
Introduction à l'architecture ruche
L'architecture Hive est construite au-dessus de l'écosystème Hadoop. La ruche a fréquemment des interactions avec le Hadoop. Apache Hive gère à la fois le système de base de données SQL du domaine et Map-Reduce. Les applications Hive peuvent être écrites dans différents langages comme Java, python. L'architecture de la ruche montre comment écrire le langage de requête de ruche et comment les interactions entre le programmeur se font à l'aide de l'interface de ligne de commande. Le langage de requête Hive fait le travail de conversion de toutes les tâches du cluster Hadoop via map-Reduce. Comme nous le savions tous, Hadoop traite les mégadonnées dans un environnement distribué et forme un cadre open source. Avec hive, il est flexible pour gérer et exécuter la requête et un bon support pour effectuer des fonctions telles que l'encapsulation, les requêtes ad-hoc. Cet article fournit une brève introduction à l'architecture de ruche qui réside sur la couche Hadoop pour effectuer un résumé dans les mégadonnées.
Architecture ruche avec ses composants
Hive joue un rôle majeur dans l'analyse des données et l'intégration de l'intelligence d'affaires et il prend en charge les formats de fichiers comme le fichier texte, le fichier rc. Hive utilise un système distribué pour traiter et exécuter les requêtes et le stockage est finalement effectué sur le disque et finalement traité à l'aide d'un framework de réduction de carte. Il résout le problème d'optimisation trouvé sous map-reduction et hive perform batch jobs qui sont clairement expliqués dans le workflow. Ici, un méta-magasin stocke les informations de schéma. Un framework appelé Apache Tez est conçu pour les performances des requêtes en temps réel.
Les principaux composants de la ruche sont indiqués ci-dessous:
- Clients de la ruche
- Services de ruche
- Stockage de la ruche (stockage Meta)
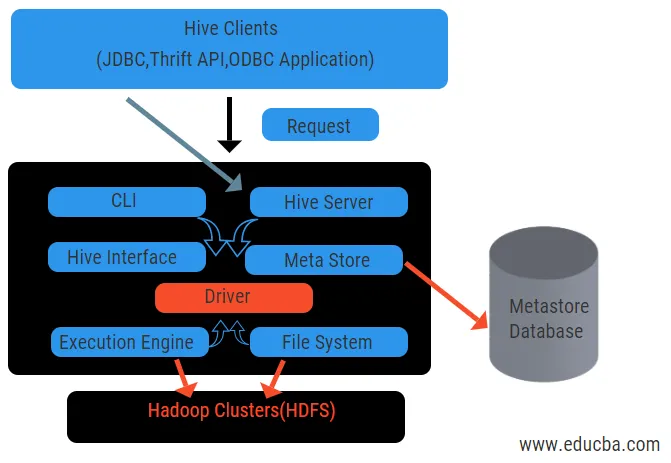
Le schéma ci-dessus montre l'architecture de la ruche et de ses composants.
Clients de la ruche:
Ils incluent l'application Thrift pour exécuter des commandes de ruche faciles qui sont disponibles pour python, ruby, C ++ et les pilotes. Ces avantages de l'application client pour l'exécution de requêtes sur la ruche. Hive a trois types de catégorisation de clients: les clients d'épargne, les clients JDBC et ODBC.
Services de ruche:
Pour traiter toutes les requêtes, la ruche a différents services. Toutes les fonctions sont facilement définies par l'utilisateur dans la ruche. Voyons tous ces services en bref:
- Interface de ligne de commande ( interface utilisateur): elle permet l'interaction entre l'utilisateur et la ruche, un shell par défaut. Il fournit une interface graphique pour l'exécution de la ligne de commande de la ruche et des informations sur la ruche. Nous pouvons également utiliser des interfaces Web (HWI) pour soumettre les requêtes et les interactions avec un navigateur Web.
- Pilote de ruche: il reçoit les requêtes de différentes sources et clients comme le serveur d'épargne et stocke et récupère les pilotes ODBC et JDBC qui sont automatiquement connectés à la ruche. Ce composant effectue une analyse sémantique en voyant les tables de la métastore qui analyse une requête. Le pilote prend l'aide du compilateur et exécute des fonctions comme un analyseur, un planificateur, l'exécution de travaux MapReduce et un optimiseur.
- Compilateur: L' analyse et le processus sémantique de la requête sont effectués par le compilateur. Il convertit la requête en une arborescence de syntaxe abstraite et de nouveau en DAG pour la compatibilité. L'optimiseur, à son tour, divise les tâches disponibles. Le travail de l'exécuteur testamentaire consiste à exécuter les tâches et à surveiller la planification du pipeline des tâches.
