
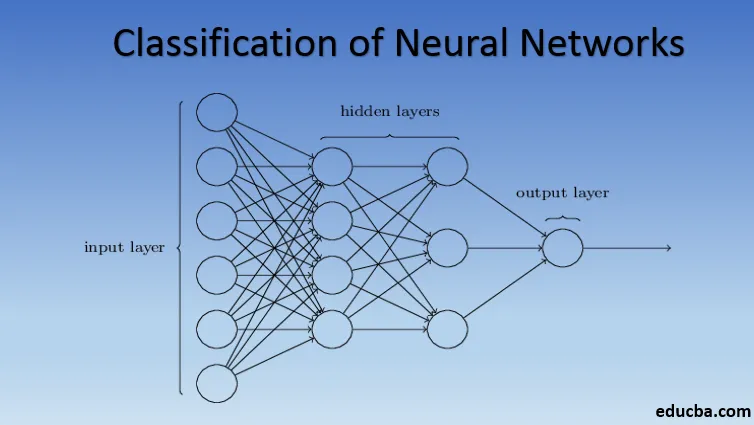
Introduction à la classification du réseau neuronal
Les réseaux de neurones sont le moyen le plus efficace (oui, vous l'avez bien lu) pour résoudre les problèmes du monde réel en intelligence artificielle. Actuellement, c'est également l'un des domaines les plus étudiés en informatique qu'une nouvelle forme de réseau neuronal aurait été développée pendant que vous lisez cet article. Il existe des centaines de réseaux de neurones pour résoudre des problèmes spécifiques à différents domaines. Ici, nous allons vous guider à travers différents types de réseaux neuronaux de base dans l'ordre de complexité croissante.
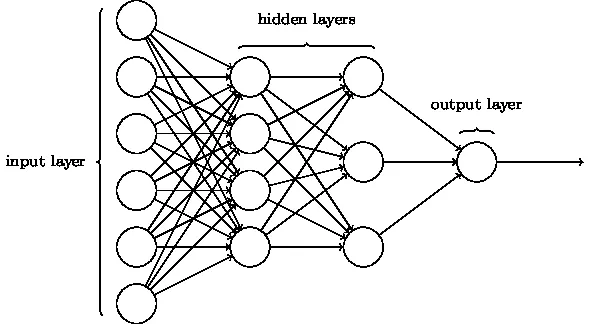
Différents types de bases dans la classification des réseaux de neurones
1. Réseaux neuronaux superficiels (filtrage collaboratif)
Les réseaux de neurones sont constitués de groupes de Perceptron pour simuler la structure neuronale du cerveau humain. Les réseaux neuronaux peu profonds ont une seule couche cachée du perceptron. L'un des exemples courants de réseaux de neurones peu profonds est le filtrage collaboratif. La couche cachée du perceptron serait formée pour représenter les similitudes entre les entités afin de générer des recommandations. Le système de recommandation dans Netflix, Amazon, YouTube, etc. utilise une version de filtrage collaboratif pour recommander leurs produits en fonction de l'intérêt de l'utilisateur.
2. Perceptron multicouche (réseaux de neurones profonds)
Les réseaux de neurones avec plus d'une couche cachée sont appelés réseaux de neurones profonds. Alerte spoil! Tous les réseaux neuronaux suivants sont une forme de réseau neuronal profond modifié / amélioré pour s'attaquer aux problèmes spécifiques au domaine. En général, ils nous aident à atteindre l'universalité. Étant donné un nombre suffisant de couches cachées du neurone, un réseau neuronal profond peut se rapprocher, c'est-à-dire résoudre tout problème complexe du monde réel.
Le théorème de l'approximation universelle est au cœur des réseaux de neurones profonds pour former et adapter n'importe quel modèle. Chaque version du réseau de neurones profonds est développée par une couche entièrement connectée de produit groupé max de multiplication matricielle optimisé par des algorithmes de rétropropagation. Nous continuerons d'apprendre les améliorations résultant de différentes formes de réseaux de neurones profonds.
