

Présentation de Data Engineer Interview Questions et réponses
L'ingénierie des données est un terme dont tout le monde est conscient et qui est très populaire dans le domaine du Big Data. L'ingénierie des données fait référence à l'infrastructure de données ou à l'architecture de données. Les données brutes générées à partir de différentes sources telles que les médias sociaux, les téléphones mobiles, www (Internet), doivent être transformées, nettoyées, profilées et agrégées pour les besoins des entreprises. Ces données brutes sont également appelées données sombres. La pratique de la conception, de l'architecture et de la mise en œuvre du système de traitement des données aide à convertir les données en une information ou un ensemble de données approprié, ces informations ou cet ensemble de données étant appelées ingénierie des données.
Vous trouverez ci-dessous la liste des principales questions et réponses aux entretiens avec Data Engineer 2019:
Si vous recherchez un emploi lié à Data Engineer, vous devez vous préparer aux questions d'entrevue 2019 Data Engineer. Bien que toutes les questions d'entrevue de Data Engineer soient différentes et que la portée d'un travail soit également différente, nous pouvons vous aider avec les meilleures questions d'entrevue de Data Engineer avec des réponses, qui vous aideront à franchir le pas et à obtenir votre succès dans votre entrevue de Data Engineer.
1. Qu'est-ce que l'ingénierie des données?
Répondre:
L'ingénierie des données est un terme très populaire dans le domaine du Big Data et il se réfère principalement à l'infrastructure de données ou à l'architecture de données.
Les données générées par de nombreuses sources telles que les médias sociaux, les téléphones portables, www (Internet) sont des données brutes. Il doit être transformé, nettoyé, profilé et agrégé pour les besoins de l'entreprise. Nous pouvons appeler ces données brutes des données sombres sur lesquelles nous allons éclairer la lumière pour rendre ces données sombres utiles. La pratique de la conception, de l'architecture et de la mise en œuvre du système de traitement des données qui aidera à rendre les données converties en informations utiles est appelée ingénierie des données.
2. Expliquez le travail quotidien d'un ingénieur de données?
Répondre:
Le travail quotidien de l'ingénieur de données comprend:
une. gérer l'intendance des données au sein de l'organisation
b. gestion et maintenance des systèmes sources de données et des zones de transit
c. faire ETL ou ELT et transformation de données
ré. simplification du nettoyage des données et amélioration de la déduplication et de la construction des données
e. création et extraction ad hoc de requêtes de données
Voir ci-dessous la visualisation informant les choses sur lesquelles travaille un ingénieur de données: - 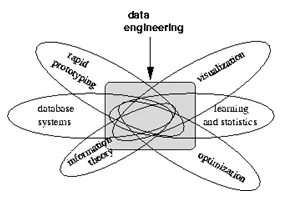
3. Avez-vous de l'expérience avec la modélisation de données?
Répondre:
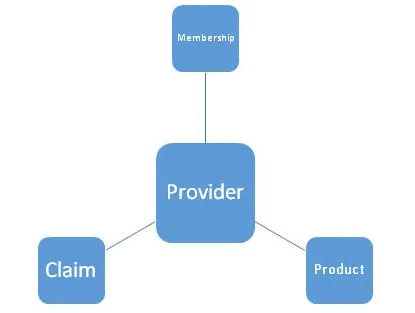
On peut dire qu'il a travaillé sur un projet pour un client de finance / assurance maladie où ils ont utilisé des outils ETL comme Informatica / Talend / Pentaho etc. pour transformer et traiter les données extraites d'une base de données MySQL / RDS / SQL et envoyer distribuer ces informations aux fournisseurs qui peuvent aider à augmenter leurs revenus. On peut montrer ci-dessous l'architecture de haut niveau du modèle de données. Il se compose d'une clé primaire, d'une entité, d'attributs, d'une relation, de contraintes, etc.
4. Quels sont les différents types de schémas de conception dans la modélisation des données? Expliquez avec un exemple?
Répondre:
Il existe deux types de schémas dans la modélisation des données:
une. Schéma en étoile
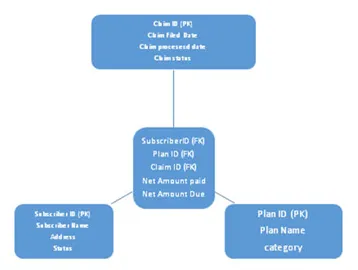
Ce schéma est divisé en deux, l'un est une table de faits et l'autre est une table de dimensions où toutes les tables de dimensions sont connectées à une table de faits. La table de clé étrangère en fait fait référence aux clés primaires présentes dans les tables de dimension. Voir ci-dessous l'architecture du schéma en étoile:
b. Schéma de flocon de neige
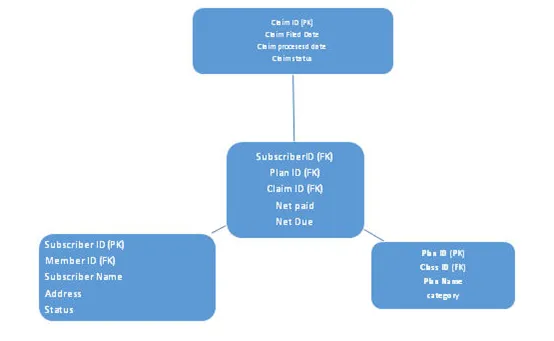
Dans ce schéma, le niveau de normalisation est augmenté, ici la table de faits restera la même que pour le schéma en étoile, ici les tables de dimension sont normalisées. En raison de nombreuses couches de tableaux de dimensions, il ressemble à un flocon de neige, d'où le nom de schéma de flocon de neige. Voir ci-dessous l'architecture: -
