
 Différences entre l'apprentissage supervisé et l'apprentissage en profondeur
Différences entre l'apprentissage supervisé et l'apprentissage en profondeur
Dans l'apprentissage supervisé, les données de formation que vous fournissez à l'algorithme incluent les solutions souhaitées, appelées étiquettes. Une tâche d'apprentissage supervisé typique est la classification. Le filtre anti-spam en est un bon exemple: il est formé avec de nombreux exemples d'e-mails avec leur classe (spam ou jambon), et il doit apprendre à classer les nouveaux e-mails.
L'apprentissage en profondeur est une tentative d'imiter l'activité dans les couches de neurones du néocortex, qui représente environ 80% du cerveau où se produit la réflexion (dans un cerveau humain, il y a environ 100 milliards de neurones et 100 à 1000 trillions de synapses). Il est appelé profond parce qu'il a plus d'une couche de neurones cachés qui aident à avoir plusieurs états de transformation de caractéristiques non linéaires
Comparaison directe de l'apprentissage supervisé et de l'apprentissage profond (infographie)
Ci-dessous se trouve le top 5 de la comparaison entre l'apprentissage supervisé et l'apprentissage profond 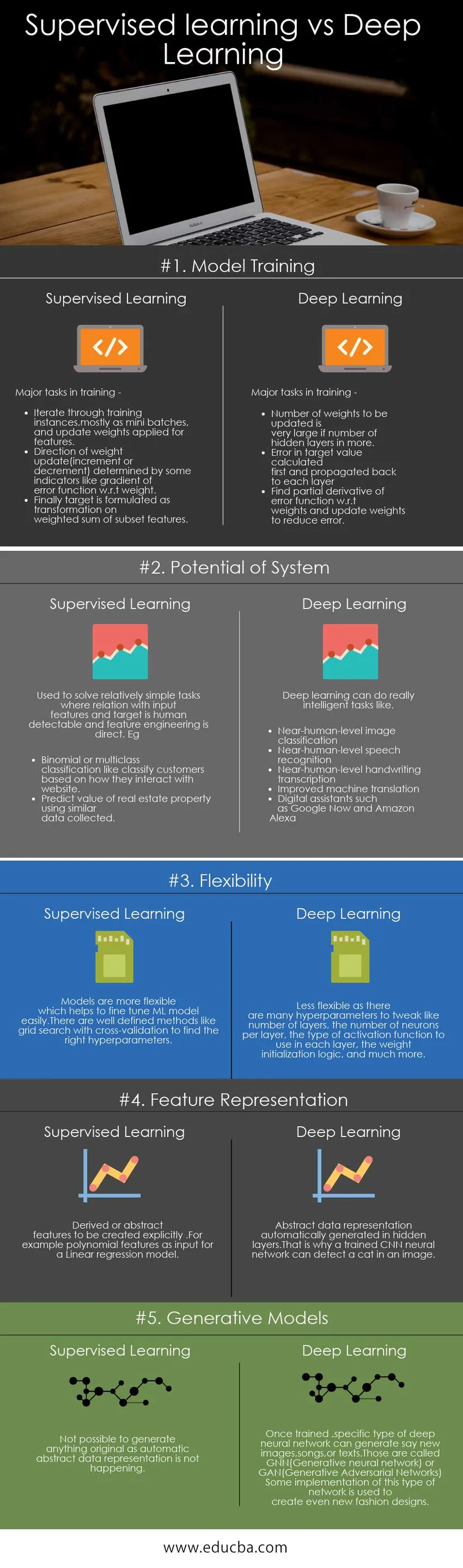
Différences clés entre l'apprentissage supervisé et l'apprentissage profond
L'apprentissage supervisé et l'apprentissage en profondeur sont des choix populaires sur le marché; laissez-nous discuter de certaines des principales différences entre l'apprentissage supervisé et l'apprentissage en profondeur:
● Modèles majeurs -
Les modèles supervisés importants sont -
○ k-voisins les plus proches - utilisé pour la classification et la régression
○ Régression linéaire - Pour la prédiction / régression
○ Régression logistique - Pour la classification
○ Machines à vecteurs de support (SVM) - Utilisées pour la classification et la régression
○ Arbres de décision et forêts aléatoires - Tâches de classification et de régression
Réseaux de neurones profonds les plus populaires:
● Perceptrons multicouches (MLP) - Type le plus basique. Ce réseau est généralement la phase de démarrage de la construction d'un autre réseau profond plus sophistiqué et peut être utilisé pour tout problème de régression ou de classification supervisé
● Autoencoders (AE) - Le réseau dispose d'algorithmes d'apprentissage non supervisés pour l'apprentissage des fonctionnalités, la réduction des dimensions et la détection des valeurs aberrantes
● Réseau neuronal à convolution (CNN) - particulièrement adapté pour les données spatiales, la reconnaissance d'objets et l'analyse d'images à l'aide de structures neuronales multidimensionnelles. L'une des principales raisons de la popularité de l'apprentissage en profondeur ces derniers temps est due à CNN.
● Réseau neuronal récurrent (RNN) - Les RNN sont utilisés pour l'analyse de données séquencées telles que les séries chronologiques, l'analyse des sentiments, la PNL, la traduction de la langue, la reconnaissance vocale, le sous-titrage d'images. L'un des types les plus courants de modèle RNN est le réseau à mémoire à court terme long (LSTM).