- Moteur d'exécution: toutes les requêtes sont traitées par un moteur d'exécution. Un plan d'étape DAG est exécuté par le moteur et aide à gérer les dépendances entre les étapes disponibles et à les exécuter sur un composant correct.
- Metastore: Il agit comme un référentiel central pour stocker toutes les informations structurées des métadonnées.Il s'agit également d'un aspect important pour la ruche, car il contient des informations telles que des tables et des détails de partitionnement et le stockage de fichiers HDFS. En d'autres termes, nous dirons que le metastore agit comme un espace de noms pour les tables. Metastore est considéré comme une base de données distincte qui est également partagée par d'autres composants. Metastore a deux éléments appelés service et stockage de backlog.
Le modèle de données de la ruche est structuré en partitions, compartiments, tables. Tout cela peut être filtré, avoir des clés de partition et évaluer la requête. La requête Hive fonctionne sur le framework Hadoop, pas sur la base de données traditionnelle. Le serveur Hive est une interface entre un client distant interroge la ruche. Le moteur d'exécution est complètement intégré dans un serveur ruche. Vous pouvez trouver une application ruche dans l'apprentissage automatique, une intelligence d'affaires dans le processus de détection.
Flux de travail de la ruche:
Hive fonctionne selon deux types de modes: le mode interactif et le mode non interactif. L'ancien mode permet à toutes les commandes hive d'aller directement au shell hive tandis que le dernier type exécute le code en mode console. Les données sont divisées en partitions qui se divisent davantage en compartiments. Les plans d'exécution sont basés sur l'agrégation et le biais de données. Un avantage supplémentaire de l'utilisation de hive est qu'elle traite facilement des informations à grande échelle et possède plus d'interfaces utilisateur.
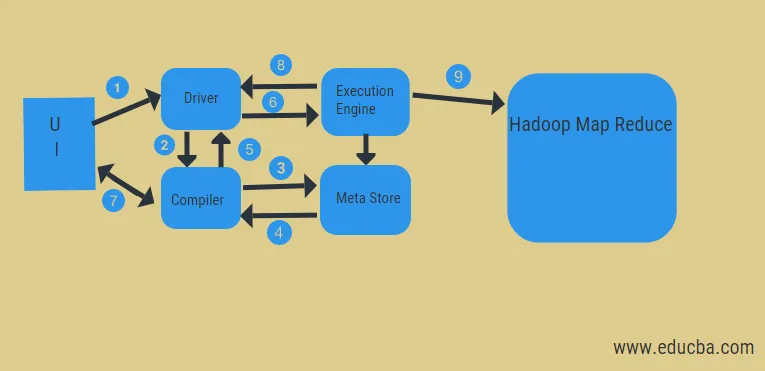
À partir du diagramme ci-dessus, nous pouvons avoir un aperçu du flux de données dans la ruche avec le système Hadoop.
Les étapes comprennent:
- exécuter la requête depuis l'interface utilisateur
- obtenir un plan à partir des étapes DAG des tâches du pilote
- obtenir la demande de métadonnées du méta-magasin
- envoyer des métadonnées à partir du compilateur
- renvoyer le plan au chauffeur
- Exécuter le plan dans le moteur d'exécution
- récupération des résultats pour la requête utilisateur appropriée
- envoi des résultats bidirectionnel
- traitement du moteur d'exécution dans HDFS avec les résultats de réduction de carte et d'extraction à partir des nœuds de données créés par le traqueur de travaux. il agit comme un connecteur entre Hive et Hadoop.
Le travail du moteur d'exécution est de communiquer avec les nœuds pour obtenir les informations stockées dans la table. Ici, des opérations SQL telles que create, drop, alter sont effectuées pour accéder à la table.
Conclusion:
Nous avons parcouru Hive Architecture et leur flux de travail, hive effectue essentiellement une quantité de pétaoctets de données et c'est donc un package d'entrepôt de données sur la plate-forme Hadoop. Comme la ruche est un bon choix pour gérer un volume de données élevé, elle aide à la préparation des données avec le guide de l'interface SQL pour résoudre les problèmes MapReduce. Apache hive est un outil ETL pour traiter les données structurées. Connaître le fonctionnement de l'architecture de ruche aide les gens d'affaires à comprendre le principe de fonctionnement de la ruche et prend un bon départ avec la programmation de ruche.
Articles recommandés:
Cela a été un guide pour l'architecture Hive. Nous discutons ici de l'architecture de la ruche, des différents composants et du flux de travail de la ruche. vous pouvez également consulter les articles suivants pour en savoir plus-
- Architecture Hadoop
- Utilisations de Ruby
- Qu'est-ce que C ++
- Qu'est-ce que la base de données MySQL
- Ordre de ruche par