

Introduction à AWS EMR
AWS EMR fournit de nombreuses fonctionnalités qui nous facilitent la tâche, certaines des technologies sont:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
L'un des principaux services fournis par AWS EMR et nous allons traiter est Amazon EMR.
EMR, communément appelé Elastic Map Reduce, propose un moyen simple et accessible de traiter le traitement de blocs de données plus volumineux. Imaginez un scénario de Big Data où nous avons une énorme quantité de données et nous effectuons un ensemble d'opérations sur eux, par exemple un travail Map-Reduce est en cours d'exécution, l'un des problèmes majeurs auxquels l'application Bigdata est confrontée est le réglage du programme, nous ont souvent du mal à affiner notre programme de manière à ce que toutes les ressources allouées soient consommées correctement. En raison de ce facteur de réglage ci-dessus, le temps de traitement augmente progressivement. Elastic Map Reduce the service by Amazon, est un service Web qui fournit un cadre qui gère toutes ces fonctionnalités nécessaires au traitement du Big Data de manière rentable, rapide et sécurisée. De la création de cluster à la distribution de données sur diverses instances, toutes ces choses sont facilement gérées sous Amazon EMR. Les services ici sont à la demande, ce qui signifie que nous pouvons contrôler les chiffres en fonction des données dont nous disposons, qui sont rentables et évolutives.
Raisons d'utiliser AWS EMR
Alors pourquoi utiliser AMR ce qui le rend meilleur des autres. Nous rencontrons souvent un problème très basique où nous ne sommes pas en mesure d'allouer toutes les ressources disponibles sur le cluster à une application, AMAZON EMR s'occupant de ces problèmes et en fonction de la taille des données et de la demande de l'application, il alloue la ressource nécessaire. De plus, étant de nature élastique, nous pouvons le changer en conséquence. EMR a un support d'application énorme, que ce soit Hadoop, Spark, HBase qui facilite le traitement des données. Il prend en charge diverses opérations ETL rapidement et à moindre coût. Il peut également être utilisé pour MLIB dans Spark. Nous pouvons y exécuter divers algorithmes d'apprentissage automatique. Qu'il s'agisse de données par lots ou de streaming de données en temps réel, EMR est capable d'organiser et de traiter les deux types de données.
Fonctionnement d'AWS EMR
Voyons maintenant ce schéma du cluster Amazon EMR et essayons de comprendre comment cela fonctionne réellement:
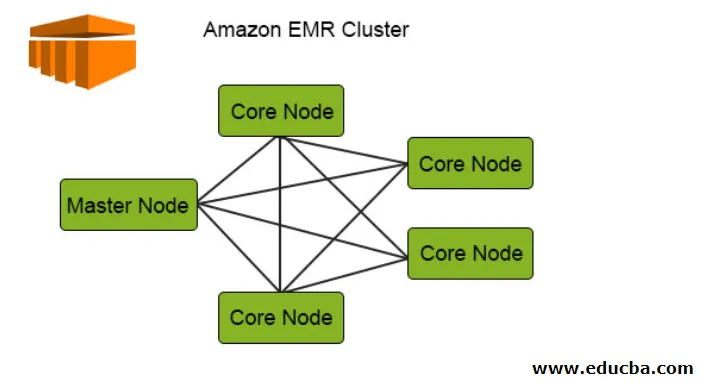
Le diagramme suivant illustre la distribution des clusters à l'intérieur du DME. Vérifions cela plus en détail:
1. Les clusters sont le composant central de l'architecture Amazon EMR. Il s'agit d'une collection d'instances EC2 appelées nœuds. Chaque nœud a ses rôles spécifiques au sein du cluster appelés type de nœud et en fonction de leurs rôles, nous pouvons les classer en 3 types:
- Noeud maître
- Nœud central
- Noeud de tâche
2. Le nœud maître, comme son nom l'indique, est le maître qui est responsable de la gestion du cluster, de l'exécution des composants et de la distribution des données sur les nœuds pour le traitement. Il garde juste une trace si tout est correctement géré et fonctionne correctement et fonctionne en cas d'échec.
3. Le nœud principal a la responsabilité d'exécuter la tâche et de stocker les données dans HDFS dans le cluster. Toutes les parties de traitement sont gérées par le nœud principal et les données après ce traitement sont placées à l'emplacement HDFS souhaité.
4. Le nœud de tâche étant facultatif n'a que le travail pour exécuter la tâche qui ne stocke pas les données dans HDFS.
5. Chaque fois qu'après avoir soumis un travail, nous avons plusieurs méthodes pour choisir la façon dont les travaux doivent être achevés. Que ce soit de la fin du cluster après la fin du travail à un cluster de longue durée à l'aide de la console EMR et de la CLI pour soumettre les étapes, nous avons tous les privilèges pour le faire.
6. Nous pouvons exécuter directement le travail sur l'EMR en le connectant au nœud maître via les interfaces et les outils disponibles qui exécutent les travaux directement sur le cluster.
7. Nous pouvons également exécuter nos données en plusieurs étapes avec l'aide d'EMR, tout ce que nous avons à faire est de soumettre une ou plusieurs étapes ordonnées dans le cluster EMR. Les données sont stockées sous forme de fichier et traitées de manière séquentielle. En partant de «l'état en attente vers l'état terminé», nous pouvons retracer les étapes de traitement et trouver les erreurs également dans «Échec de l'annulation», toutes ces étapes peuvent être facilement retracées.