● Données de formation - Comme mentionné précédemment, les modèles supervisés ont besoin de données de formation avec des étiquettes. Mais le Deep Learning peut gérer des données avec ou sans étiquettes. Certaines architectures de réseaux de neurones peuvent être non supervisées, comme les auto-encodeurs et les machines Boltzmann restreintes
● Sélection des fonctionnalités - Certains modèles supervisés sont capables d'analyser des fonctionnalités et un sous-ensemble sélectionné de fonctionnalités pour déterminer la cible. Mais la plupart du temps, cela doit être traité dans la phase de préparation des données. Mais dans les réseaux de neurones profonds, de nouvelles fonctionnalités sont apparues et les fonctionnalités indésirables sont supprimées au fur et à mesure de l'apprentissage.
● Représentation des données - Dans les modèles supervisés classiques, l'abstraction de haut niveau des entités en entrée n'est pas créée. Modèle final essayant de prédire la sortie en appliquant des transformations mathématiques sur un sous-ensemble d'entités en entrée.
Mais dans les réseaux de neurones profonds, des abstractions de caractéristiques d'entrée se forment en interne. Par exemple, lors de la traduction de texte, le réseau neuronal convertit d'abord le texte d'entrée en codage interne, puis transforme cette représentation abstraite en langue cible.
● Framework - Les modèles ML supervisés sont pris en charge par de nombreux frameworks ML génériques dans différents langages - Apache Mahout, Scikit Learn, Spark ML en sont quelques-uns.
Les frameworks Majority Deep Learning fournissent une abstraction conviviale pour les développeurs pour créer facilement un réseau, prendre en charge la distribution des calculs et prendre en charge les GPU.Caffe, Caffe2, Theano, Torch, Keras, CNTK, TensorFlow sont des frameworks populaires. maintenant avec un soutien communautaire actif.
Tableau comparatif apprentissage supervisé vs apprentissage profond
Vous trouverez ci-dessous une comparaison clé entre l'apprentissage supervisé et l'apprentissage profond
| La base de la comparaison entre l'apprentissage supervisé et l'apprentissage profond | Enseignement supervisé | L'apprentissage en profondeur |
| Formation de modèle | Tâches principales en formation -
| Tâches principales en formation -
|
| Potentiel du système | Utilisé pour résoudre des tâches relativement simples où la relation avec les entités en entrée et la cible est détectable par l'homme et l'ingénierie des entités est directe. Par exemple :
| L'apprentissage en profondeur peut accomplir des tâches vraiment intelligentes comme
|
| La flexibilité | Les modèles sont plus flexibles, ce qui permet d'affiner facilement le modèle ML. Il existe des méthodes bien définies comme la recherche dans la grille avec validation croisée pour trouver les bons paramètres | Moins flexible car il existe de nombreux hyperparamètres à modifier comme un certain nombre de couches, le nombre de neurones par couche, le type de fonction d'activation à utiliser dans chaque couche, la logique d'initialisation du poids, et bien plus encore. |
| Représentation des caractéristiques | Fonctionnalités dérivées ou abstraites à créer explicitement. Par exemple, des entités polynomiales comme entrée pour un modèle de régression linéaire | Représentation abstraite des données générée automatiquement dans les couches cachées. C'est pourquoi un réseau neuronal CNN formé peut détecter un chat dans une image. |
| Modèles génératifs | Impossible de générer quelque chose d'original car la représentation automatique des données abstraites ne se produit pas | Une fois formé, un type spécifique de réseau neuronal profond peut générer, par exemple, de nouvelles images, chansons ou textes. Ceux-ci sont appelés GNN (Generative Neural Network) ou GAN (Generative Adversarial Networks)
Une certaine mise en œuvre de ce type de réseau est utilisée pour créer même de nouveaux modèles de mode |
Conclusion - Apprentissage supervisé vs apprentissage en profondeur
La précision et la capacité des DNN (Deep Neural Network) ont beaucoup augmenté au cours des dernières années. C'est pourquoi les DNN sont désormais un domaine de recherche active et, selon nous, il a le potentiel de développer un système intelligent général. Dans le même temps, il est difficile de comprendre pourquoi un DNN donne une sortie particulière, ce qui rend le réglage fin d'un réseau vraiment difficile. Donc, si un problème peut être résolu à l'aide de modèles ML simples, il est fortement recommandé de l'utiliser. De ce fait, une régression linéaire simple sera pertinente même si un système intelligent général est développé à l'aide de DNN.
Article recommandé
Cela a été un guide pour les principales différences entre l'apprentissage supervisé et l'apprentissage profond. Ici, nous discutons également des principales différences entre l'apprentissage supervisé et l'apprentissage profond avec des infographies et un tableau de comparaison. Vous pouvez également consulter les articles suivants -
- Apprentissage supervisé vs apprentissage par renforcement
- Apprentissage supervisé vs apprentissage non supervisé
- Réseaux de neurones vs apprentissage en profondeur
- Apprentissage automatique vs analyse prédictive
- TensorFlow vs Caffe: Quelles sont les différences
- Qu'est-ce que l'apprentissage supervisé?
- Qu'est-ce que l'apprentissage par renforcement?
- Top 6 des comparaisons entre CNN et RNN