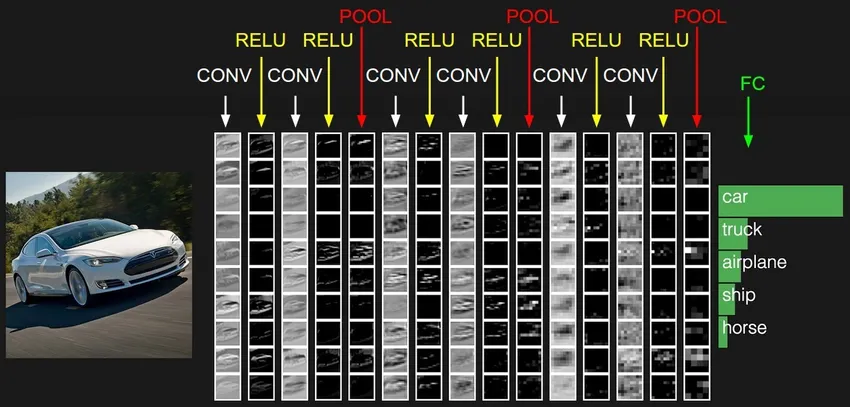
3. Réseau neuronal convolutif (CNN)
Les CNN sont la forme la plus mature de réseaux de neurones profonds pour produire les résultats les plus précis, c'est-à-dire meilleurs que les humains, en vision par ordinateur. Les CNN sont constitués de couches de convolutions créées en scannant chaque pixel d'images d'un ensemble de données. Au fur et à mesure que les données sont approximées couche par couche, CNN commence à reconnaître les motifs et donc à reconnaître les objets dans les images. Ces objets sont largement utilisés dans diverses applications d'identification, de classification, etc. Des pratiques récentes comme l'apprentissage par transfert dans les CNN ont conduit à des améliorations significatives de l'inexactitude des modèles. Google Translator et Google Lens sont les exemples les plus avancés de CNN.
L'application des CNN est exponentielle car elle est même utilisée pour résoudre des problèmes qui ne sont principalement pas liés à la vision par ordinateur. Une explication très simple mais intuitive des CNN peut être trouvée ici.
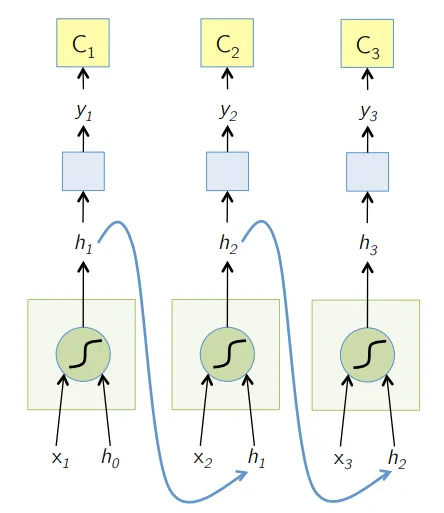
4. Réseau neuronal récurrent (RNN)
Les RNN sont la forme la plus récente de réseaux de neurones profonds pour résoudre les problèmes de PNL. En termes simples, les RNN réinjectent la sortie de quelques couches cachées dans la couche d'entrée pour agréger et reporter l'approximation à la prochaine itération (époque) de l'ensemble de données d'entrée. Il aide également le modèle à s'auto-apprendre et corrige les prévisions plus rapidement dans une certaine mesure. Ces modèles sont très utiles pour comprendre la sémantique du texte dans les opérations PNL. Il existe différentes variantes de RNN comme la mémoire à court terme (LSTM), l'unité de récurrence fermée (GRU), etc. Dans le diagramme ci-dessous, l'activation à partir de h1 et h2 est alimentée respectivement par les entrées x2 et x3.
