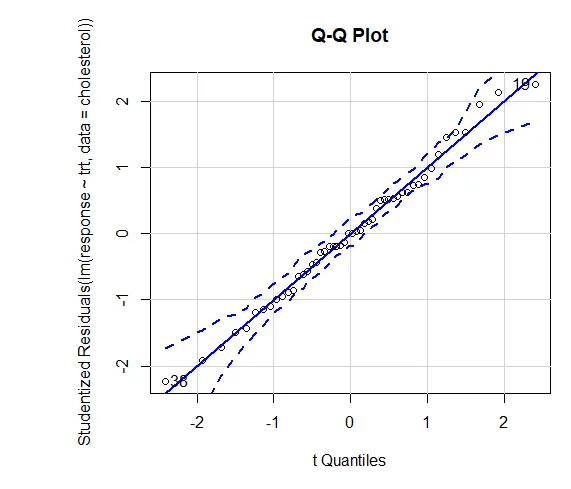
Ligne pointillée = enveloppe de confiance à 95%, ce qui suggère que l'hypothèse de normalité a été assez bien respectée L'ANOVA suppose que les variances sont égales entre les groupes ou les échantillons. Le test de Bartlett peut être utilisé pour vérifier cette hypothèse
bartlett.test (réponse ~ trt, données = cholestérol). Le test de Bartlett indique que les variances dans les cinq groupes ne diffèrent pas significativement (p = 0, 97).
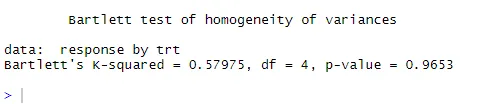
L'ANOVA est également sensible au test des valeurs aberrantes à l'aide de la fonction outlierTest () dans le package de voiture. Vous n'aurez peut-être pas besoin d'exécuter ce package pour mettre à jour votre bibliothèque de voitures.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
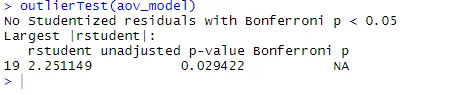
De la sortie, vous pouvez voir qu'il n'y a aucune indication de valeurs aberrantes dans les données de cholestérol (NA se produit lorsque p> 1). En prenant ensemble le tracé QQ, le test de Bartlett et le test aberrant, les données semblent assez bien correspondre au modèle ANOVA.
Anova bidirectionnel
Une autre variable est ajoutée dans le test ANOVA bidirectionnel. Lorsqu'il y a deux variables indépendantes, nous devrons utiliser l'ANOVA bidirectionnelle plutôt que la technique d'ANOVA unidirectionnelle qui était utilisée dans le cas précédent où nous avions une variable dépendante continue et plus d'une variable indépendante. Afin de vérifier l'ANOVA bidirectionnelle, plusieurs hypothèses doivent être satisfaites.
- Disponibilité d'observations indépendantes
- Les observations doivent être normalement distribuées
- La variance doit être égale dans les observations
- Les valeurs aberrantes ne devraient pas être présentes
- Erreurs indépendantes
Pour vérifier l'ANOVA bidirectionnelle, une autre variable appelée BP est ajoutée à l'ensemble de données. La variable indique le taux de pression artérielle chez les patients. Nous aimerions vérifier s'il existe une différence statistique entre la PA et la dose administrée aux patients.
df <- read.csv ("fichier.csv")
df
anova_two_way <- aov (réponse ~ trt + BP, data = df)
résumé (anova_two_way)
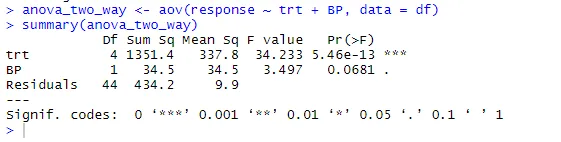
De la sortie, on peut conclure que trt et BP sont statistiquement différents de 0. Par conséquent, l'hypothèse Null peut être rejetée.
Avantages de l'ANOVA dans R
Le test ANOVA détermine la différence de moyenne entre deux ou plusieurs groupes indépendants. Cette technique est très utile pour l'analyse de plusieurs articles qui est essentielle pour l'analyse du marché. En utilisant le test ANOVA, on peut obtenir les informations nécessaires à partir des données. Par exemple, lors d'une enquête sur un produit où plusieurs informations telles que les listes de courses, les goûts des clients et les aversions sont collectées auprès des utilisateurs. Le test ANOVA nous aide à comparer des groupes de population. Le groupe peut être masculin ou féminin ou divers groupes d'âge. La technique ANOVA permet de distinguer les valeurs moyennes des différents groupes de la population qui sont en effet différentes.
Conclusion - ANOVA en R
L'ANOVA est l'une des méthodes les plus couramment utilisées pour tester les hypothèses. Dans cet article, nous avons effectué un test ANOVA sur l'ensemble de données composé de cinquante patients qui ont reçu un traitement médicamenteux réduisant le cholestérol et avons en outre vu comment l'ANOVA bidirectionnelle peut être effectuée lorsqu'une variable indépendante supplémentaire est disponible.
Articles recommandés
Ceci est un guide de l'ANOVA dans R. Ici, nous discutons du modèle Anova unidirectionnel et bidirectionnel ainsi que des exemples et des avantages de l'ANOVA. Vous pouvez également consulter nos autres articles suggérés -
- Régression vs ANOVA
- Qu'est-ce que SPSS?
- Comment interpréter les résultats à l'aide du test ANOVA
- Fonctions dans R