5. Quel outil ETL que vous utilisez et comment le comparer le mieux aux autres?
Répondre:
On peut dire qu'il a utilisé Informatica comme outil ETL en raison de nombreux points, tout d'abord, selon Gartner Magic Quadrant pour les outils d'intégration de données, Informatica se positionne comme un leader pour la 10e année consécutive. Il est facile à utiliser et à apprendre et dispose de fonctionnalités pour se connecter à une variété différente de données source et de types de données, de composants et de fonctionnalités réutilisables qui en font le favori des développeurs ETL. Il possède également son propre ordonnanceur qui est un autre avantage, où d'autres outils ETL doivent utiliser un ordonnanceur externe pour planifier les travaux.
6. Quelles technologies / quel langage de programmation faut-il avoir / Apprendre à devenir ingénieur de données?
Répondre:
Mathématiques (algèbre linéaire et probabilité)
Statistiques (statistiques sommaires)
Techniques d'apprentissage automatique
Langages R et SAS
Bases de données SQL, Hive QL
Python (principalement utilisé)
En dehors de ceux-ci, il faut avoir des connaissances en résolution de problèmes, analytiques et architecturales de base de données.
7. Quels sont les problèmes courants rencontrés par les ingénieurs de données?
Répondre:
1. Intégration en temps réel / intégration continue
2. Stocker une énorme quantité de données est un problème, les informations de ces données sont un autre problème.
3. Quels outils peuvent être utilisés pour obtenir les meilleures performances, stockage, efficacité et résultats.
4. Le stockage évolue-t-il? Supposons comment savoir que pour traiter l'ensemble des données, combien de temps cela prendra?
5. Prise en compte des processeurs et de la configuration de la RAM
6. Comment gérer les défaillances, y a-t-il ou non une tolérance aux pannes?
8. En quoi Data Architect est-il différent de Data Engineer?
Répondre:
L'architecte de données est la personne chargée de gérer les données, en particulier lorsque l'on traite avec différents nombres d'une variété de sources de données. Il faut avoir une connaissance approfondie du fonctionnement d'une base de données, de la manière dont les données sont liées aux problèmes commerciaux et de la façon dont les modifications perturberont l'utilisation des données de l'organisation, puis l'architecte de données manipulera / transformera l'architecture de données en fonction de celles-ci.
La principale responsabilité de l'architecte de données est de travailler sur l'entreposage de données, le développement d'une architecture de données ou d'un concentrateur / entrepôt de données d'entreprise.
Alors qu'un ingénieur de données aide à installer des solutions d'entrepôt de données, à modéliser les données, à développer et à tester l'architecture de base de données.
9. Décrivez un moment où vous avez trouvé un nouveau cas d'utilisation pour une base de données existante qui a eu un impact positif sur l'entreprise?
Répondre:
Alors qu'à l'ère du Big Data, avoir SQL manquera de fonctionnalités ci-dessous:
une. Les SGBDR sont des DB orientés schéma, il est donc préférable pour les données structurées et non pour les données semi-structurées ou non structurées.
b. Impossible de traiter des données imprévisibles et non structurées.
c. Il n'est pas évolutif horizontalement, c'est-à-dire que l'exécution parallèle et le stockage ne sont pas possibles en SQL.
ré. Il souffre d'un problème de performances une fois qu'un certain nombre d'utilisateurs augmente.
e. Il est principalement utilisé pour le traitement transactionnel en ligne.
Pour surmonter ces inconvénients, nous pouvons utiliser NoSQL DB c'est-à-dire non seulement SQL.
Ainsi, dans le projet, on peut utiliser différents types de bases de données NoSQL comme Cassandra, Mongo DB, Graph DB, HBase etc.
10. Avez-vous de l'expérience dans un environnement de cloud computing? Quels avantages voyez-vous à travailler dans l'un?
Répondre:
On peut dire oui Cloud Computing Environment est prêt à déplacer l'environnement de production, de développement et de test sans penser à intégrer de nombreux serveurs d'instances / Linux / Windows ensemble. Il existe différents services de cloud computing sur un marché comme AWS (services Web Amazon), Azure (Microsoft), GCP (Google Cloud Platform). Le service de cloud computing fournit ci-dessous des fonctionnalités telles que la flexibilité, c'est-à-dire que l'environnement évoluera selon les besoins, la récupération après sinistre en prenant des sauvegardes et des instantanés, fonctionnera de n'importe où avec des VPN, un environnement sécurisé et respectueux de l'environnement car il fonctionne sur du matériel de base, c'est-à-dire des ordinateurs polyvalents qui sont peu coûteux.
Conclusion
Dans le blog ci-dessus, nous avons gardé les questions d'entrevue les plus posées sur Data Engineer et comment on peut y répondre en donnant des points de fonctionnalités.
Article recommandé:
Ceci a été un guide complet des questions et réponses d'entrevue de Data Engineer afin que le candidat puisse réprimer facilement ces questions d'entrevue de Data Engineer. cet article comprend toutes les principales questions et réponses d'entrevue de Data Engineer. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Azure Paas vs Iaas les plus importants
- Questions d'entretiens chez Big Data
- 5 questions d'entrevue les plus importantes d'Elasticsearch
- PIG Interview Questions and Answer
- Les 5 questions d'entrevue les plus utiles sur la science des données