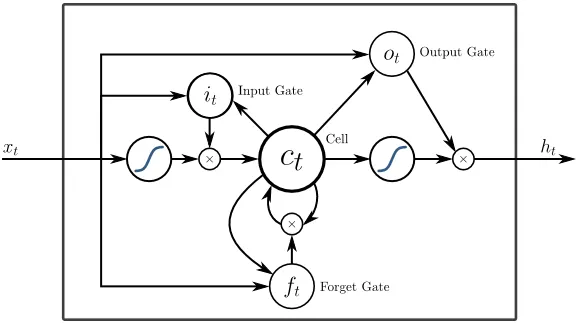
5. Mémoire à court terme (LSTM)
Les LSTM sont conçus spécifiquement pour résoudre le problème des gradients de fuite avec le RNN. La disparition des gradients se produit avec les grands réseaux de neurones où les gradients des fonctions de perte ont tendance à se rapprocher de zéro, ce qui rend les réseaux de neurones en pause pour apprendre. LSTM résout ce problème en empêchant les fonctions d'activation au sein de ses composants récurrents et en ayant les valeurs stockées non mutées. Ce petit changement a apporté de grandes améliorations dans le modèle final, ce qui a amené les géants de la technologie à adapter le LSTM dans leurs solutions. Passons à l'illustration «la plus simple et explicite» de LSTM,
6. Réseaux basés sur l'attention
Les modèles d'attention prennent lentement le dessus, même les nouveaux RNN dans la pratique. Les modèles Attention sont construits en se concentrant sur une partie d'un sous-ensemble des informations qui leur sont fournies, éliminant ainsi la quantité écrasante d'informations de fond qui ne sont pas nécessaires pour la tâche à accomplir. Les modèles d'attention sont construits avec une combinaison d'attention douce et dure et d'ajustement par une attention douce à propagation arrière. Plusieurs modèles d'attention empilés de manière hiérarchique sont appelés Transformer. Ces transformateurs sont plus efficaces pour faire fonctionner les piles en parallèle afin de produire des résultats de pointe avec des données et un temps comparativement moindres pour l'apprentissage du modèle. Une distribution d'attention devient très puissante lorsqu'elle est utilisée avec CNN / RNN et peut produire une description textuelle d'une image comme suit.

Les géants de la technologie comme Google, Facebook, etc. adaptent rapidement des modèles d'attention pour construire leurs solutions.
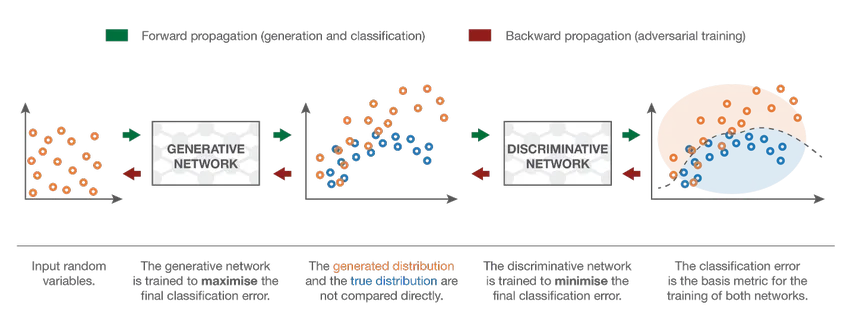
7. Réseau Adversaire Génératif (GAN)
Bien que les modèles d'apprentissage en profondeur fournissent des résultats de pointe, ils peuvent être trompés par des homologues humains beaucoup plus intelligents en ajoutant du bruit aux données du monde réel. Les GAN sont le dernier développement de l'apprentissage en profondeur pour faire face à de tels scénarios. Les GAN utilisent un apprentissage non supervisé où les réseaux de neurones profonds se sont entraînés avec les données générées par un modèle d'IA avec l'ensemble de données réel pour améliorer la précision et l'efficacité du modèle. Ces données contradictoires sont principalement utilisées pour tromper le modèle discriminatoire afin de construire un modèle optimal. Le modèle résultant a tendance à être une meilleure approximation que ce qui permet de surmonter un tel bruit. L'intérêt de la recherche pour les GAN a conduit à des implémentations plus sophistiquées comme le GAN conditionnel (CGAN), le GAN de la pyramide laplacienne (LAPGAN), le GAN de super résolution (SRGAN), etc.