8. Une fois que toute l'instance est terminée, l'état terminé du cluster est atteint.
Architecture pour AWS EMR
L'architecture d'EMR se présente à partir de la partie stockage vers la partie Application.
- La toute première couche est livrée avec la couche de stockage qui comprend différents systèmes de fichiers utilisés avec notre cluster. Que ce soit de HDFS à EMRFS au système de fichiers local, tous ces éléments sont utilisés pour le stockage de données sur l'ensemble de l'application. La mise en cache des résultats intermédiaires pendant le traitement MapReduce peut être réalisée à l'aide de ces technologies fournies avec EMR.
- La deuxième couche est fournie avec la gestion des ressources pour le cluster, cette couche est responsable de la gestion des ressources pour les clusters et les nœuds sur l'application. Cela aide essentiellement en tant qu'outils de gestion qui aident à répartir uniformément les données sur le cluster et à les gérer correctement. L'outil de gestion des ressources par défaut qu'EMR utilise est YARN qui a été introduit dans Apache Hadoop 2.0. Il gère de manière centralisée les ressources de plusieurs infrastructures de traitement de données. Il prend en charge toutes les informations nécessaires au bon fonctionnement du cluster, que ce soit de l'intégrité du nœud à la distribution des ressources avec la gestion de la mémoire.
- La troisième couche est livrée avec le Data Processing Framework, cette couche est responsable de l'analyse et du traitement des données. il existe de nombreux cadres pris en charge par EMR qui jouent un rôle important dans le traitement parallèle et efficace des données. APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- La quatrième couche est associée à l'application et à des programmes tels que HIVE, PIG, bibliothèque de diffusion en continu, algorithmes ML qui sont utiles pour le traitement et la gestion de grands ensembles de données.
Avantages d'AWS EMR
Voyons maintenant certains des avantages de l'utilisation du DME:
- Haute vitesse: Étant donné que toutes les ressources sont utilisées correctement, le temps de traitement de la requête est relativement plus rapide que les autres outils de traitement des données ont une image beaucoup plus claire.
- Traitement de données en masse: être plus grand que la taille des données EMR a la capacité de traiter une énorme quantité de données en un temps suffisant.
- Perte de données minimale: étant donné que les données sont distribuées sur le cluster et traitées parallèlement sur le réseau, il y a un risque minimum de perte de données et bien, le taux de précision des données traitées est meilleur.
- Rentable: Étant rentable, il est moins cher que toute autre alternative disponible qui le rend solide par rapport à l'utilisation dans l'industrie. Étant donné que le prix est moins élevé, nous pouvons gérer de grandes quantités de données et les traiter dans le cadre du budget.
- AWS Integrated: Il est intégré à tous les services d'AWS, ce qui facilite la disponibilité sous un même toit, de sorte que la sécurité, le stockage et la mise en réseau sont intégrés en un seul endroit.
- Sécurité: il est livré avec un groupe de sécurité incroyable pour contrôler le trafic entrant et sortant.L'utilisation des rôles IAM le rend plus sécurisé car il propose diverses autorisations qui sécurisent les données.
- Surveillance et déploiement: nous avons des outils de surveillance appropriés pour toutes les applications qui s'exécutent sur des clusters EMR, ce qui la rend transparente et facile à analyser.Elle comprend également une fonction de déploiement automatique dans laquelle l'application est configurée et déployée automatiquement.
Il y a beaucoup plus d'avantages à avoir l'EMR comme meilleur choix pour une autre méthode de calcul de cluster.
Prix AWS EMR
EMR est livré avec une liste de prix incroyable qui attire les développeurs ou le marché. Puisqu'il est livré avec une fonctionnalité de tarification à la demande, nous pouvons l'utiliser un peu plus d'une heure et d'un nombre de nœuds dans notre cluster. Nous pouvons payer un taux par seconde pour chaque seconde que nous utilisons avec une minute au minimum. Nous pouvons également choisir nos instances à utiliser en tant qu'instances réservées ou instances ponctuelles, le spot étant très économique.
Nous pouvons calculer la facture totale sur une simple calculatrice mensuelle à partir du lien ci-dessous: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Pour plus de détails sur les prix exacts, vous pouvez consulter le document ci-dessous d'Amazon: -
https://aws.amazon.com/emr/pricing/
Conclusion
À partir de l'article ci-dessus, nous avons vu comment EMR peut être utilisé pour le traitement équitable des mégadonnées avec toutes les ressources utilisées de manière conventionnelle.
Avoir EMR résout notre problème de base de traitement des données et réduit beaucoup le temps de traitement par un bon nombre, étant rentable, il est facile et pratique à utiliser.
Article recommandé
Cela a été un guide pour AWS EMR. Nous discutons ici d'une introduction à AWS EMR tout au long de son fonctionnement et de son architecture ainsi que des avantages. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Alternatives à AWS
- Commandes AWS
- Services AWS
- Questions d'entretiens chez AWS
- Services de stockage AWS
- Les 7 meilleurs concurrents d'AWS
- Liste des fonctionnalités d'Amazon Web Services