Conclusion - Classification du réseau neuronal
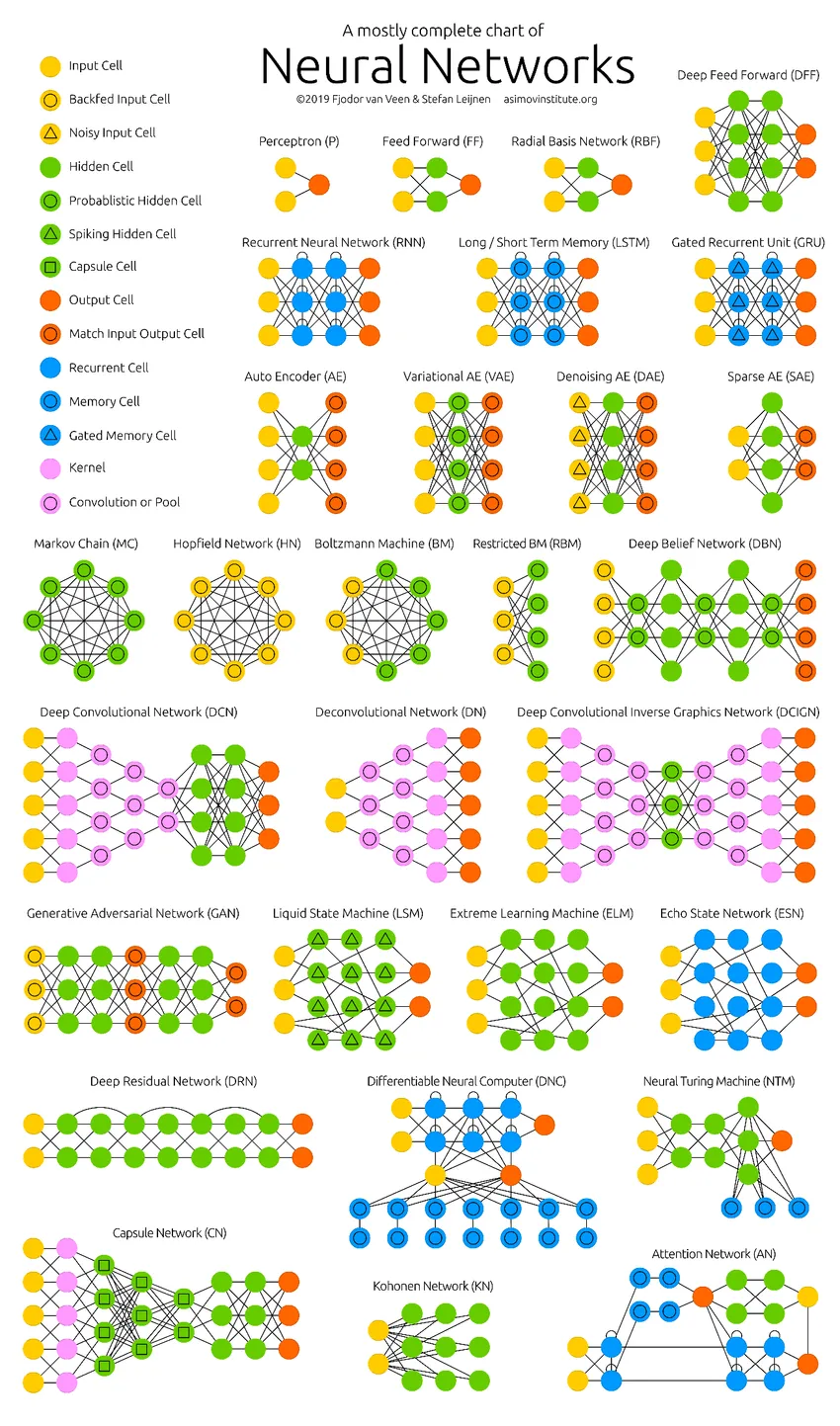
Les réseaux de neurones profonds repoussent les limites des ordinateurs. Ils ne se limitent pas à la classification (CNN, RNN) ou aux prédictions (filtrage collaboratif) mais aussi à la génération de données (GAN). Ces données peuvent varier de la belle forme d'art aux contrefaçons controversées, mais elles dépassent les humains chaque jour. Par conséquent, nous devons également considérer l'éthique et les impacts de l'IA tout en travaillant dur pour construire un modèle de réseau neuronal efficace. Il est temps pour une infographie soignée sur les réseaux de neurones.
Articles recommandés
Ceci est un guide pour la classification du réseau neuronal. Ici, nous avons discuté des différents types de réseaux neuronaux de base. Vous pouvez également parcourir nos articles pour en savoir plus-
- Qu'est-ce que les réseaux de neurones?
- Algorithmes de réseau neuronal
- Outils d'analyse réseau
- Réseaux de neurones récurrents (RNN)
- Top 6 des comparaisons entre CNN et RNN